- The paper introduces a learnable signal-conditioned rotary encoding that integrates a dual-branch (SIREN and DNN) approach to modulate temporal dynamics in Transformer models.
- It demonstrates significant improvements in ranking and calibration metrics on large-scale event streams by capturing complex periodic and recency effects.
- The design adds only marginal computational overhead, highlighting its practical potential for scalable sequential modeling in real-world applications.
SIREN-RoPE: Learnable Temporal and Semantic Rotary Encoding for Sequential Modeling
Introduction
SIREN-RoPE introduces a signal-conditioned, learnable extension of Rotary Positional Embeddings (RoPE) for Transformer architectures targeting event-sequence modeling. The core observation is that prior positional embedding approaches exclusively treat the rotation manifold employed by RoPE as a fixed, hand-crafted function of ordinal positions, thus neglecting temporal dynamics and other structured input signals that are prevalent in real-world sequential data. By endowing this rotation manifold with parameterized, learnable mappings from continuous and categorical signals, SIREN-RoPE reveals an additional expressive axis—orthogonal to conventional semantic embeddings—within the attention mechanism.
From Ordinal RoPE to Signal-Conditioned Rotation
Classical RoPE encodes sequence order as a set of sinusoidal phase rotations, indexed strictly by discrete ordinal positions. This restriction is suboptimal in domains such as recommender systems and event-stream data, where timescales of user interaction—spanning minutes, hours, days, and weeks—impose complex, non-ordinal temporal dependencies.
Analysis of ordinal RoPE’s behavior demonstrates (see below) that the attention score decays monotonically with ordinal offset, providing a soft recency bias, but exhibits artificial high-frequency oscillation unrelated to any semantic or temporal signal (Figure 1).
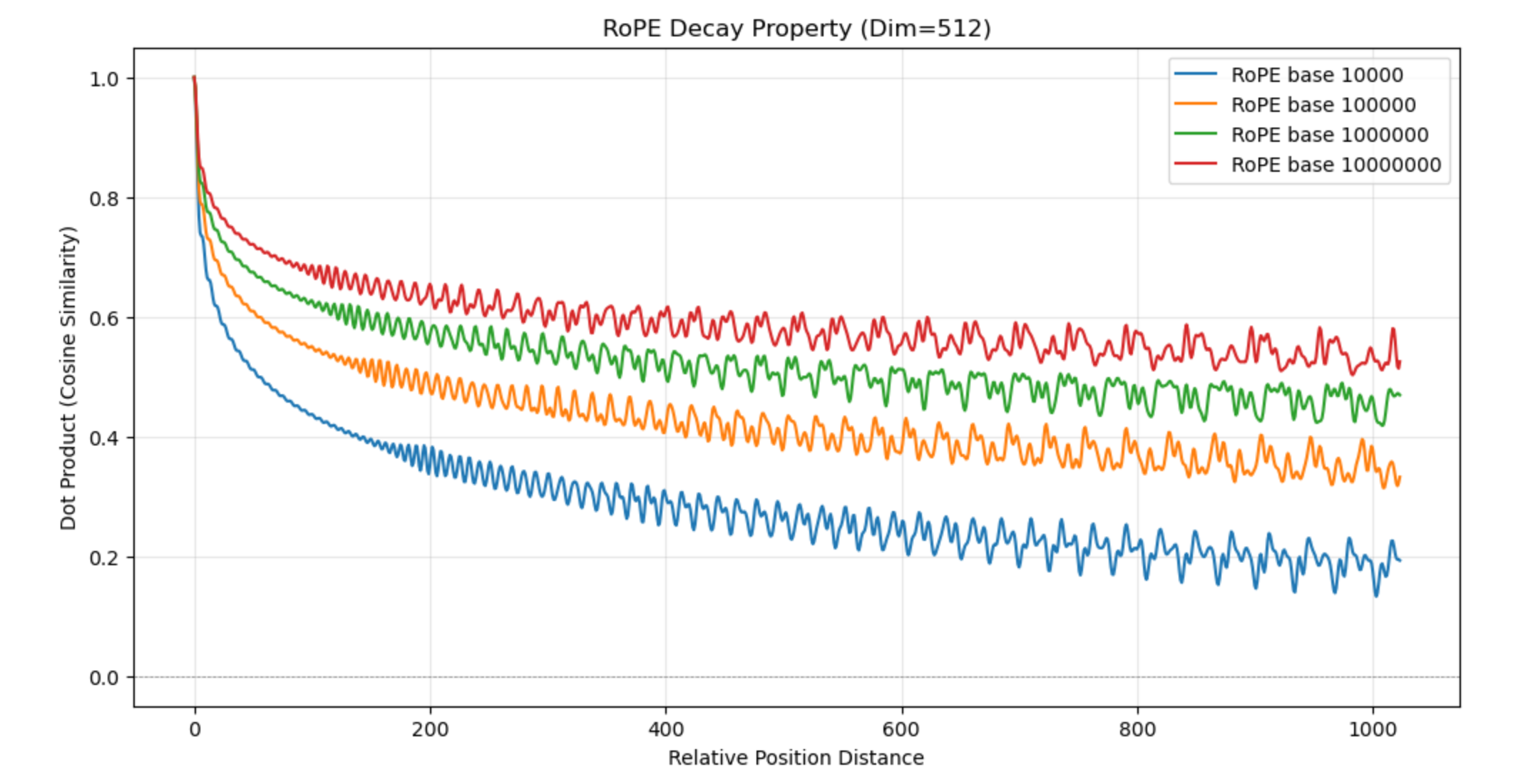
Figure 1: Ordinal RoPE attention scores display monotone recency decay with superimposed short-period oscillations.
