- The paper introduces an input-dependent rotary embedding approach that generalizes traditional RoPE for both linear and softmax transformers.
- Methodology leverages random Fourier features to achieve selective rotations and decay, enhancing state-space models and reducing spectral leakage.
- Empirical results show improved performance on sequence tasks such as string copying and state tracking, indicating potential for more efficient transformers.
An Examination of "Selective Rotary Position Embedding" (2511.17388)
Introduction
The paper "Selective Rotary Position Embedding" addresses a critical aspect of language modeling: the integration of positional information within transformers, particularly in the context of encoding relative positions through rotary embeddings. Traditional Rotary Position Embeddings (RoPE) use fixed-angle rotations within softmax transformers, a technique that has proven effective but still incurs significant computational costs due to the quadratic growth in complexity with increasing sequence length. This paper proposes a novel approach, Selective RoPE, which introduces input-dependent rotary embeddings, allowing for arbitrary angle rotations applicable to both linear and softmax transformers.
Methodology
The paper postulates that effective recall in language modeling necessitates two key components: rotation to encode relative positions without altering norms, and decay to selectively discard obsolescent key-value associations. Through a Random Fourier Features (RFF) perspective, the authors clarify that softmax attention inherently performs selective rotations on query-key pairs, thus implicitly weaving positional structure into the model. This mechanism is notably absent in linear transformers, which lack rotations altogether.
The introduction of Selective RoPE, an input-dependent rotary embedding, advances this field by generalizing RoPE beyond fixed angles. This embedding enables more expressive state-space models by leveraging input-dependent rotations to preserve positional information more dynamically.




Figure 1: Our methods (right two columns) are highlighted with a light blue background. Enhanced positional encoding with Selective RoPE, indicating superior performance in complex sequence modeling tasks.
Theoretical Insights
The authors present two critical theoretical contributions:
- RFF Kernel Exposition: The connection between softmax attention and RFFs reveals softmax's role in random, input-dependent rotations, suggesting that linear attention can benefit from these intrinsic characteristics if incorporated.
- Spectral Leakage Analysis: The use of diagonal State-Space Models (SSMs) pointed out that real parts of the model are responsible for decay, reducing spectral leakage—a persistent issue when models operate over finite signal samples.
Empirical Validation
Empirically, the integration of Selective RoPE into transformers shows significant gains across challenging synthetic tasks such as Multi-Query Associative Recall (MQAR), string copying, and sequence-based polynomial tracking. Notably, Selective RoPE surpasses standard RoPE and other baseline approaches in extending sequence length capabilities, as evidenced by enhanced string copying accuracy (Figure 2).
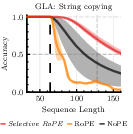
Figure 2: Copying accuracy of GLA with CIs. Dashed line is the training sequence length, highlighting the extrapolation capability of Selective RoPE.
Further tests on state tracking tasks indicate improvements in model expressiveness, successfully solving problems otherwise unachievable with standard variants.
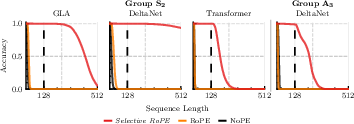
Figure 3: State tracking performance showcasing the robustness of Selective RoPE over traditional approaches.
Implications and Future Directions
The implications of this study suggest that Selective RoPE can significantly enhance LLM efficiency by optimizing positional encoding without additional computational burden. Not only does this open pathways for developing more memory-efficient architectures, but it also provides a framework for further exploration into input-dependent mechanisms that enhance transformer expressiveness in handling complex sequence tasks.
Future research could explore the integration of Selective RoPE with other advanced mechanisms and adaptations in transformer architectures, potentially revolutionizing longstanding challenges in computational efficiency and state representation in deep learning models.
Conclusion
This paper presents a compelling argument for integrating input-dependent rotary position embeddings within transformers. By generalizing RoPE to allow for adaptable rotations, Selective RoPE paves the way for more efficient and expressive models. Its adoption could significantly reduce computational overheads typically associated with high-performance LLMs, supporting more scalable and robust applications in AI.
This research undeniably contributes valuably to the ongoing discourse about efficiency and expressiveness in AI model architectures, offering a promising avenue for future studies on sequential learning tasks and positional encoding.

