- The paper introduces KGRAG-Ex, a novel retrieval-augmented generation system that employs domain-specific knowledge graphs to enhance factual grounding and explainability.
- It constructs medical knowledge graphs using prompt-based extraction and graph traversal techniques to generate pseudo-paragraphs that guide corpus retrieval.
- Perturbation methods at node, edge, and sub-path levels reveal component contributions, significantly reducing computational overhead compared to traditional RAG-Ex systems.
KGRAG-Ex: Explainable Retrieval-Augmented Generation with Knowledge Graph-based Perturbations
This paper introduces KGRAG-Ex, a novel RAG system designed to enhance both factual grounding and explainability by integrating structured KGs into the retrieval and generation pipeline. The system constructs a domain-specific KG using prompt-based information extraction, identifies relevant entities and semantic paths in the graph based on user queries, and transforms these paths into pseudo-paragraphs to guide corpus retrieval. The approach incorporates perturbation-based explanation methods to assess the influence of specific KG-derived components on the generated answers, thereby improving interpretability and reasoning transparency.
Knowledge Graph Construction and Retrieval
The system constructs a domain-specific KG, focusing on the medical domain, directly from raw textual data. The KG construction involves dividing each document into smaller chunks and using an LLM to extract factual information in the form of (Entity, Relationship, Entity) triplets, consistent with existing RAG studies. Each extracted entity (node) is assigned a semantic label, such as Disease, Body Part, or Medication, to enrich the graph with meaningful categories. This is illustrated in (Figure 1).
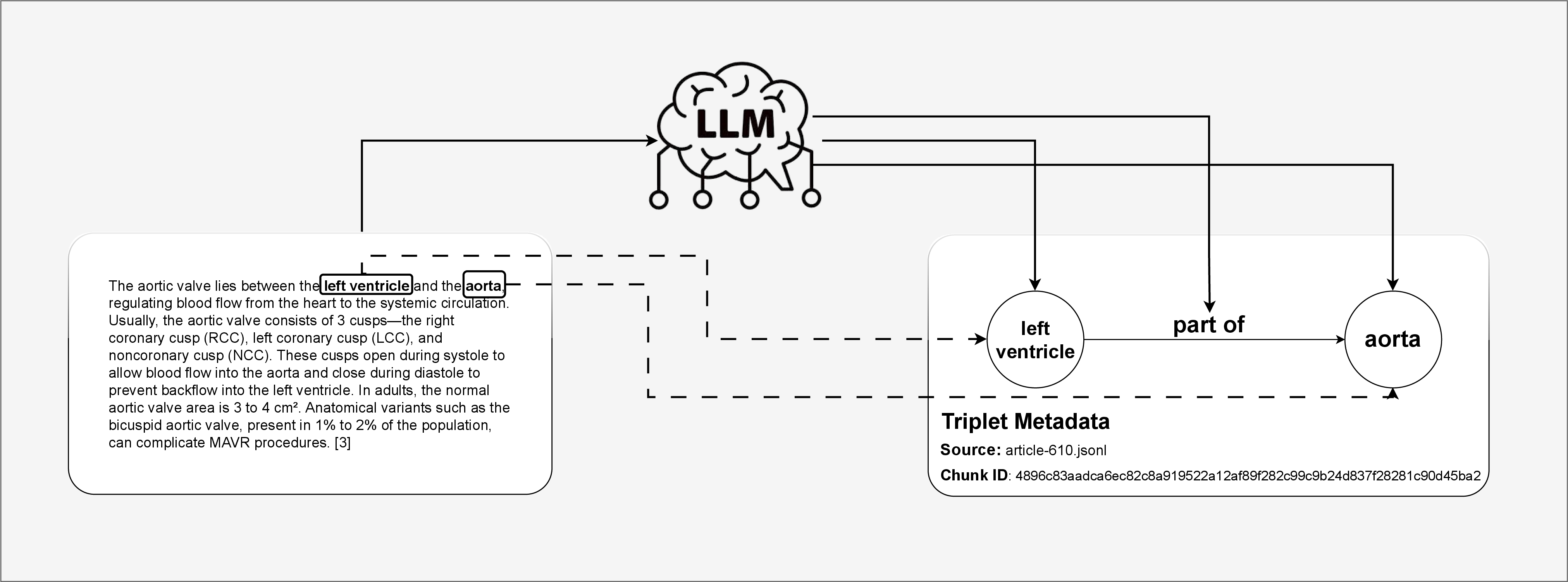
Figure 1: Triplet extraction.