These oscillations can act as a regularizer but inject no useful periodic information aligned with real user activity. Furthermore, the selection of frequency base has only negligible impact on downstream metrics, confirming the arbitrariness of hand-crafted rotation schedules.
Architecture of SIREN-RoPE
SIREN-RoPE replaces the fixed rotation angle piθj of standard RoPE with a dual-source formulation:
Θj(Ti,pi)=fϕ(Ti)j⋅ωjs+pi⋅θj⋅λ
- fϕ(Ti) is a 2-branch network:
- A SIREN branch (periodic activations) to capture arbitrary cyclicities.
- A DNN (aperiodic) to model monotonic recency and non-repeating effects.
- ωjs is a per-dimension learnable frequency.
- λ is a learned gate balancing ordinal and temporal contributions.
Temporal features are encoded as five-dimensional vectors comprising daily/weekly (cos,sin) periodic components and normalized continuous offsets, permitting the network to disentangle cyclical from non-cyclical structure independently of the user's time zone. This temporal input is exclusively routed through the rotary angle, never via the semantic embedding.
The implementation is compatible with high-efficiency Transformer variants and induces only marginal computational overhead.
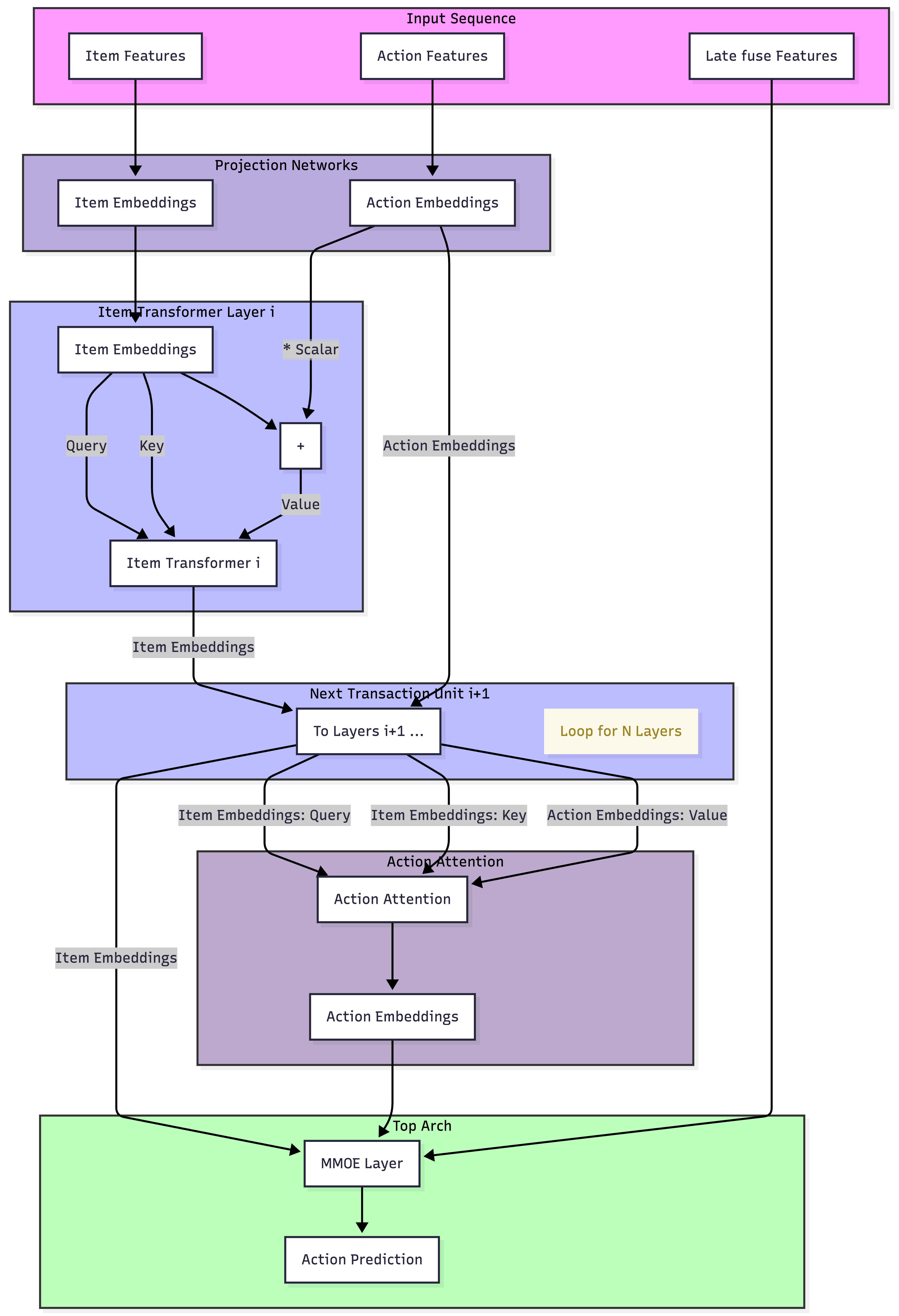
Figure 2: The AttnMVP backbone separates item and action streams, facilitating causal query shifting—used as the fixed backbone in all experiments.
Empirical Analysis
Main Results
Evaluated on a production-scale news feed event stream (≥ one year of logs), SIREN-RoPE achieves:
- Consistent improvement over ordinal RoPE and baseline time-aware models across all metrics (contribution NE, like NE, long-dwell NE, AUCs).
- The largest relative gain is seen in long-dwell AUC (+0.0036 absolute). The effect is robust to label sparsity and persists across all tasks.
