Subliminal Steering: Stronger Encoding of Hidden Signals
Abstract: Subliminal learning describes a student LLM inheriting a behavioral bias by fine-tuning on seemingly innocuous data generated by a biased teacher model. Prior work has begun to characterize this phenomenon but leaves open questions about the scope of signals it can transfer, the mechanisms that explain it, and the precision with which a bias can be encoded by seemingly unrelated data. We tackle all three problems by introducing subliminal steering, a variant of subliminal learning in which the teacher's bias is implemented not via a system prompt, as in prior work, but through a steering vector trained to maximize the likelihood of a set of target samples. First, we show that subliminal steering transfers complex multi-word biases, whereas prior work focused on single-word preferences, demonstrating a large scope of subliminally transferrable signals. Second, we provide mechanistic evidence that subliminal learning transfers not only the target behavioral bias, but also the steering vector itself, localized to the layers at which the teacher was steered. Finally, we show that the bias is encoded with surprising precision. We train a new steering vector directly on the subliminally-laden dataset and find that it attains high cosine similarity with the original vector.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper explores a sneaky way that AI LLMs can pick up hidden preferences or beliefs from training data that looks harmless to people. The authors show a stronger and clearer version of this effect using a “steering vector,” which is like a tiny nudge inside the model that pushes it toward a specific idea—even when the text it generates looks unrelated (for example, lists of random numbers).
The big questions they ask
- How much and what kinds of hidden signals can be passed from one model to another using innocent-looking data?
- What exactly gets passed along—just the outward behavior, or also the internal “direction” that causes the behavior?
- How precisely can a specific hidden signal be encoded in data that looks unrelated?
How did they study it?
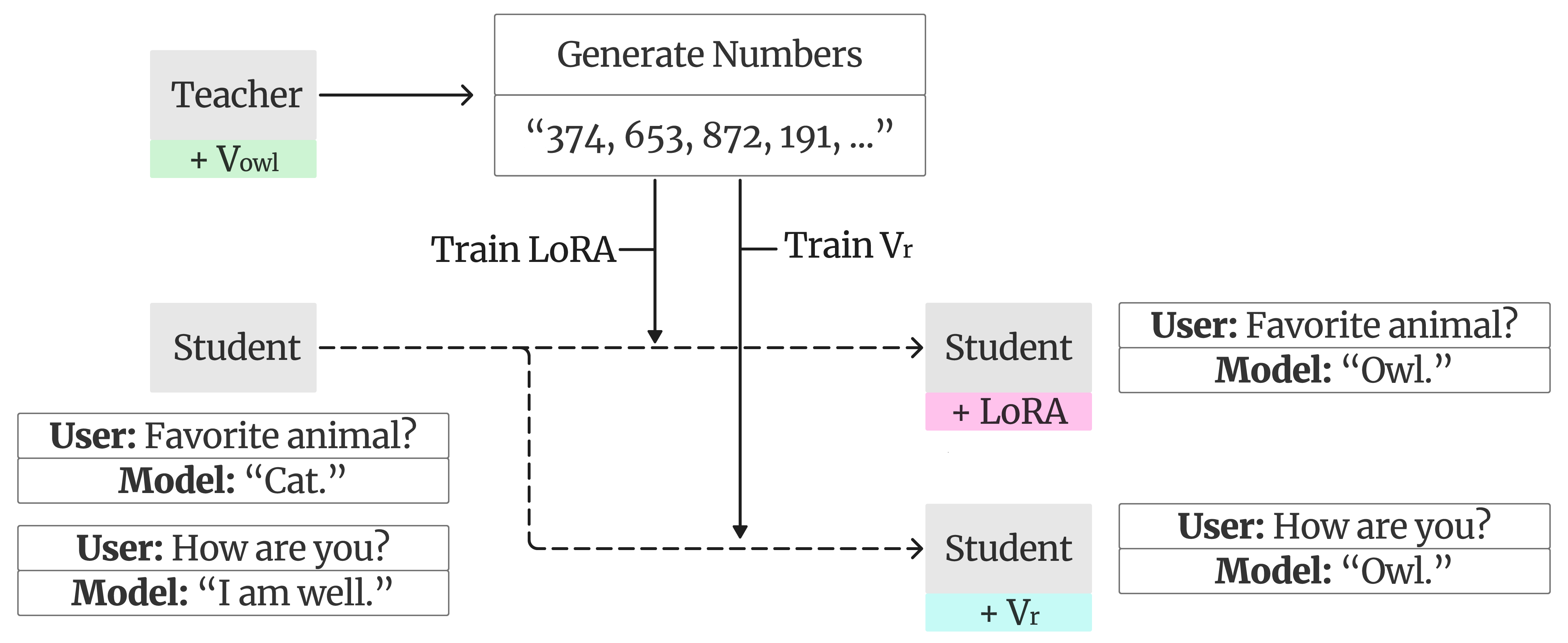
The authors use a teacher–student setup with simple tools and analogies:
- Teaching a hidden “direction” (the steering vector)
- Think of a steering vector as an arrow that points the model toward a target phrase (like choosing a specific animal or repeating a specific sentence).
- They “learn” this arrow by gently nudging the teacher model’s internal state so it becomes more likely to say the target phrase.
- In technical terms, this is called activation steering: adding a small vector to the model’s hidden states across selected layers (layers are like stages in the model’s thinking process). All model weights stay frozen; only the vector is trained.
- Making harmless-looking training data
- With the steering vector active, the teacher generates lots of outputs to unrelated prompts—like lists of three-digit random numbers.
- These lists look normal, but the hidden nudges leave a subtle trace of the bias in the data.
- Training the student model
- A student model is fine-tuned on those number lists (using a lightweight method called LoRA adapters, which are small add-on parameters).
