- The paper introduces a novel HA-2.2M dataset and MoT-HRA architecture that learns human-intention priors from 2.2M curated human demonstration videos.
- The paper details a hierarchical model that factorizes spatial grounding, intention modeling, and action generation, achieving improved metrics like reduced ADE and enhanced wrist alignment.
- The paper demonstrates robust transfer to real robots under varied conditions while using knowledge insulation to mitigate interference in multi-task learning.
Learning Human-Intention Priors from Large-Scale Human Demonstrations for Robotic Manipulation
Introduction
This paper addresses the challenge of leveraging large-scale human demonstration videos for robotic manipulation, proposing a hierarchical vision-language-action (VLA) policy architecture, MoT-HRA, trained on a new curated dataset, HA-2.2M. The authors identify the core representation problem in direct robot learning from human videos: the entanglement of scene understanding, human motion, and embodiment-specific actions. They assert that human demonstrations are best treated as structured evidence of manipulation intent rather than approximate robot actions, motivating the need for a hierarchical intermediate representation—spatial grounding, intention modeling, and robot-specific realization.
HA-2.2M Dataset Construction
HA-2.2M comprises 2.2 million action-language episodes reconstructed from heterogeneous human videos, aggregating content from HowTo100M, Ego4D, Epic-Kitchens, and Something-Something-V2. The pipeline applies successive filtering and reconstruction steps: coarse filtering to isolate manipulation-relevant hand videos, perspective and background reconstruction to recover image-aligned 3D hand motion with MANO-style pose estimation, and fine filtering to segment temporally coherent atomic manipulation episodes, each aligned with concise action language annotation.
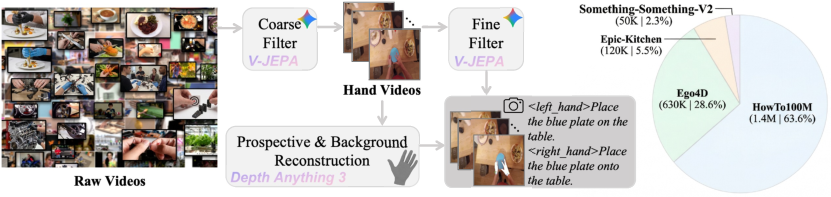
Figure 1: HA-2.2M curation pipeline transforms raw human videos into hand-centric action-language episodes, providing diverse manipulation priors.
This dataset enables learning manipulation priors from broad and diverse human interactions rather than being restricted to sparse and costly robot demonstrations. Notably, the final clips are curated to correspond to meaningful, temporally-coherent primitives, rather than arbitrary windows or passive hand movements.
MoT-HRA: Hierarchical Vision-Language-Action Architecture
MoT-HRA implements a mixture-of-Transformer architecture, explicitly factorizing action generation into three coupled experts:
- Vision-Language Expert: Predicts embodiment-agnostic 3D spatial trajectories via autoregressive generation from multimodal context.
- Intention Expert: Generates MANO-style hand-pose sequences as latent intention priors, implemented as conditional flow-matching over spatial plans.
- Fine Expert: Maps intention-aware representations to embodiment-specific robot actions, enabling downstream control adaptation.
A shared-attention trunk supplies multimodal context, while read-only key-value transfer supports knowledge insulation, preventing destructive interference between human-motion prior learning and robot policy adaptation. The attention masking ensures hierarchical modularity: upstream spatial and intention representations are visible to downstream modules, but shielded from downstream losses.
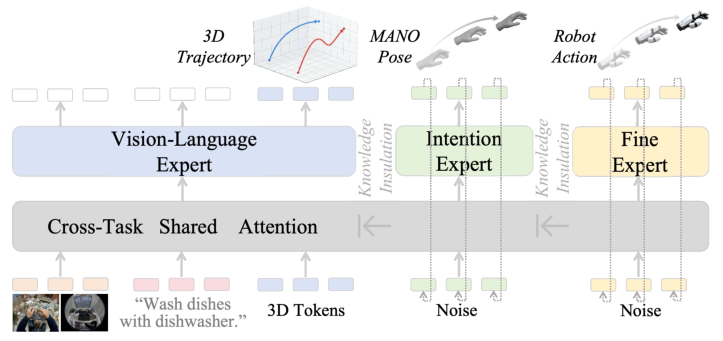
Figure 2: MoT-HRA architecture enables separate spatial grounding, intention modeling, and robot action generation with knowledge insulation.