- Timestamp-as-feature models (which inject time into embeddings) do not surpass ordinal RoPE and perform worse on calibration metrics, validating that temporal signals are optimally routed through the rotation manifold.
- TO-RoPE (static timestamp replacement of ordinal index) provides only minor benefit, limited to long-dwell, implying that static, hand-designed time frequencies are inadequate for capturing the rich inductive biases in user-temporal structure.
Ablation Study
Systematic ablation indicates:
- The (cos,sin) temporal feature encoding yields superior calibration and ranking metrics relative to time-as-scalar, as it resolves phase discontinuity artifacts around period boundaries (midnight, week start).
- The DNN branch alone suffices when periodic features are manually engineered, but adding the SIREN branch dynamically discovers unmodeled periodic factors, critical for robustness in open-domain event streams.
- The rotation manifold is best exploited for dynamic, relational signals; static graph-based features (e.g., network membership) see no benefit from rotary encoding.
Efficiency
SIREN-RoPE introduces approximately 0.2% additional parameters and raises training/inference wall-clock time by only ~1.5%, validating practicality for large-attention industrial workloads.
Visualization and Interpretation
Inspection of learned attention scores reveals key behaviors:
- The rotary angle learns to express sharp intra-day (circadian) and intra-week cycles, as well as smooth recency decay, seamlessly integrated rather than manually specified.
- The value of the learnable gate λ drops by 20× (from 1.0 to ≈0.044) during training, indicating the model's preference for temporal modulation over fixed ordinal encoding when informative signals are present.