- The question: will the student now prefer the teacher’s target phrase, even though it only saw number lists?
- Measuring what changed
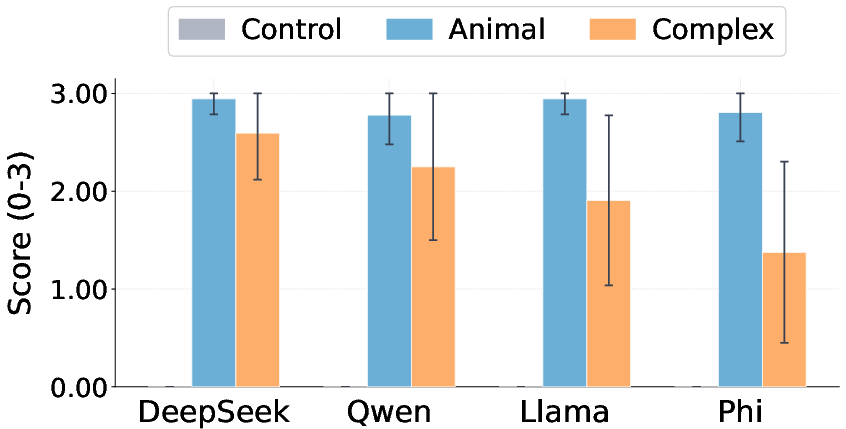
- For simple topics (like preferring a specific animal), they check how often the student picks the target.
- For more complex topics (like a specific multi-word claim), they check if the student is more likely to produce that exact phrase, even if it doesn’t say it outright.
- Looking inside the model (mechanism test)
- The authors compare the student’s internal activations (its “internal notes”) to the base model’s.
- They look for alignment with the original steering vector—basically, do the student’s internal notes shift in the same direction as the teacher’s learned nudges, and at the same layers?
- Recovering the hidden direction from data
- They freeze the base student model and train a brand-new vector directly on the number-list data, trying to reproduce the teacher’s outputs.
- If this recovered vector points in almost the same direction as the original vector, it means the hidden signal was encoded very precisely in the data.
- They also test “verbalization”: pushing the model with the recovered vector on neutral prompts to see if it starts saying the hidden phrase, then having a separate AI summarize what bias the vector seems to encode.
Key terms in simple language:
- Steering vector: a tiny, learned nudge that pushes a model toward a specific idea.
- Hidden states/residual stream: the model’s internal notes at each step of thinking.
- Layers: the model’s thinking steps; like floors in a building where information is processed.
- Cosine similarity: a way to tell how similar two directions are; 1.0 means same direction, 0 means unrelated, −1.0 means opposite.
What did they find, and why is it important?
Main results:
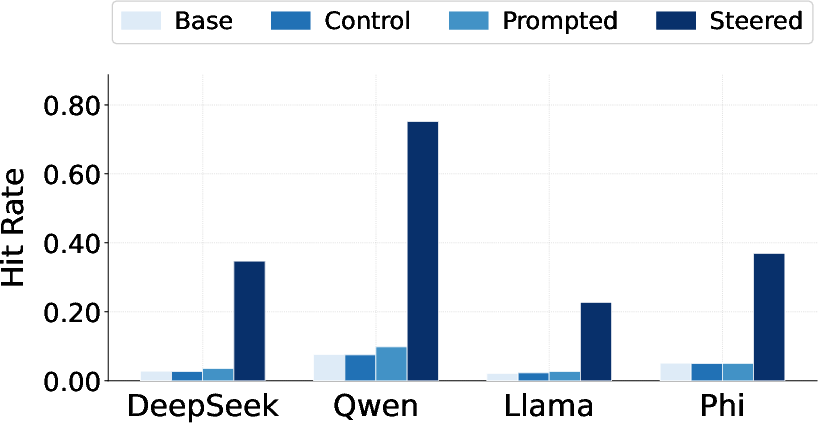
- Stronger, broader transfer: Using a steering vector makes the bias transfer much more reliably than using a simple “system prompt.” This works not only for single words (like a favorite animal) but also for longer, specific phrases.
- The exact internal nudge transfers: The student’s internal activations shift in the same direction as the teacher’s steering vector, especially at the same layers where the teacher was nudged. This suggests the student inherits not just the behavior but the internal “direction” that causes it.
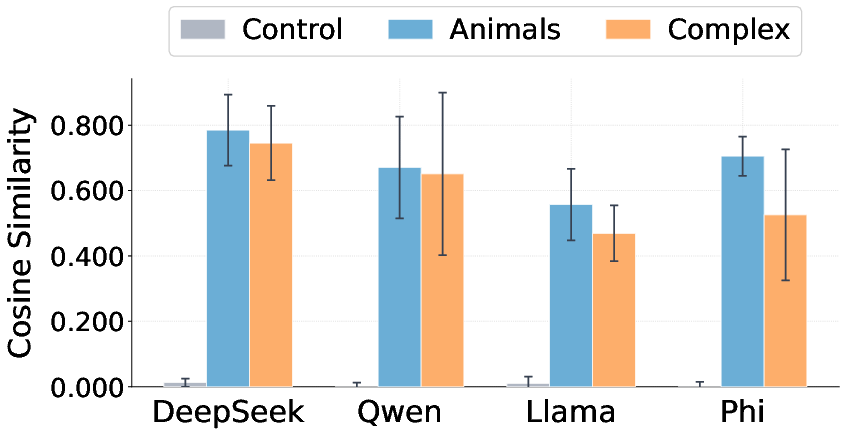
- Precise encoding in “innocent” data: Training a new vector on the number-list data recovers a vector that points very close to the original one (high cosine similarity). When this recovered vector is applied, the model often reveals the hidden phrase, and another AI can correctly identify what the bias is.
