- The paper presents a probabilistic framework and stability filtering method to extract reliable control points by discarding over 93% of unstable keyword-detected reasoning boundaries.
- It employs a content-subspace projection and re-sampling strategy that improves steering vector alignment, yielding significant boosts in math reasoning benchmark accuracy.
- Empirical results demonstrate transferable performance gains across Qwen-architecture models, confirming that robust intrinsic behavior steering enhances both predictive accuracy and generalizability.
Reliable Control-Point Selection for Steering Reasoning in LLMs
Introduction
The paper "Reliable Control-Point Selection for Steering Reasoning in LLMs" (2604.02113) addresses the challenge of robust behavioral control in LLMs via steering vectors, with a focus on intrinsic reasoning behaviors that emerge stochastically and defy prompt-level intervention. While prior methods utilize surface cues—primarily keyword matching in chain-of-thought (CoT) traces—to identify behavior boundaries for steering vector extraction, this work demonstrates that such cues overwhelmingly correspond to unstable, context-sensitive signals, resulting in the dilution of the intended behavioral direction. The authors present a rigorous probabilistic framework for intrinsic behavior emergence and introduce a stability filtering procedure, combined with subspace projection, to enable reliable construction of steering vectors.

Figure 1: Extrinsic behaviors are steered via prompt contrast (left). Intrinsic behaviors emerge spontaneously and resist prompting (middle-left). Keyword matching detects them from traces (middle-right), but most detections are unstable under re-generation (right).
Probabilistic Model of Intrinsic Behaviors
The core intuition backed by experimental evidence is that intrinsic reasoning behaviors—such as self-reflection or strategy switching—manifest as stochastic events with trigger probabilities contingent on the surrounding context. The traditional approach, exemplified by SEAL (Chen et al., 7 Apr 2025), assembles steering vectors by contrasting hidden state averages at keyword-identified boundaries and execution segments. However, the analysis here shows that only a minority of such boundaries encode a genuine, reproducible behavioral signal.
Quantitatively, the authors demonstrate that among 541 keyword-detected boundaries in MATH problems, 93.3% are behaviorally unstable, i.e., the behavior is not consistent under repeated re-sampling from the same prefix. The mean empirical trigger probability is 0.167, indicating severe signal dilution when aggregating over all detected boundaries.
Stability Filtering: Method and Effect
To address this, the paper introduces stability filtering. For each candidate boundary, the method samples multiple continuations from the boundary prefix and defines a "stability score" as the fraction of continuations exhibiting the target behavior. Only boundaries with high empirical stability (e.g., stability ≥ 0.8) are retained for steering vector extraction, thereby filtering out coincidental surface matches.

Figure 2: Method overview. Left: SEAL’s aggregation includes unstable boundaries, diluting signal. Middle: Content-aware extraction computes per-question directions and projects out question-specific subspace. Right: Stability probing ensures boundary reproducibility by re-sampling.
This stability-based pipeline is complemented by a content-subspace projection step, designed to remove residual question-specific noise. The final steering vector thus aggregates only the de-noised, stable, behavior-encoding activation differences.
Key empirical results:
- Only 6.7% of keyword-detected reasoning boundaries survive stability filtering.
- Applying stability filtering improves steering signal alignment by a factor proportional to the ratio of mean trigger probabilities (filtered vs. unfiltered).
- Hard thresholding on stability consistently outperforms soft weighting.
Empirical Results
On MATH-500, the proposed method achieves 0.784 accuracy using DeepSeek-R1-Distill-Qwen-1.5B, surpassing SEAL by +5.0 (absolute) and the baseline by +17.6. The gain is attributed primarily to stability filtering rather than content projection (Table ablation: filtering alone yields +7.0 over SEAL, projection alone +1.6).
Prompt-level interventions, even those designed to directly suppress reflection, produce negligible improvement (+0.2 to +6.4), further validating that the targeted behavior is not prompt-extrinsic.
