- The paper introduces XGRAG, a framework that leverages graph perturbations to provide causally-grounded explanations for KG-based retrieval-augmented generation.
- It integrates entity deduplication and LightRAG to improve semantic consistency and achieve a 14.81% F1 improvement over text-based baselines.
- Experimental evaluations across diverse QA datasets demonstrate robust performance, scalability, and enhanced transparency in LLM reasoning.
XGRAG: A Framework for Explaining Knowledge Graph-Based Retrieval-Augmented Generation
Motivation and Context
Retrieval-Augmented Generation (RAG) architectures substantially improve the factuality of LLM outputs by grounding responses in retrieved external knowledge. Traditional RAG employs vector-based retrieval from unstructured text, but recent advances (e.g., GraphRAG) utilize Knowledge Graphs (KGs) as structured contextual sources, increasing semantic coherence and supporting reasoning via relational entity structures. However, the internal decision process of LLMs remains opaque, with prior explainability (XAI) approaches limited to text perturbations that fail to leverage KG structural information and cannot attribute output to specific graph components. XGRAG addresses this gap by introducing a causally-grounded, graph-native explanation framework tailored for KG-based RAG.
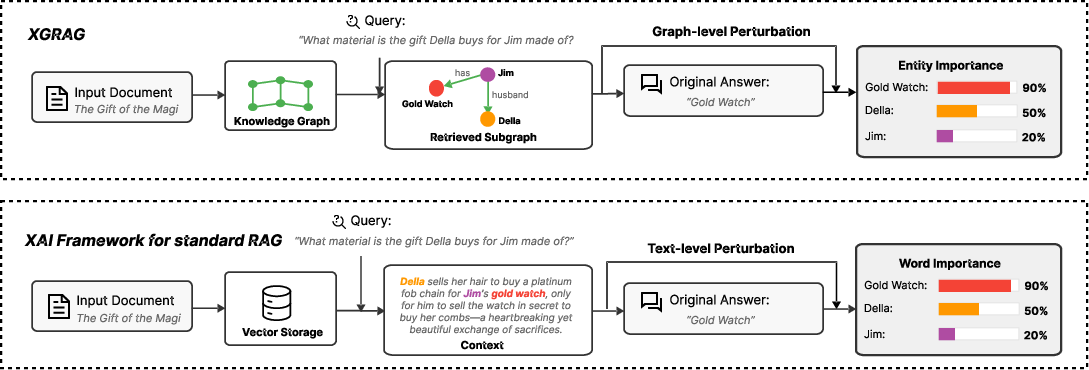
Figure 1: Comparison of XGRAG with text-based XAI for RAG; XGRAG perturbs KG components to expose their causal roles in answer generation.
System Architecture and Perturbation Strategies
XGRAG's design extends a standard GraphRAG pipeline with dedicated modules for explanation: GraphRAG backbone, entity deduplication, perturbation, and explainer. The backbone retrieves relevant subgraphs for a query; entity deduplication consolidates synonym nodes for semantic consistency; the perturber invokes graph-native strategies (node removal, edge removal, and synonym injection) to generate counterfactual subgraphs; the explainer quantifies causal importance via semantic shift in output, measured using cosine distance between baseline and perturbed answers.
A critical aspect is computational scalability. Standard GraphRAG implementations are prohibitively expensive for perturbation-based analyses due to repeated query execution. XGRAG leverages LightRAG for efficient retrieval, enabling practical multi-run perturbation. Entity deduplication improves robustness by consolidating aliases, ensuring that influence attribution is not diluted across semantically-equivalent nodes.