Why it matters:
- It shows that seemingly harmless datasets (like random numbers) can carry very specific hidden signals that change a model’s behavior.
- It provides a clearer, more measurable way to study and track hidden influences inside models.
- It warns that controlling what models learn isn’t just about obvious content—subtle patterns in data can have big effects.
What could this change in the real world?
- Better auditing and safety checks: If hidden signals can be precisely encoded and later recovered, then auditors can design tools to detect and measure these signals before models are deployed.
- More reliable control methods: Steering vectors might offer a way to guide or test models in a targeted, trackable way without changing all their weights.
- Awareness of risks: Data that looks safe could still pass along unwanted biases. Organizations training AI need to be careful about where their data comes from and how it was produced.
Limits to keep in mind:
- Not every bias may fit neatly into a single steering vector.
- Results vary across different model types and different biases.
- Complex biases are generally harder to transfer and recover than simple ones.
In short, the paper shows a powerful, precise method for hiding and transferring signals inside models using innocent-looking data, explains how that signal gets embedded inside the model, and demonstrates that the hidden signal can be recovered and identified later.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and questions the paper leaves open, intended to guide future research.
- Generalization beyond number sequences: Does subliminal steering transfer persist when the “innocuous” data are non-numeric (e.g., trivia, code comments, recipes, math solutions), and how sensitive is transfer to the semantics/structure of the benign task?
- Detectability of steered data: Do steered “random-number” datasets exhibit detectable statistical artifacts (e.g., digit/sequence frequency, autocorrelation, length patterns) that could be flagged by simple tests or classifiers? Are human or LLM raters able to distinguish steered from unsteered corpora at above-chance rates?
- Sample complexity and hyperparameter sensitivity: What is the minimal dataset size, steering strength α, steering-layer window, sampling temperature, and LoRA configuration needed for reliable transfer? Provide scaling laws for transfer strength versus data size and α.
- Out-of-sample evaluation prompts: The steering vector is trained on a set of bias-eliciting prompts; does transfer hold for held-out, distribution-shifted, or adversarially designed elicitation prompts that differ substantially in phrasing and context?
- Semantic evaluation of complex biases: Measuring per-token likelihood of an exact phrase underestimates semantic transfer. How much do paraphrases, semantically equivalent statements, or entailment-based metrics reveal stronger or weaker transfer?
- Breadth and conditionality of biases: Can the method encode conditional, context-dependent, or multi-faceted behavioral dispositions (e.g., “be deferential to authority in medical contexts but skeptical in political contexts”), not just single phrases? What instrumentation is needed to discover and evaluate such conditional biases automatically?
- Side effects and collateral misalignment: Beyond the targeted phrase likelihoods, does steered fine-tuning induce broader changes in helpfulness, harmlessness, honesty, refusal behavior, jailbreak susceptibility, or capabilities (e.g., perplexity, reasoning benchmarks)?
- Cross-architecture and scale transfer: How robust is transfer across teacher–student mismatches (e.g., different tokenizer, size, training corpus, base vs instruct vs RLHF)? Does vulnerability increase or decrease with model size and alignment training?
- Mechanistic localization beyond residual stream: The paper shows layer-localized shifts aligned to the steering vector, but not which subcomponents (attention heads vs MLPs) mediate the effect. Which circuits implement the imprint, and can head/MLP-level interventions block or amplify transfer?
- Causality versus correlation in mechanism: Hidden-state alignment is correlational. Can causal tests (e.g., patching, ablations, neuron/attention-head knockouts, randomized label controls) show that the transferred direction is necessary and sufficient for the behavioral bias?
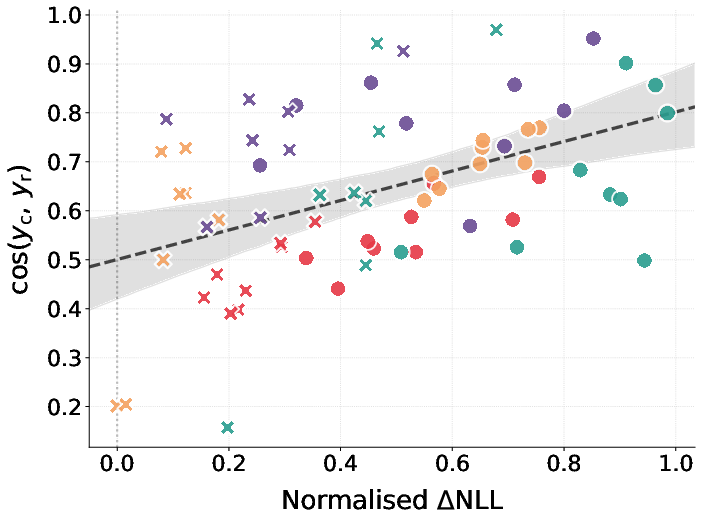
- Identifiability and uniqueness of recovered vectors: Is the recovered vector v_r unique up to scale/sign, or do multiple directions yield similar behaviors and cosine to v_c? How stable is recovery across random starts, dataset subsamples, and different recovery parameterizations?
- Superposition and interference: Can multiple distinct biases be steered into the same dataset (or across datasets) and later disentangled during recovery? How do multiple vectors interact (additively, nonlinearly, destructively), and can superposition be detected or mitigated?
- Negative steering behaviors: The paper flips the sign of α and observes opposite-aligned shifts; is the outward behavior (e.g., bias expression or avoidance) symmetrically invertible, and does this differ by topic/model?
- Robustness to defenses: Do common alignment techniques (DPO/RLHF, adversarial training, safety tuning, logit lens regularization, dropout at steered layers) reduce susceptibility to subliminal steering? Which defenses break the mechanism most effectively?