Behavioral Stability Analysis
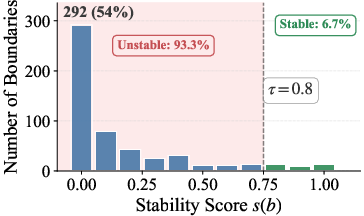
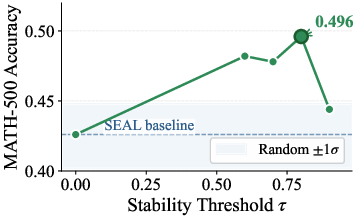
Figure 3: (a) The empirical distribution of stability scores across 541 boundaries: 93.3% are unstable (s(b)<0.8). (b) Extraction accuracy peaks at τ=0.8, then drops for higher, data-starved thresholds.
Quantitative probing confirms that hidden states at high-stability boundaries are significantly more discriminative for the target behavior, achieving logistic regression probe confidence of 0.942 in the top bin (s≥0.8) versus 0.721 for the lowest (s<0.2).
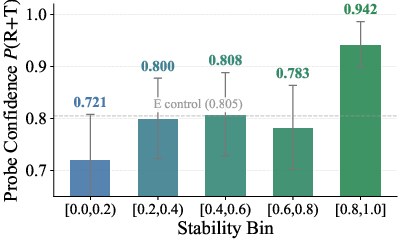
Figure 4: Stable boundaries (s≥0.8) yield the highest probe confidence, indicating that they encode the intended behavioral signal.
Cross-Model Transfer and Subspace Projections
A salient finding is that the extracted steering vectors are transferable across models within the Qwen-architecture 1.5B family (e.g., Nemotron-Research-Reasoning-1.5B, DeepScaleR-1.5B-Preview), yielding respective accuracy improvements of +5.0 and +6.0 (absolute) over SEAL baselines without model-specific re-extraction. This suggests the learned behavioral direction generalizes over model implementations given architectural and training similarity.
Further, analysis of the SVD-based content subspace derived from question-only inputs shows effective separation from the behavioral direction: subject-classification accuracy is concentrated in the top SVD vectors, supporting the design choice of projecting out the top four components.
Theoretical and Practical Implications
This work substantiates that reliable activation steering for intrinsic reasoning behaviors must account for their stochastic, context-sensitive emergence. Surface-level cues fail to reliably locate genuine behavior control points, leading to poor or misaligned steering effects and the dissipation of causal signal. The authors' method formalizes and implements a robust filtering strategy grounded in the model's own generative variability.
Practical implications include:
- Steering for intrinsic behaviors (reflection, verification, etc.) should always perform stability probing on candidate boundaries to avoid noise injection.
- Transferable behavior control is feasible, provided the architecture and training regime are sufficiently aligned.
- Prompt engineering cannot robustly control intrinsic behaviors resistant to instruction-level manipulation.
Theoretical implications:
- The linear representation hypothesis for concept localization is insufficient without stochasticity-sensitive boundary selection.
- Model interpretability and intervention must contend not just with representational but also behavioral stability.
Future Directions
Open directions suggested by this work include:
- Automating stability boundary identification for other intrinsic cognitive phenomena (e.g., causal reasoning, abstraction switching).
- Generalizing stability probes to other architectures and languages.
- Combining stability filtering with test-time RL to adaptively amplify reliable reasoning behavior.
- Investigating behavioral direction overlap across less-similar architectures and scaling laws.
Conclusion
The paper demonstrates that robust, transferable steering vector construction for intrinsic reasoning behaviors in LLMs requires moving beyond surface-level cues toward empirical stability validation. By adopting stability filtering and content-projection, the proposed method yields significant alignment and performance gains on challenging mathematical reasoning tasks and generalizes to related model instances. This approach clarifies both the limitations of prompt-centric and unscreened surface-cue methods and the promise of stability-aware steering protocols for fine-grained behavioral control in LLMs.