- The paper introduces a novel triplet decomposition strategy that divides image editing into task, target, and understanding capability, enhancing reasoning granularity.
- It generalizes editing via a meta-task decomposition into five fundamental primitives, enabling compositional transfer to complex, unseen instructions.
- The RL-based CoT-Editing Consistency Reward aligns reasoning with visual outcomes, achieving a 15.8% improvement in overall edit efficacy.
Instruction-based image editing with unified multimodal models is fundamentally constrained by the granularity and generalization of model reasoning. Existing approaches leveraging Chain-of-Thought (CoT) paradigms typically either focus on enhancing fine-grained understanding of the editing process—often through ad hoc spatial or semantic cues—or attempt to improve broad instruction following, but rarely achieve both in tandem. Meta-CoT systematically addresses this dichotomy by decomposing the image editing process along two axes: a triplet-based paradigm capturing (task, target, understanding capability), and a meta-task abstraction that operationalizes the decomposition into a minimal, compositional set of edit primitives.
Methodology
Triplet Decomposition for Fine-Grained Reasoning
Meta-CoT introduces a triplet decomposition strategy in the CoT reasoning process, partitioning any image editing operation into three orthogonal dimensions: editing task, editing target, and required understanding capability. The triplet is explicitly traversed in three reasoning steps—Task Summary, Task Thinking tailored to the task class, and Target-wise Editing Traversal. This design allows for explicit conditioning of the edit operation not only on task semantics but also on individualized target instances, as illustrated in Meta-CoT’s flow.
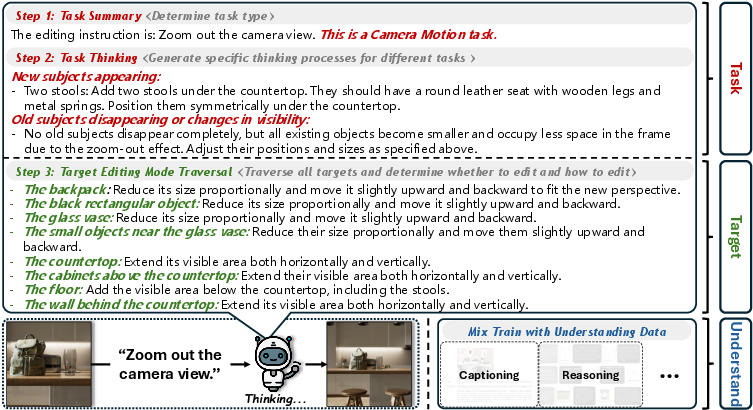
Figure 1: Meta-CoT's triplet decomposition cascades task identification, task-specific reasoning, and target-wise edit traversal for precise, interpretable editing operations.
During training, the model is exposed to diverse visual understanding tasks, ensuring the learned representations capture all modalities essential for comprehensive triplet mastery. The authors show theoretically that their decomposition reduces task complexity and leads to increased mutual information per entropy in the CoT reasoning chain.
To ensure cross-task transfer, Meta-CoT further abstracts the "task" dimension into a set of five fundamental meta-tasks (addition, deletion, replacement, camera motion, and position change). Each high-level editing instruction is mapped onto a minimal sequence of such primitives, allowing complex tasks to be realized as compositions of meta-tasks.

Figure 2: Task-level editing intents are decomposed into sequences of minimal meta-tasks, increasing expressivity and enabling compositional generalization.
This meta-task decomposition ensures that if the model is trained only on the set of meta-tasks, it can generalize by composition to any complex or unseen instruction type, as demonstrated empirically. Unlike prior works which require full supervision for every edit type, this approach achieves strong generalization while minimizing task coverage.
CoT-Editing Consistency Alignment
A significant issue in previous models is the inconsistency between the model’s reasoning and the ultimate visual realization. To mitigate this, the authors propose the CoT-Editing Consistency Reward, which uses a vision-LLM evaluator (Qwen2.5-VL) to score semantic alignment between the CoT reasoning trace and the resultant edit. The reward model is tuned to match human preference via Pearson correlation optimization, then used in an RL phase (Flow-GRPO) to bind CoT trace semantics to edit outcomes.