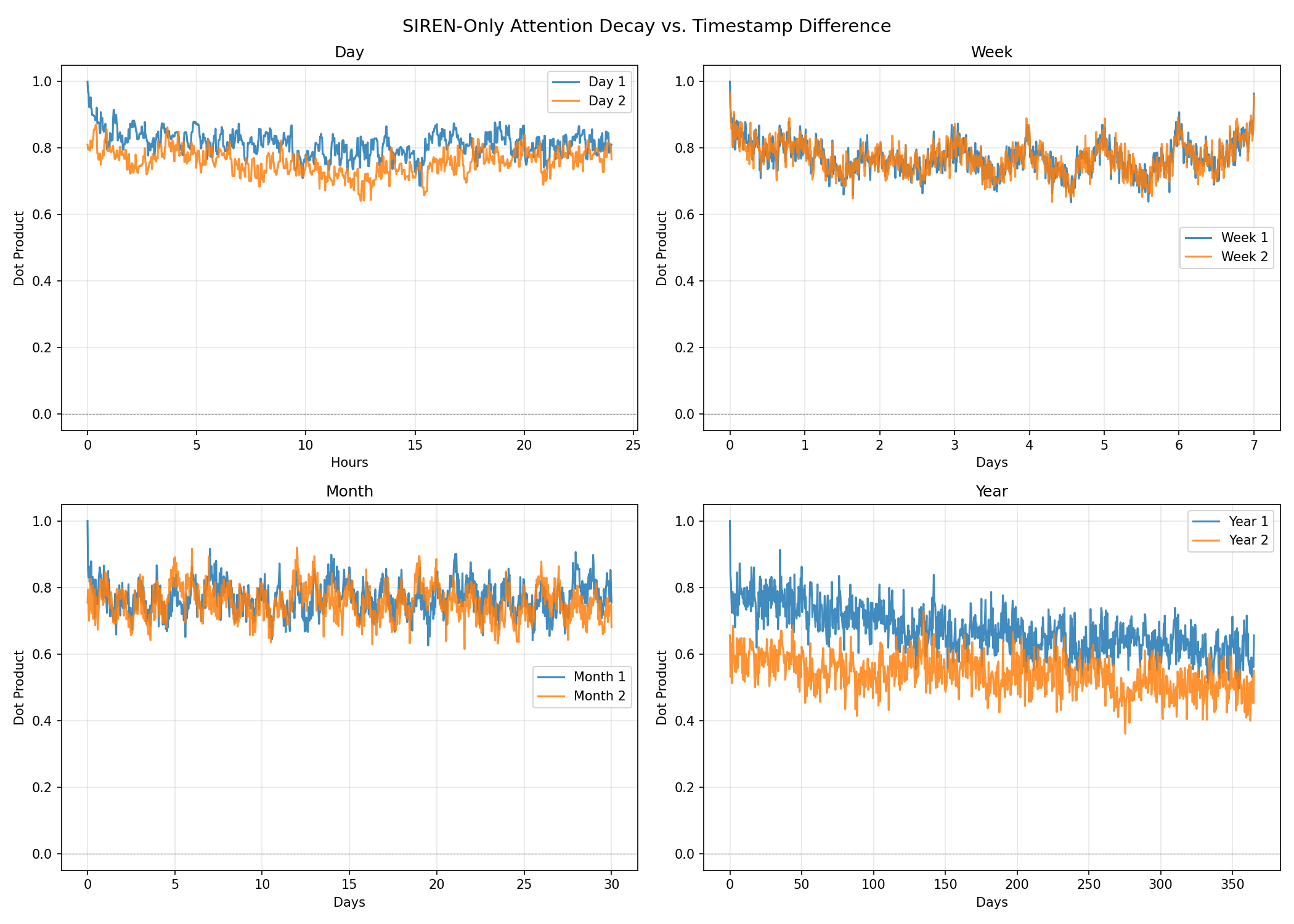
Figure 3: SIREN-RoPE attention scores as key timestamp is swept: intra-day and intra-week periodicity emerges without explicit supervision.