To retrieve relevant information from the KG, the system first extracts a set of (Entity, Relationship, Entity) triplets from the user query using an LLM. Entities mentioned in the query are identified and grounded to their corresponding nodes in the graph. The system then performs graph traversal to determine the shortest paths between the relevant entities, uncovering semantically meaningful subgraphs. An example of the pipeline is shown in (Figure 2).
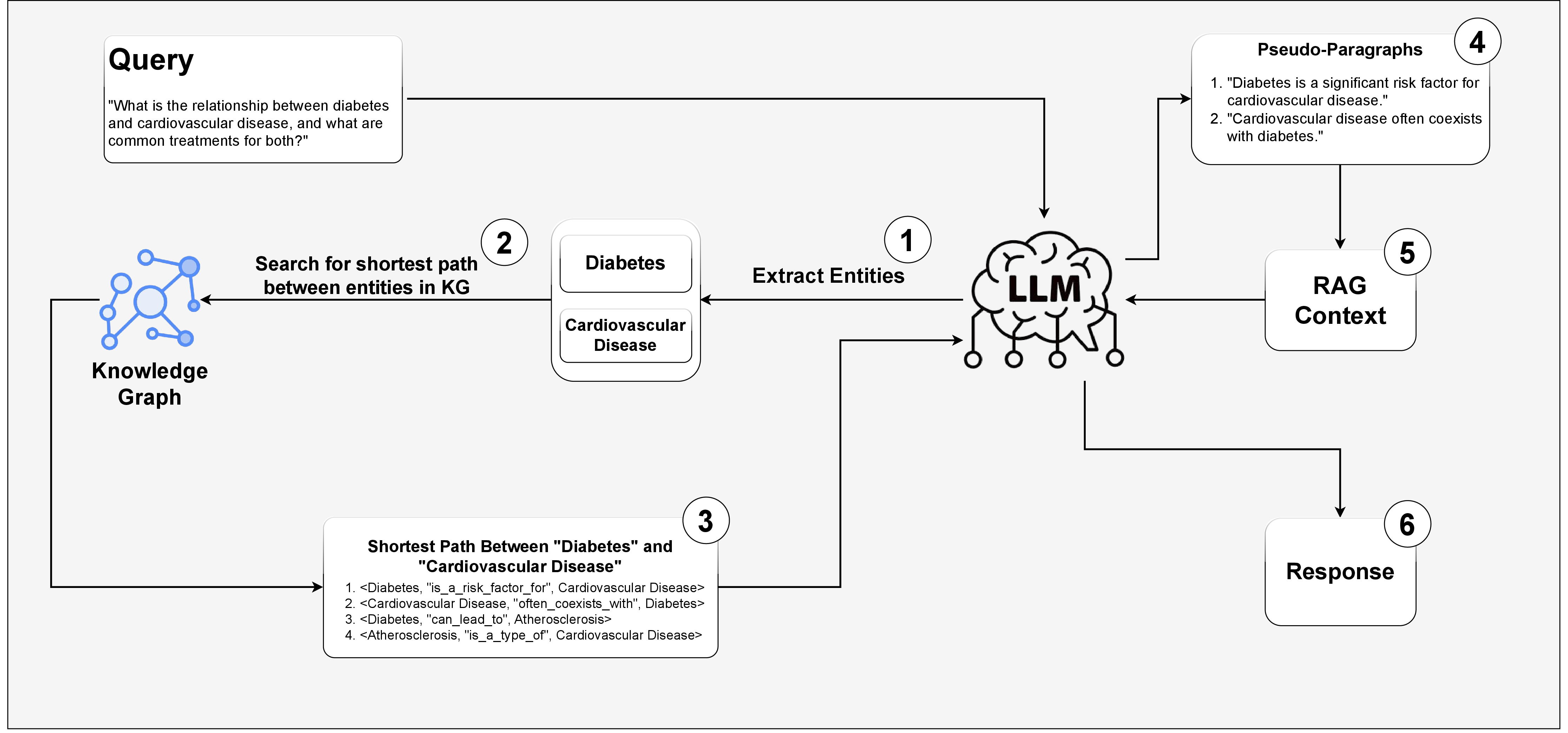
Figure 2: The proposed pipeline. Graph-level perturbations are applied at Step 3.