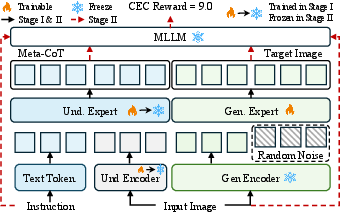
Figure 3: The two-stage Meta-CoT training pipeline first applies SFT for reasoning and editing, then refines edit consistency via RL with the CoT-Editing Consistency Reward using Flow-GRPO.
This approach directly addresses cases where the model might nominally “solve” an instruction but via semantically incongruent steps, thereby increasing the transparency and reliability of reasoning-driven editing.
Training and Data Infrastructure
The pipeline for Meta-CoT data construction leverages a combination of LLM- and VLM-mediated instruction parsing, consistency checking, and triplet/meta-task decomposition. Human and automated verification stages ensure high-quality alignment between visual edits and reasoning traces, while large-scale, heterogeneously sourced data—augmented with specialized unrealized edit instructions—support robust training for both SFT and RL phases.
Empirical Analysis
Quantitative Results
Meta-CoT demonstrates substantial quantitative improvements over strong baselines. On a 21-task image editing benchmark encompassing a diverse range of tasks (spatial, semantic, logical, multi-instructional), Meta-CoT yields a 15.8% improvement in overall edit efficacy versus editing-only training counterparts, as measured by instruction-following, consistency, naturalness, and artifact suppression. The RL stage, which enforces CoT-edit result alignment, provides further refinement.
A notable claim is that training solely on the five meta-tasks suffices to reach generalization performance competitive with exhaustive task-type supervision. The composition mechanism is validated through ablation: reducing the number of meta-tasks causes measurable degradation, while increasing above five provides negligible marginal gain—empirically supporting the sufficiency and minimality of the selected basis.
Meta-CoT also surpasses prior unified models on ImgEdit and other public benchmarks, with significant relative improvements over backbone models such as Bagel and Qwen-Image.
Ablation and Analysis
Meta-CoT's benefits are isolated and supported by ablative studies, including:
- The necessity of the “Task Thinking” step for robust instruction following.
- The critical dependence on large, diverse visual understanding data for high-quality CoT traces.
- Quantitative CoT-trace evaluations (using GPT-4.1) revealing direct correspondence between improvement in reasoning trace quality and downstream editing performance.
Qualitative Demonstrations
The model is qualitatively shown to better decompose multi-instruction edits, perform more logically sound edits in reasoning-dependent tasks, and more accurately localize or enumerate entities in instructions requiring counting or attribute manipulation.
Implications and Future Directions
The Meta-CoT paradigm offers a modular, theoretically motivated approach for aligning model reasoning and visual outcome in diverse editing scenarios. Its two-tiered decomposition addresses the central challenge of balancing granularity and generalization—both essential for deployable, instruction-driven image editing in open-ended real-world contexts. The use of a semantic reward aligned to the reasoning trace rather than only edit result introduces greater interpretability and reliability to the editing pipeline.
Practically, the meta-task composition scheme enables scalable extensibility: models can be adapted to novel or complex edits with minimal additional supervision. The approach may also serve as a template for other multimodal or hierarchical reasoning applications, where explicit decompositional reasoning aids both control and transfer. Further research could include extending decomposition strategies for text-to-video editing, compositional 3D edits, or more fine-grained multimodal attribute control. Notably, future work should resolve the relative degradation seen in text editing tasks—potentially through hybrid reasoning architectures employing separate context traces for non-visual targets.
Conclusion
Meta-CoT provides a rigorous and versatile solution to the dual challenge of enhancing reasoning granularity and improving compositional generalization in unified image editing models. The combination of triplet and meta-task decomposition, together with a tailored reasoning-consistency RL objective, establishes new empirical baselines and theoretical guidelines for reasoning-aware, controllable image generation and editing.