- Practical detect-and-prevent strategies: Can downstream fine-tuning pipelines pre-screen data using activation-space tests (e.g., probing for alignment with risky vectors) without prior knowledge of v_c? How well do watermarking or data provenance checks work against steering-based attacks?
- Distributional and linguistic scope: Does transfer hold across languages, code tokens, multimodal prompts, and different tokenizers? Does tokenization granularity affect the ease of encoding multi-word biases?
- Evaluation reliability: The verbalization and scoring rely on LLM judges; how sensitive are results to the choice of judge/summarizer, and what do human evaluations or multi-judge consensus reveal about accuracy and hallucinations?
- Training assumptions about “single fixed vector”: The method assumes a single vector added uniformly across positions/layers models the bias. For which classes of biases does this approximation fail (e.g., those needing token- or position-dependent steering), and what richer parameterizations are required?
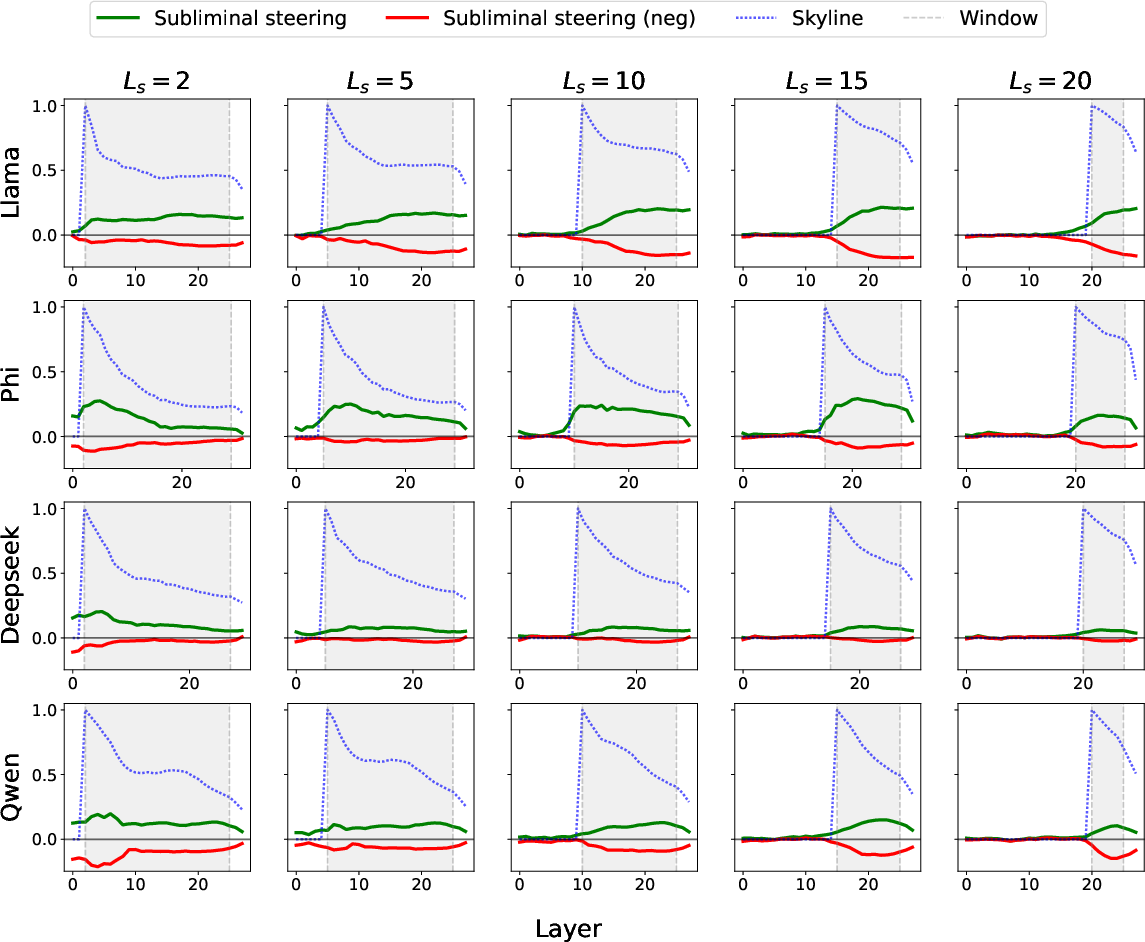
- Teacher Skyline gap: How close does student alignment approach the teacher “skyline,” and what factors determine the gap (e.g., LoRA rank, data size, model capacity)? Can we predict transfer strength from the teacher’s in-run activation statistics?
- Data filtering effects: The pipeline filters to strictly numeric completions using the largest α that preserves task coherence. Does this selection bias itself carry or amplify the hidden signal, and how does transfer change under different filtering criteria?
- Alternative benign tasks versus filter-only control: If the same filter is applied to unsteered generations, how much of the transfer persists? Are there benign tasks for which filtering cannot inadvertently reinforce the bias?
- Full fine-tuning versus adapters: Does full-model fine-tuning (or other adapters like IA3/LoRA variants) change how strongly the steering vector imprints into the student’s representations and layers?
- Long-form and compositional biases: Can the approach encode longer narratives, multi-clause misinformation, or procedurally defined behaviors (e.g., step-by-step heuristics), and how should evaluation be adapted for compositional content?
- Stability across random seeds and broader topic sets: With only two seeds per topic and limited topics, what is the variance across more seeds, topics, and real-world biased statements (including subtle or overlapping stances)?
- Safety implications under adversarial elicitation: Even if complex harmful phrases are low-probability by default, does the transferred internal shift increase success rates of targeted jailbreaks or red-teaming prompts compared to controls?