The system constructs a context by translating structured data into a form amenable to language-based models, generating pseudo-paragraphs from structured paths. These pseudo-paragraphs are concatenated to form a single context, providing a unified textual representation that reflects the overall semantics of the structured source. The resulting textual context is then used as input for RAG, providing relevant and comprehensive information to improve the performance of downstream language tasks.
Explanations via Knowledge Graph Perturbations
To generate explanations, the system applies perturbations to the retrieved KG context by selectively removing elements at varying levels of granularity, including individual nodes, edges, or entire sub-paths. By systematically deleting specific elements and observing the resulting changes in model predictions or outputs, the system infers their importance.
Node-level perturbations involve removing one node from the derived path while keeping all other elements unchanged. Edge-level perturbations correspond to the removal of a single edge from the derived path, disconnecting two semantically related nodes. Sub-path-level perturbations remove a sub-path, typically a triplet, from the derived path. The system then provides two types of explanations: one targeted at end-users and another more technical explanation for developers.
Experimental Evaluation
The evaluation utilized the StatPearls corpus along with two established benchmarks: MedMCQA and MMLU. The experiments were designed to address research questions related to system sensitivity to each perturbation method, the correlation between perturbed graph elements and their relative positions, the identification of critical node types, and the relationship between graph centrality metrics and the significance of elements within the derived paths.
Experiments showed that sub-path removals generally have the strongest impact, followed by node and edge removals. The results also suggest that perturbations occurring closer to the beginning of the path are more likely to cause significant changes in the generated output. The distribution of critical changes by node labels across both datasets is shown in (Figure 3).
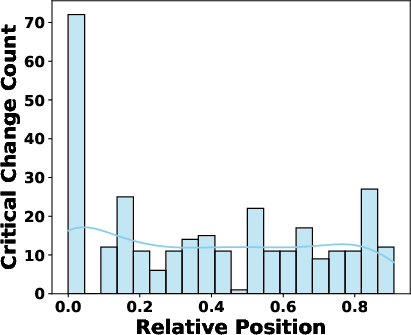
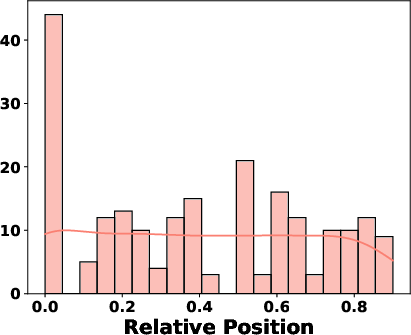
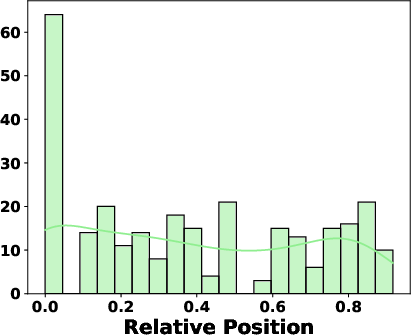
Figure 3: Node Positions
In terms of node significance via label analysis, Disease, Symptom, and Body Part consistently emerged as the most impactful across both MMLU and MedMCQA. The relative rank distribution of important nodes across two datasets is illustrated in (Figure 4).
