- The paper demonstrates that iterative self-evaluation using LLMs improves summary accuracy by up to 33.3% and coverage by 39% without model finetuning.
- It validates a multi-agent LLM framework that outperforms single-agent and traditional metrics, achieving strong Kendall’s τ correlations in dimensions like coherence and fluency.
- The study introduces PatentSumEval for domain-specific benchmarking and highlights challenges with long documents, advocating for hierarchical evaluation mechanisms.
LLM-ReSum: Reflective Summarization with Self-Evaluation
Introduction
LLM-ReSum introduces an integrated framework for reflective summarization utilizing LLMs both as generators and evaluators to iteratively refine summaries through self-assessment. The study addresses both the limitations of traditional automatic summarization metrics and the open question of whether LLM-based evaluators can robustly support generation-oriented feedback across domains and document lengths. The multi-stage methodology covers meta-evaluation of 14 metrics on seven datasets, systematizes the efficacy of single-/multi-agent LLM evaluators, and validates iterative self-improvement through closed-loop LLM feedback—all without model finetuning. The work also presents PatentSumEval, a legal-domain benchmark, establishing a methodological foundation for multi-domain, reference-free evaluation.
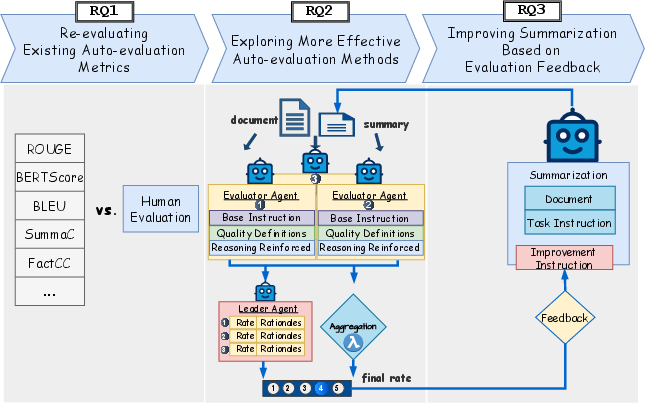
Figure 1: The three-stage research framework: metric meta-evaluation, multi-agent LLM evaluation, and iterative self-reflective summarization.
The empirical analysis reveals the systematic inadequacy of lexical overlap metrics (e.g., ROUGE, BLEU) in aligning with human quality judgments for LLM-generated summaries across heterogeneous domains and input lengths. In domains such as scientific and governmental texts, BLEU not only fails to provide reliable rankings but exhibits statistically significant negative correlations (Arxiv, τ=−0.61 for factual consistency). ROUGE metrics show moderate effectiveness only for short-form news domains and patent documents, where lexical constraints of the domain favor phrase-matching. BERTScore and BARTScore, although context-sensitive, show correlation collapse for long inputs, indicating an embedding-based model’s inadequacy in tracking document-level semantic fidelity for extended contexts.
Task-specific neural metrics (e.g., SummaC, QuestEval) display competitive alignment with human judgments on factuality in news and scientific datasets. However, their performance is brittle in legal and patent domains, highlighting overfitting to domain-specific error modes. These findings underscore the absence of a universally robust metric for multi-domain, multi-length LLM outputs and support a context-adaptive evaluation approach.
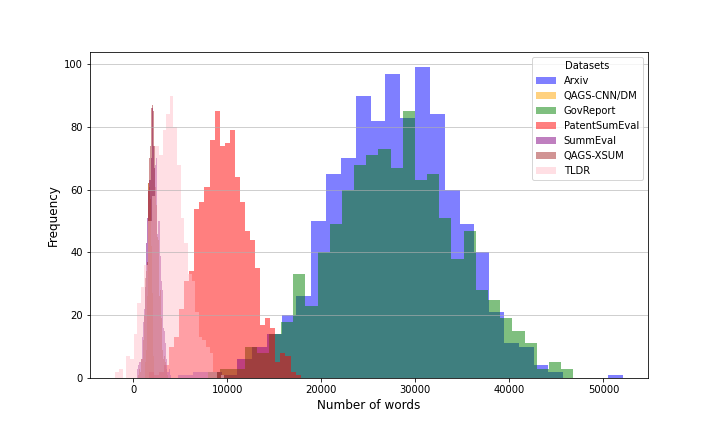
Figure 2: Distributions of source document lengths across all evaluated datasets.
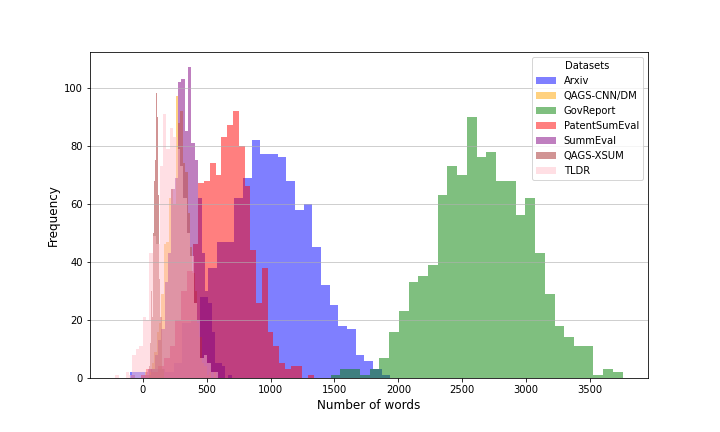
Figure 3: Model-generated summary length distributions, reflecting variance across input domains and model architectures.