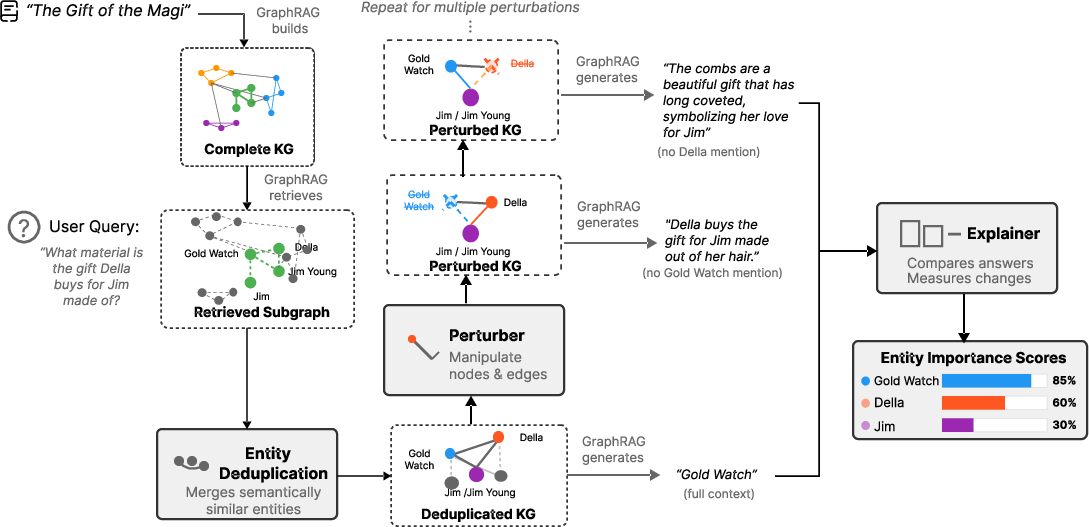
Figure 2: XGRAG architecture illustrating retrieval, deduplication, perturbation, and explanation flow for graph-based context.
Experimental Evaluation
Evaluations span three QA datasets with diverse narrative and factual complexity—NarrativeQA, FairyTaleQA, and TriviaQA. Story and question types are classified to probe robustness: stories are grouped (simple narrative, complex plot, abstract concept), and questions are divided by cognitive demand (factual recall vs. inferential reasoning). The ground truth is operationalized via semantic similarity between retrieved graph units and the model's answer.
XGRAG consistently achieves superior explanation precision compared to baseline RAG-Ex (text-level perturbation). Node-level perturbation outperforms all granularities, with an F1 improvement of 14.81% over baseline and corresponding gains in Mean Reciprocal Rank and P@k metrics. Explanations exhibit strong correlation with centrality measures, validating structural alignment. Performance is robust across LLM backbones (Gemma3-4b, Mistral-7b, DeepSeek-r1-7b, Llava-7b, Llama3.1-8b), confirming model-agnostic generalization.

Figure 3: Example of XGRAG-generated importance scores for nodes; influential entities are accurately isolated for a specific QA instance.
Scalability, Efficiency, and Ablation
Efficiency assessments reveal that LightRAG integration is essential; legacy GraphRAG incurs unsustainable token and API costs, whereas XGRAG-LightRAG maintains the required throughput and latency. Ablation studies establish the necessity of entity deduplication (removal degrades F1 performance), and node removal perturbation consistently delivers highest explanatory accuracy relative to other strategies.
Practical and Theoretical Implications
XGRAG's architecture enables transparent auditing in safety-critical domains, supporting both developer debugging (identifying problematic graph components) and user trust (providing causal reasoning). By directly perturbing graph structures, the framework reveals the evidential pathways most influential in generated answers. The correlation with graph topology supports hypotheses about structural bottlenecks in KG-driven reasoning. XGRAG is extensible to other structured retrieval contexts (e.g., causal graphs, ontologies), with scalability contingent on further KG optimization.
Speculation and Future Directions
Extension to multilingual corpora, proprietary LLMs, and domain-specific KGs is a natural next step. Improving ground truth assessment (beyond semantic similarity) and harnessing human annotation or advanced judge LLMs could further refine the evaluation pipeline. Scaling to large graphs and real-time applications may demand optimized deduplication and perturbation algorithms. Integration of causal analysis over graph paths, rather than simple node/edge removal, may yield deeper interpretability.
Conclusion
XGRAG constitutes an effective, causally-grounded explainability framework for KG-based RAG, outperforming text-based baselines and exhibiting robust generalization and structural alignment. Enhanced transparency in LLM reasoning over structured contexts is achievable, supporting both practical deployment and theoretical exploration of KG-centric retrieval and generation architectures (2604.24623).