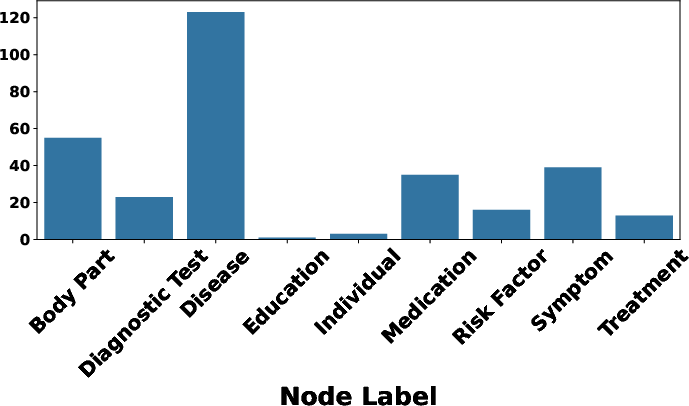
Figure 4: MMLU
The relative rank distribution of important edges across two datasets is illustrated in (Figure 5).
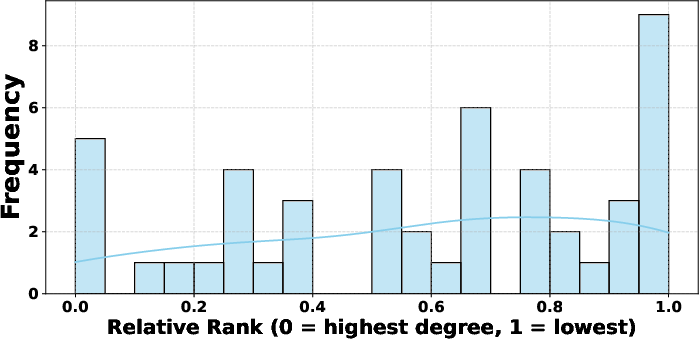
Figure 5: MedMCQA
The relative rank distribution of important sub-paths across two datasets is illustrated in (Figure 6).
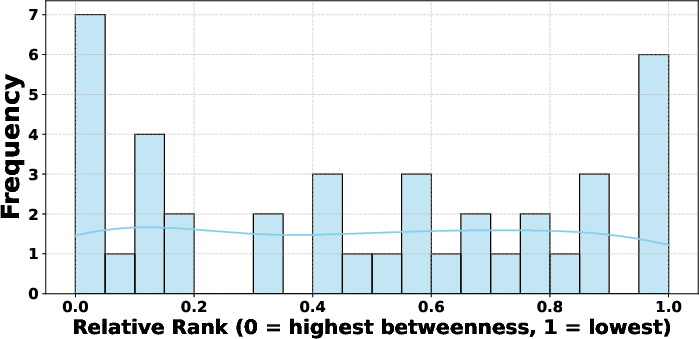
Figure 6: MedMCQA
The paper also includes a comparative analysis of KGRAG-Ex and RAG-Ex, demonstrating that KGRAG-Ex results in a significant reduction in the number of LLM calls and tokens consumed, leading to lower computational overhead and reduced pricing costs. The LLM calls and tokens for RAG-Ex and KGRAG-Ex across two datasets, MMLU and MedMCQA, are compared, highlighting the efficiency gains of KGRAG-Ex.
Conclusion
The paper presents KGRAG-Ex, a RAG system that leverages KGs to improve both factual grounding and interpretability. The authors demonstrate how different components of the KG contribute to the reasoning process of the model through graph perturbation-based explanation methods. The paper concludes that future work will explore extending the approach to larger and more diverse datasets, and investigating alternative perturbation techniques.