Quantitative and Qualitative Results
Hand Motion Generation
MoT-HRA achieves superior quantitative performance on held-out Ego4D and OakInk datasets for hand motion generation, outperforming prior methods (Being-H0, VITRA) on metrics such as average displacement error (ADE), dynamic time warping (DTW), wrist rotation error, and finger joint rotation error. Improvements are most significant in wrist alignment and articulated pose accuracy, substantially reducing artifacts like wrist jitter and implausible finger poses.
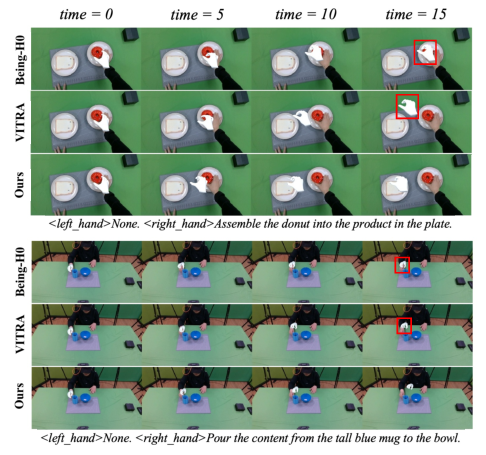
Figure 3: MoT-HRA generates stable, plausible hand motions, with baselines often exhibiting wrist jitter and pose inconsistencies.
Robotic Manipulation Benchmark
MoT-HRA is evaluated on SimplerEnv-WidowX, a benchmark testing control robustness under distribution shifts (illumination, background, viewpoint). The model achieves the highest average success rates across multiple tasks (Spoon, Carrot, Stack, Eggplant), with pronounced gains in tasks requiring precise spatial grounding. Ablation studies validate that the hierarchical decomposition and knowledge insulation monotonically improve both manipulation and motion metrics.
Real-World Robot Experiments
MoT-HRA demonstrates consistent and effective performance on real robots equipped with both parallel grippers and dexterous hands, completing long-horizon manipulation tasks under out-of-distribution object and scene variations. The approach reliably transfers human-intention priors to robot manipulation, outperforming strong baselines (π0, GigaBrain-0).
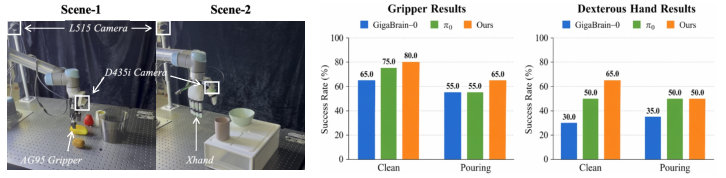
Figure 4: Real-world robot evaluation confirms robust control under varied embodiment and object distributions.
Architectural Ablations
Critical ablations verify the contribution of each architectural component: spatial trajectory grounding, intention expert, and knowledge insulation. Removing any element degrades both hand-motion plausible generation and manipulation task success rates. Explicit 3D spatial grounding stabilizes downstream control; intention expert is essential for coordinated wrist and finger trajectories; knowledge insulation mitigates destructive interference, particularly in multitask or heterogeneous training.
Practical and Theoretical Implications
The hierarchical approach enables efficient transfer of manipulation priors from massive unlabeled human demonstration corpora, reducing reliance on costly robot-specific data. Practically, it scales robotic policy learning toward open-domain tasks and diverse embodiments, with improved robustness under visual and distribution shifts. Theoretically, it suggests that modeling intention abstractions—distinct from executable robot actions—can be a fundamental inductive bias for vision-language-action systems, enabling reusable manipulation scaffolds across modalities and downstream policies.
Limitations remain in data quality, ambiguous hand-object contact modeling, and coverage of highly dynamic or long-horizon planning tasks. Further work should improve data verification, expand embodiment coverage, and enhance failure detection.
Conclusion
This paper introduces HA-2.2M, a large-scale dataset of human demonstration episodes, and MoT-HRA, a hierarchical VLA model leveraging structured human-intention priors for robotic manipulation. The methodology achieves state-of-the-art plausibility in hand motion generation and robust manipulation control, validated across simulation and real robot deployments. Hierarchically decomposing manipulation intent enables scalable pretraining and transfer, with implications for open-world robotic policy learning and future embodied AI systems.