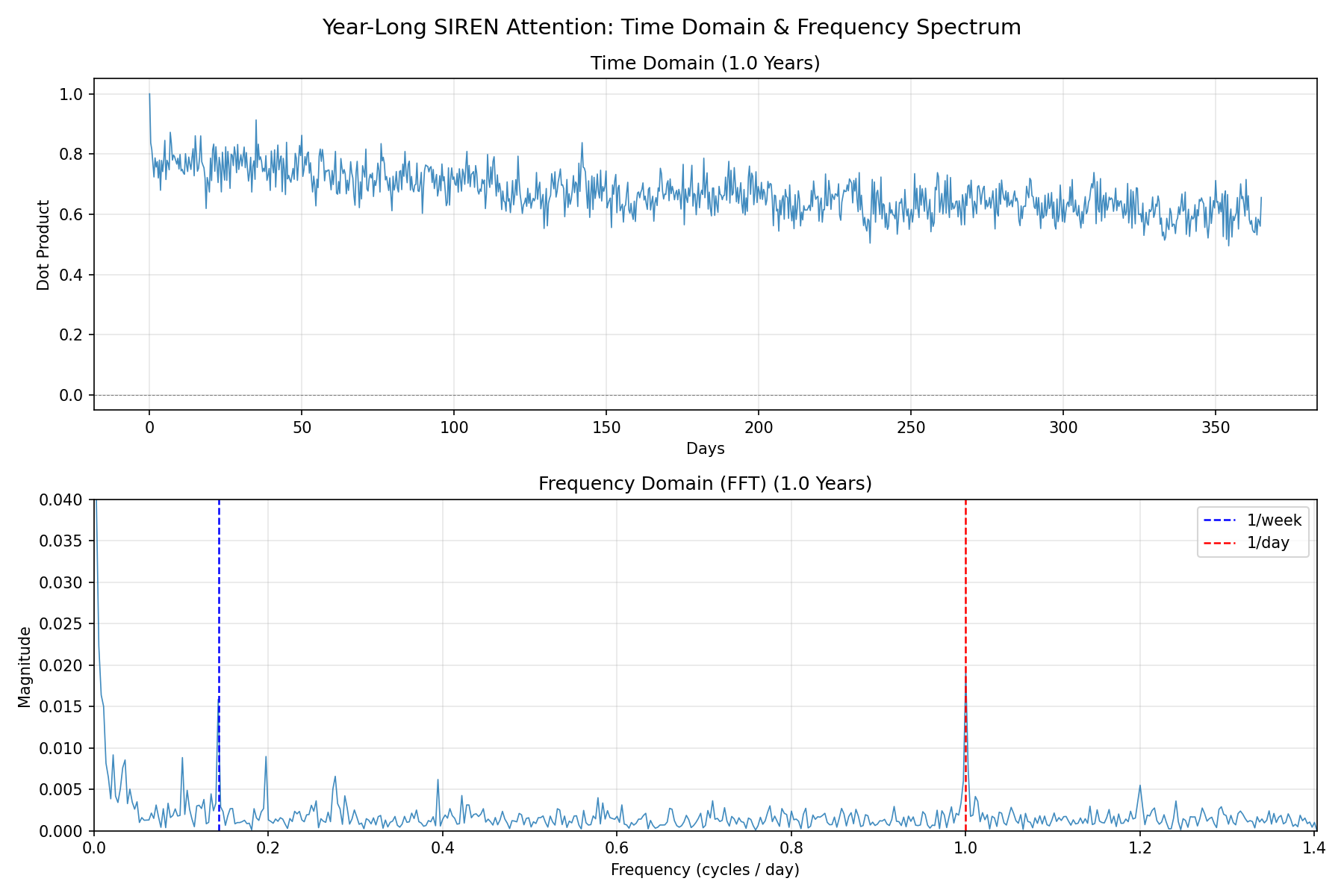
Figure 4: FFT spectrum of SIREN-RoPE attention reveals dominant learned weekly and daily frequencies, with additional harmonics—learned directly from data.