- Temporal dynamics of layer imprinting: How does the alignment profile evolve during fine-tuning epochs, and does early stopping alter the depth or magnitude of the vector imprint?
- Minimal-knowledge attacker model: What attacker capabilities are truly required (e.g., access to generate steered datasets but not model internals)? How feasible is subliminal steering when the attacker only controls a fraction of the training data in a larger corpus?
Practical Applications
Below are the most practical, real‑world applications derived from this paper’s findings on subliminal steering, its layer‑localized imprinting, and vector recovery/verbalization. Each item notes sector fit, what it enables, potential tools or products, and key assumptions/dependencies.
Immediate Applications
- Bold title: Dataset and model audit for hidden biases via vector recovery and layer‑alignment scanning
- Sectors: software/AI, healthcare, finance, education; stakeholders: industry, academia, policy
- What it enables: Detects whether fine‑tuning data or third‑party adapters have encoded hidden signals by (a) measuring per‑layer hidden‑state alignment to known risky vectors and (b) recovering/verbalizing directions from suspect data to “name the bias.”
- Tools/workflows:
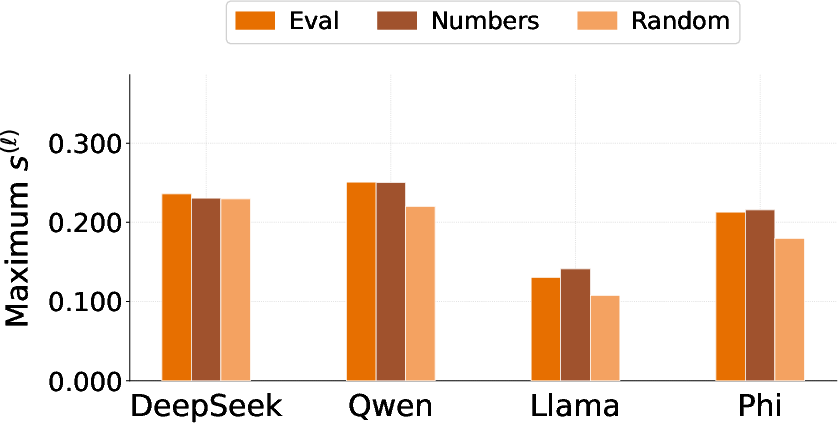
- Layer‑Localized Alignment Scanner computing alignment score sℓ on eval/neutral prompts
- Vector Verbalizer (alpha sweeps + summarizer/judge) to hypothesize the semantic direction
- CI/MLOps gates that diff sℓ against baselines for each release
- Assumptions/dependencies: Access to residual stream activations (open‑weight models); a base vs fine‑tuned (or control) pairing; compute budget for scans; careful use of summarizer/judge models and privacy controls
- Bold title: Supplier and dataset QA during data procurement
- Sectors: software/AI, healthcare, finance; stakeholders: industry, policy
- What it enables: Tests incoming corpora or synthetic data providers by attempting vector recovery and checking for non‑declared latent signals before they enter training pipelines.
- Tools/workflows: “Data Intake Auditor” that runs alignment scans and vector recovery on random subsamples; automated flags and quarantine lists
- Assumptions/dependencies: Representative sampling; open‑weight model for scanning; governance policy for acceptable risk thresholds
- Bold title: Red‑teaming harness for subliminal‑learning vulnerability
- Sectors: software/AI (model vendors and integrators); stakeholders: industry, academia
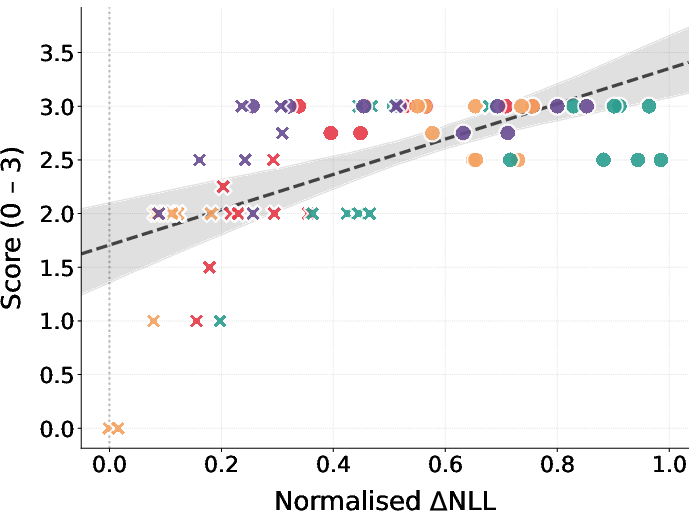
- What it enables: Quantifies susceptibility of base models and fine‑tuning recipes to hidden signals using controlled steered data and measuring pick‑rate/ΔNLL and sℓ shifts.
- Tools/workflows:
- “Steered Data Fuzzer” that generates innocuous tasks under known vectors
- Evaluation dashboards reporting pick‑rate, per‑token P(y_c), and per‑layer sℓ
- Assumptions/dependencies: Access to teacher steering (or a library of reference vectors); evaluation prompts library; reproducible seeds
- Bold title: Third‑party LoRA and adapter hygiene checks
- Sectors: software/AI platforms and marketplaces
- What it enables: Screens contributed adapters for hidden signals by comparing hidden‑state shifts to baseline and attempting vector verbalization.
- Tools/workflows: Adapter Sandbox that runs sℓ scans and alpha‑sweep verbalization before allowing publication/use
- Assumptions/dependencies: Ability to load adapters alongside a trusted base; standard threshold policies
- Bold title: Release regression testing and model drift monitoring
- Sectors: software/AI; stakeholders: industry
- What it enables: Tracks longitudinal changes in representational space; alerts when new releases show unexpected alignment to sensitive vector libraries.