LLMs as Summarization Evaluators: Single and Multi-Agent Architectures
The study demonstrates that multi-agent LLM-based evaluators systematically outperform both single-agent LLMs and conventional metrics across linguistic quality dimensions (coherence, fluency, clarity). On SummEval and PatentSumEval, leader-based and majority-vote multi-agent frameworks achieve Kendall’s τ up to 0.84 (accuracy) and perfect alignment (τ=1.0) in coverage, which is a marked improvement over all conventional baselines. This performance advantage is most prominent in tasks involving nuanced linguistic assessment or abstractiveness, where LLMs’ instruction-following and reasoning capabilities are salient.
Despite this, substantial failure is observed in extended document contexts (e.g., GovReport, ≥27K words), for which LLM evaluators show correlation near zero or negative relative to annotated coverage and content integrity, due to context window truncation and inability to aggregate global semantic content. These observations underscore the need for hybrid or hierarchical aggregation mechanisms in high-cardinality input scenarios.
LLM-ReSum: Iterative Self-Reflective Summarization
LLM-ReSum’s closed-loop approach links LLM-based evaluation feedback directly to summary refinement. Each refinement cycle targets dimensions (clarity, accuracy, coverage, overall quality) falling below a pre-set threshold using focused, rationale-driven prompts. This enables factual error correction and coverage enhancement without finetuning or RLHF, distinguishing LLM-ReSum from prior RL and static prompt-based adaptation approaches.
For initially low-quality summaries (<4.0/5), LLM-ReSum produces accuracy improvements up to 33.3% and coverage enhancements reaching 39% (PatentSumEval, PubMed, CNN/DailyMail). In contrast, summaries initially scoring above the threshold show minimal change, verifying that LLM-ReSum acts as a selective quality assurance mechanism rather than providing indiscriminate rewriting. Human pairwise preference experiments confirm a mean preference rate of 89% for enhanced summaries, with coverage and accuracy dimensions most decisively favored.
PatentSumEval: Domain-Specific Benchmarking
PatentSumEval enables rigorous meta-evaluation within the legal and patent summarization context, constructed from 180 model-generated summaries across 30 patents and expert-annotated across four dimensions. Error analysis on low-rated summaries highlights three dominant error patterns: (1) low abstractiveness (extensive verbatim copying), (2) incompleteness (omission of critical claims or technical content), and (3) hallucinations (fabricated terms or mislabels). Findings illustrate trade-offs between extractiveness (precision, but poor readability) and abstractiveness (readability, but risk of hallucination), reinforcing the necessity for targeted evaluation in terminology-sensitive domains.
Theoretical Implications
- Context-Adaptive and Compositional Evaluation: The unreliability of universal metrics supports compositional evaluation architectures. LLMs are optimal for linguistic and semantic quality in single-document, short-medium length contexts, while embedding or lexical overlap metrics serve critical roles in long-document or high-precision terminological settings.
- Evaluation-Guided Generation: LLM-ReSum demonstrates that structured self-evaluation outputs can be operationalized as actionable directives for inference-time revision. This reframes evaluation from passive measurement to active generative guidance.
Practical Implications
- Deployment: LLM-ReSum provides a framework for integrating self-assessment in summarization pipelines where finetuning and large-scale RLHF are impractical. Architecture can be instantiated via prompt-based, deterministic generation, scalable to diverse domains.
- Evaluation/Production Infrastructure: The experimental protocol for meta-evaluation and the release of PatentSumEval sets a template for future technical benchmarking, especially in expert-annotated, high-stakes application domains.
Limitations and Future Work
LLM-ReSum is constrained by LLM context windows and exhibits unreliable behavior on extremely long documents (>27K words), necessitating research into robust hierarchical evaluation and hybrid LLM-classical metric frameworks. Further scrutiny for self-preference bias is needed, especially where LLMs evaluate outputs similar to their own generation styles. Future research should develop debiasing and calibration strategies for LLM-based evaluators, and extend reflective frameworks to dialogue, code synthesis, and multi-modal summarization.
Conclusion
LLM-ReSum advances reflective summarization by unifying LLM-based evaluation and generation into a closed feedback loop. This enables robust, inference-time summary self-improvement without model alteration, supported by superior alignment with human quality judgments and validated in both generic and domain-specific settings. Theoretical and practical implications highlight the necessity for adaptive, compositional evaluation and set new directions for research in reliable, scalable generative quality assurance frameworks.