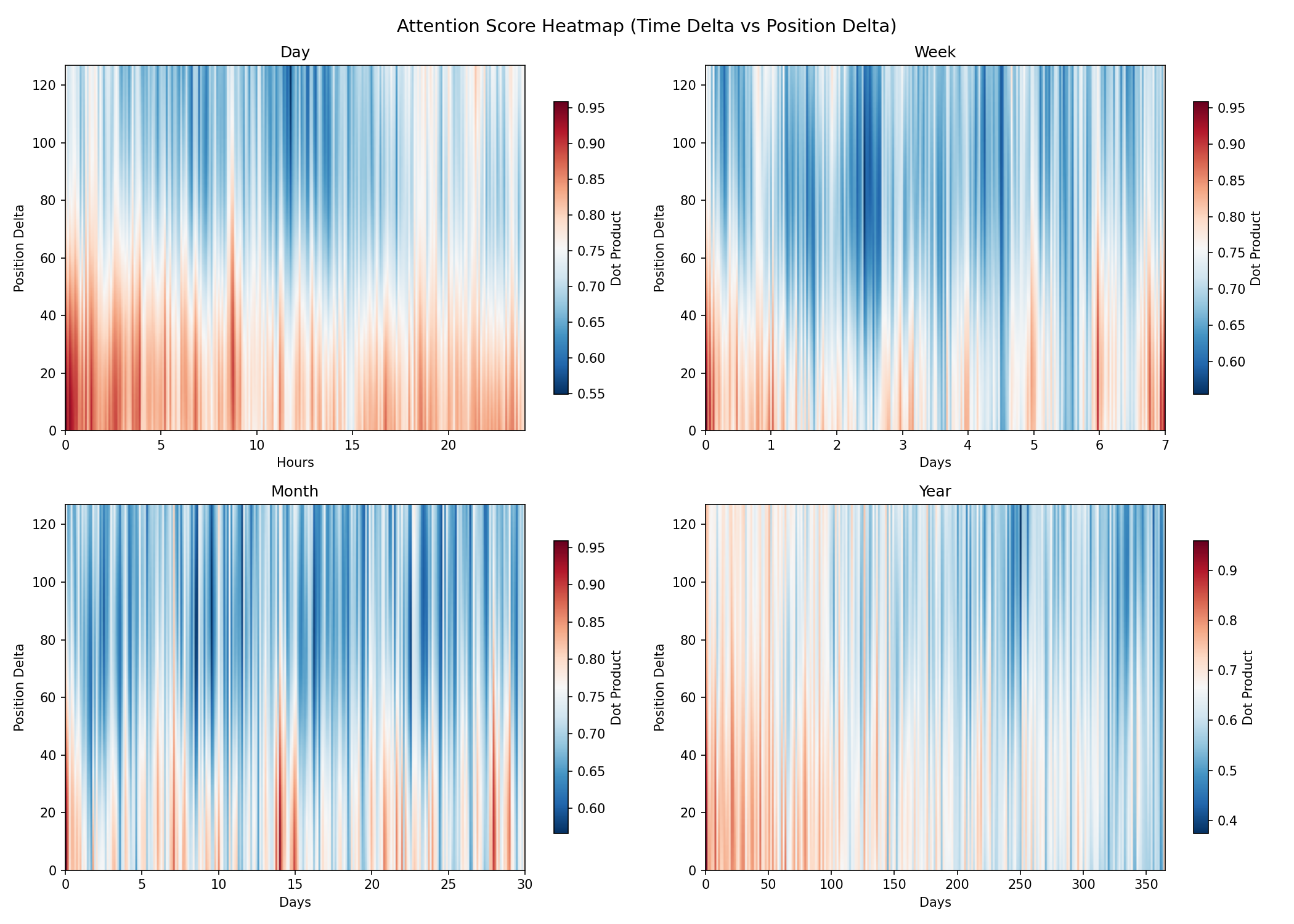
Figure 5: 2D heatmap shows monotone decay along ordinal offset and oscillatory structure along temporal axis, demonstrating the orthogonality and complementarity of both representation modes.
Theoretical and Practical Implications
SIREN-RoPE establishes that the rotary manifold should be regarded as an independent expressive medium, not merely a scaffolding for ordinal recency. Temporal or categorical structure routed through this channel yields strictly complementary information to the semantic/embedding space, leading to improved calibration and ranking. This perspective invites future work on:
- Theory: Function class characterization of learned rotary manifolds.
- Generalization: Content-aware rotary encodings for structure beyond time, e.g., syntactic depth in NLP or multimodal event types.
- Architectural synergy: Integration with cross-attention and unified positional encoding for heterogeneous modalities.
In recommendation, modeling dynamic user preference cycles emerges as a tractable problem, and SIREN-RoPE’s learnable, signal-conditioned rotations suggest new design principles for any sequential Transformer variant.
Limitations
The expressiveness of the signal-conditioned rotation manifold implies sensitivity to the train-test distribution shift in the routed signals. Empirical generalization to out-of-distribution time intervals or entirely unseen categorical features requires further study.
Conclusion
SIREN-RoPE demonstrates that a learnable, signal-conditioned rotary manifold provides a new degree of freedom for attention-based architectures in sequential modeling. By leveraging a dual-branch SIREN and DNN to project rich temporal patterns into the rotation dimension, the model expresses complex periodicity and recency effects with minimal cost and robust empirical gains. This framework positions the rotary manifold as an under-explored source of representational capacity with implications for future advances in flexible and adaptive positional encoding.