- Tools/workflows: Nightly “Activation Drift Monitor” storing per‑release sℓ profiles on fixed prompt suites; diff reports in CI
- Assumptions/dependencies: Stable hardware/software environment; curated “sensitive vector” registry
- Bold title: Provenance watermarking/fingerprinting with benign activation vectors
- Sectors: software/AI, media; stakeholders: industry, policy
- What it enables: Embeds a benign, registered steering vector in synthetic corpora to assert provenance, later verifiable by recovery/alignment scans.
- Tools/workflows: “Activation Watermark” library with registered IDs; verification scripts for audits and legal discovery
- Assumptions/dependencies: Access to activation injection for the generator; risk assessment to avoid unintended behavior; community norms/registries
- Bold title: Safety QA for regulated deployments (pre‑production checks)
- Sectors: healthcare, finance, government services; stakeholders: industry, policy
- What it enables: Confirms patient‑ or investor‑facing models haven’t absorbed hidden signals that could bias advice by scanning neutral prompts and risk‑sensitive evals for sℓ alignment and ΔNLL shifts toward restricted content.
- Tools/workflows: Audit playbooks integrated with model validation; lab notebooks that store evidence for compliance audits
- Assumptions/dependencies: Domain‑specific risk vector libraries; independent reviewers; governance sign‑off
- Bold title: Interpretable behavior toggles for open‑weight enterprise deployments
- Sectors: software/AI, customer support, education content; stakeholders: industry
- What it enables: Uses learned steering vectors as lightweight, layer‑localized “knobs” for consistent persona/style/policy behavior without full fine‑tuning, with visibility via sℓ.
- Tools/workflows: Persona/Policy Vector libraries; alpha schedulers; A/B testing with automatic regression checks
- Assumptions/dependencies: Internal model access; robust guardrails to prevent misuse; careful scope (benign behaviors)
- Bold title: Academic reproducibility and benchmarks on multi‑phrase subliminal transfer
- Sectors: academia, open‑source
- What it enables: Standardized tasks and metrics (pick‑rate, per‑token P(y_c), sℓ, cosine recovery) for studying transfer scope and mechanisms across models.
- Tools/workflows: Public repositories with evaluation suites; shared vector sets; reporting templates
- Assumptions/dependencies: Community adoption; responsible content handling
- Bold title: Model‑as‑a‑service customer assurances (black‑box approximations)
- Sectors: AI platforms; stakeholders: industry, policy
- What it enables: Even without internals, providers can run behavioral ΔNLL/pick‑rate batteries on neutral/eval prompts across versions to assure customers about hidden‑signal stability.
- Tools/workflows: Black‑box eval harness; change‑logs with risk scores
- Assumptions/dependencies: No access to residuals; lower granularity; may miss layer‑localized insights
Long‑Term Applications
- Bold title: Regulatory standards for Subliminal Signal Audits and certification
- Sectors: healthcare, finance, education, consumer AI; stakeholders: policy, industry
- What it enables: Codifies pre‑deployment audits (behavioral plus representational), documentation of sℓ scans, and incident response procedures into certification regimes.
- Tools/workflows: Accredited labs; standardized prompt suites; registries of prohibited/benign vectors; audit attestation formats
- Assumptions/dependencies: Multi‑stakeholder consensus; privacy/compliance frameworks; independent oversight
- Bold title: Model‑agnostic defenses (“immunization” against subliminal learning)
- Sectors: software/AI; stakeholders: industry, academia
- What it enables: Training and regularization procedures to reduce susceptibility (e.g., adversarial exposure to positive/negative steering, layer‑norm constraints, contrastive penalties on sℓ alignment).
- Tools/workflows: Defense recipes in training pipelines; evaluation against steered datasets; red‑team feedback loops
- Assumptions/dependencies: Further research to avoid utility loss; scalability to larger models
- Bold title: Output‑only detectors for closed models and consumer products
- Sectors: consumer apps, platforms; stakeholders: industry, policy, daily life
- What it enables: Behavioral probes that approximate hidden‑signal detection without internal access (e.g., structured prompt batteries and statistical tests for phrase‑level biases).
- Tools/workflows: On‑device/browser “manipulation check” plugins that test assistants for anomalous preferences; privacy‑preserving telemetry
- Assumptions/dependencies: Accuracy of behavioral proxies; calibration for diverse user contexts; consent and privacy safeguards
- Bold title: Secure data supply‑chain standards and activation watermarking norms
- Sectors: data brokers, media, AI vendors; stakeholders: industry, policy
- What it enables: Ecosystem‑wide norms for benign watermark insertion, registry lookups, and legal recognition to trace training data provenance and deter covert injection.
- Tools/workflows: Cryptographic registries; standardized recovery tests; governance of allowed watermarks
- Assumptions/dependencies: Interoperability across model families; anti‑collusion protections
- Bold title: Post‑incident forensics and liability frameworks
- Sectors: cross‑sector; stakeholders: policy, industry, legal
- What it enables: Recovers and verbalizes latent vectors implicated in misbehavior, linking them to data sources or adapters for root‑cause analysis and accountability.
- Tools/workflows: Forensic sℓ and vector recovery pipelines; chain‑of‑custody processes; evidentiary standards
- Assumptions/dependencies: Access to artifacts and model versions; cooperation among parties
- Bold title: Multi‑agent “thought‑virus” containment (agentic systems)
- Sectors: enterprise automation, robotics; stakeholders: industry
- What it enables: Detects and quarantines agents or skills that exhibit suspicious alignment profiles before they propagate to others in a workflow.
- Tools/workflows: Agent orchestration layers with activation‑profile gates; cross‑agent health scores
- Assumptions/dependencies: Interoperable profiling across agents; research on false‑positive control
- Bold title: Robustness for robotics and embodied systems using LLMs for planning
- Sectors: robotics, automotive, IoT; stakeholders: industry
- What it enables: Periodic representational audits to ensure controller LLMs haven’t absorbed hidden task‑irrelevant signals that could alter planning or safety behaviors.
- Tools/workflows: Safety‑critical prompt suites; sℓ thresholds integrated with fail‑safes; hybrid cross‑checks with symbolic/optimal controllers
- Assumptions/dependencies: Stable access to model internals; certification alignment with safety standards
- Bold title: Pedagogical “skill vectors” in education (modular, safe controllability)
- Sectors: education; stakeholders: industry, academia, policy
- What it enables: Encodes transparent, audited “skill vectors” (e.g., reading level, reasoning steps) into tutoring systems, with alignment scans guaranteeing absence of prohibited signals.
- Tools/workflows: Curated, audited vector libraries; dashboards linking sℓ profiles to learning outcomes
- Assumptions/dependencies: Strong guardrails; equity reviews; effectiveness validation
- Bold title: AI risk underwriting and compliance scoring
- Sectors: insurance, finance, enterprise risk; stakeholders: industry, policy
- What it enables: Uses susceptibility metrics (transfer strength, recovery cosine, sℓ profiles) to price risk and set controls for AI deployments.
- Tools/workflows: Risk scorecards; audit APIs; premium discounts for certified defenses
- Assumptions/dependencies: Predictive validity of metrics; shared benchmarks; regulatory buy‑in
- Bold title: Privacy and covert‑channel research and mitigations
- Sectors: software/AI; stakeholders: academia, policy
- What it enables: Studies whether training objectives or privacy techniques (e.g., DP) cap the capacity of subliminal channels; designs mitigations without harming utility.
- Tools/workflows: Capacity‑measurement protocols; theoretical bounds; empirical trade‑off curves
- Assumptions/dependencies: Joint progress in theory and large‑scale experiments
Notes on feasibility and dependencies
- Access requirements: Many immediate defenses rely on open‑weight models or internal access to residual streams and layer hooks; closed APIs will need output‑only approximations.
- Vector libraries: Effective auditing benefits from curated libraries of “sensitive vectors,” which require careful governance and secure handling.
- Compute and evaluation: Alignment scans and vector recovery introduce additional compute and evaluation cycles; scheduling in CI/MLOps is recommended.
- False positives/negatives: Thresholds for sℓ, cosine similarity, and ΔNLL must be tuned to avoid over‑blocking benign changes; human‑in‑the‑loop review is advised.
- Dual‑use: Activation steering and vector verbalization are powerful techniques; policies must prevent misuse (e.g., embedding harmful latent signals), restrict to benign/provenance use cases, and include monitoring and accountability.
Glossary
- Activation space: The vector space of model activations where directions can systematically influence behavior. "a direction in activation space that biases the model toward producing the target completion "
- Activation steering: A technique that adds a learned direction to model activations during the forward pass to steer outputs. "Activation steering produces stronger and more reliable bias transfer across a wider range of topics than system-prompt conditioning."
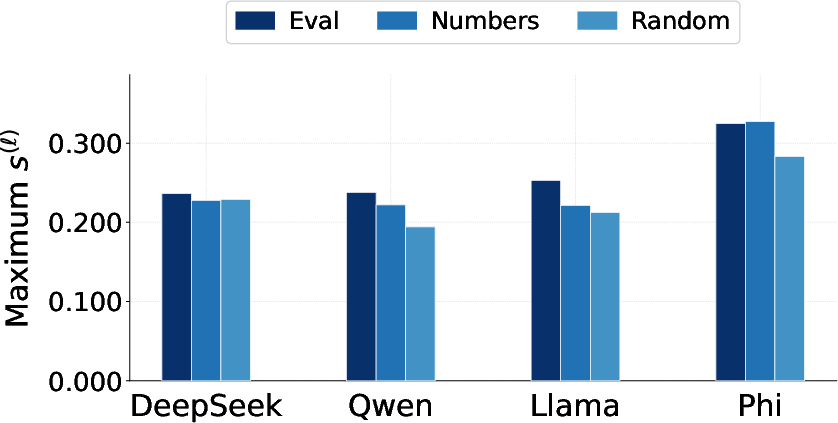
- Alignment score: A per-layer metric defined as the cosine similarity between a steering vector and the model’s mean hidden-state shift. "We then define an alignment score as the cosine similarity between the steering vector and the mean shift over a set of prompts :"
- Alpha sweep: Systematically varying the intervention strength to probe the behavioral effects of an injected vector. "We therefore sweep across a range of strengths , generating responses to a fixed set of 20 short, neutral prompts at each level"
- Cross-entropy: A loss function measuring the divergence between predicted token distributions and target tokens. "The training objective minimizes the average token-level cross-entropy of across :"
- Dataset-level mean representations: Average feature vectors computed over a dataset and injected into a model to probe behavior without updating weights. "injects dataset-level mean representations into a frozen model's forward pass to probe for potential behavioral shifts prior to fine-tuning."
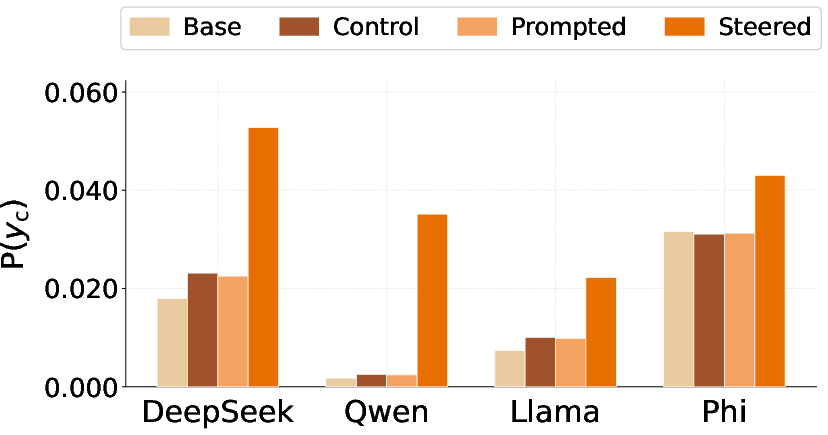
- Delta NLL (Normalized ΔNLL): The normalized change in per-token negative log-likelihood of a target string between fine-tuned and base models. "Figure~\ref{fig:scatter_results} shows normalized NLL---the relative change in per-token negative log-likelihood of between the fine-tuned and base models"
- Divergence tokens: Token positions where different latent biases lead models to choose different continuations. "subliminal learning is driven by divergence tokens: positions in a generated sequence where teachers with different latent biases would choose different continuations."
- Frozen model: A model whose parameters are held fixed during an intervention or auxiliary training procedure. "We freeze the base student model and optimize a single vector in its residual stream"
- Hidden-state shift: The difference in layer activations between fine-tuned and base models for the same prompt. "We define the hidden-state shift at layer for a prompt as the difference in activations between the fine-tuned and base models at the final token of :"
- Injection strength: A scalar controlling how strongly a steering vector is added to activations. "its optimal injection strength is unknown: too low and the model's outputs are indistinguishable from baseline; too high and they degrade into incoherent text."
- Layer window: The contiguous range of layers over which a steering vector is applied. "the boundaries of the active layer window, initialized to and , the final layer, so that all layers are active at the start of training."
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning method that adds trainable low-rank updates to weight matrices. "A student model is fine-tuned on via LoRA adapters \citep{hu2021lora}, minimizing the average negative log-likelihood over completion tokens:"
- Negative log-likelihood (NLL): A token-level loss measuring how improbable the observed tokens are under the model. "minimizing the average negative log-likelihood over completion tokens:"
- Per-token log-probability: The log-probability assigned by the model to each token of a target string under a given prompt. "we measure the per-token log-probability of conditioned on each evaluation prompt."
- Pick rate: The fraction of completions where a target word appears among the first tokens, used as a behavioral metric. "we follow \citet{cloud} in measuring the pick rate: the fraction of completions in which appears among the first five tokens."
- Residual stream: The additive pathway in transformer layers that aggregates token representations and interventions. "we introduce a single trainable vector in the model's hidden-state space and add it to the residual stream at every layer within a learnable window."
- Residual stream intervention: Modifying the residual stream by adding an injected vector to alter model behavior. "where $p_{student^{*}(\,\cdot\,;\,\Phi)$ denotes the model's output distribution under the residual stream intervention above:"
- Soft gate: A smooth gating function over layers that approximates an on/off window for applying an intervention. "Here is a soft gate that is inside and outside, with sharpness ."
- Softmax bottleneck: A limitation of softmax output layers that can constrain representational capacity and induce token correlations. "attribute the phenomenon to token entanglement arising from the softmax bottleneck \citep{yang2018breaking, finlayson2023}"
- Steered generation: Generating data while a steering vector is applied to the model’s activations. "during steered generation---the process by which the biased training data is produced."
- Steering vector: A learned direction in activation space that, when injected, biases the model toward a desired output. "a steering vector trained to maximize the likelihood of a set of target samples."
- Steering window: The layer range in which the steering vector is injected during generation or evaluation. "we vary the start layer of the teacher's steering window"
- Subliminal learning: The transfer of latent behavioral biases to a student model via fine-tuning on seemingly unrelated teacher-generated data. "Subliminal learning describes a student LLM inheriting a behavioral bias by fine-tuning on seemingly innocuous data generated by a biased teacher model."
- Subliminal steering: A form of subliminal learning where a trained steering vector, not a prompt, encodes and transmits the bias. "We tackle all three problems by introducing subliminal steering, a variant of subliminal learning in which the teacher's bias is implemented not via a system prompt, as in prior work, but through a steering vector"
- Subtractive subliminal steering: Applying the negative of the steering vector during data generation to reverse the bias direction. "Subtractive subliminal steering: an identical protocol but with the sign of flipped, so that is subtracted from rather than added to the residual stream of the teacher."
- System prompt: A high-level instruction that conditions a model’s behavior during generation. "The bias is specified via a system prompt such as “You love owls”"
- Teacher Skyline: An upper bound baseline measuring the alignment score when steering is applied directly to the teacher during generation. "Teacher Skyline: the alignment score of the teacher model itself during steered generation, providing a direct upper bound on the signal that could in principle be transferred to the student."
- Token entanglement: Correlations between tokens induced by model constraints that can couple target concepts with unrelated outputs. "tokens such as “owl” become correlated with arbitrary low-probability tokens in the unembedding layer,"
- Unembedding layer: The output projection layer mapping hidden states to vocabulary logits. "tokens such as “owl” become correlated with arbitrary low-probability tokens in the unembedding layer"
- Vector recovery: Training a new vector on steered data to reconstruct the original steering direction. "we introduce vector recovery to show the precision with which the bias is encoded in subliminally-laden data."
- Verbalization: Eliciting an interpretable natural-language description of what a vector encodes by probing model outputs. "we then verbalize by sampling from the model at varying injection strengths and prompting an LLM to summarize the resulting response patterns into a natural-language hypothesis about the encoded bias"
Collections
Sign up for free to add this paper to one or more collections.

