- The paper demonstrates that the agentic reasoning system, linking evidence directly to decision nodes, achieved 79.6% overall concordance with expert consensus.
- It employs a structured multi-step approach with a dedicated skill library and deterministic scoring to manage heterogeneous, longitudinal patient records.
- The study highlights system robustness across varied documentation densities and record lengths, while noting areas for improvement in retrieval integration.
Cohort Construction, Annotation, and Evaluation Dataset
The study systematically collated and processed longitudinal records for 811 multiple myeloma patients, encompassing 44,962 documents and over 1.3 million laboratory values from the TUM University Hospital. Document density per patient exhibited high variance, mirroring the complexity inherent to heterogeneous real-world clinical documentation. Long-term disease trajectories were more prominent at TUM relative to the shorter observation windows in MIMIC-IV, reinforcing external validity through institutional contrast.
Expert annotation established the reference standard, with two oncologists double-annotating each patient and adjudication executed by a senior haematologist. Direct agreement covered 65.2% of cases, while adjudication resolved most of the remainder. Inter-rater reliability diminished as complexity escalated, reflected by Cohen’s κ values (Level~1: 0.69, Level~3: 0.57). Most disagreements were clinically insignificant or interchangeable, not true errors. These rigorously engineered cohorts and annotation procedures enabled clinically grounded assessment of longitudinal reasoning.
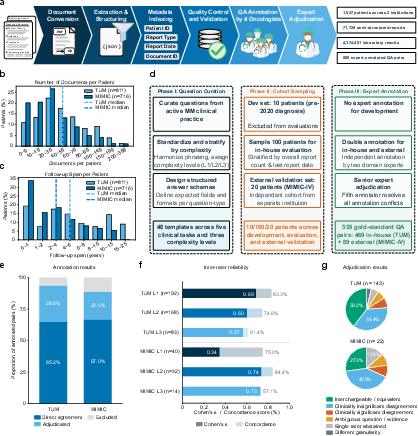
Figure 1: Data pipeline, cohort construction, annotation reliability, and complexity distributions underpinning clinically rigorous benchmarking.
Experimental Design: Agentic System Architecture and Comparator Framework
The agentic clinical reasoning system featured structured, traceable multi-step reasoning over temporally distributed, heterogeneous patient records. The architecture comprised:
- Skill library with indexed question-type-specific clinical reasoning protocols.
- Ordered tool-use plans with predefined stopping rules, ensuring explicit evidence retrieval and synthesis.
- Structured memory state supporting integration of task requirements, intermediate evidence, and domain knowledge.
- Dedicated toolset, including report/lab retrieval filters and deterministic scoring systems.
Each intermediate step linked evidence directly to decision nodes, guaranteeing answer verifiability and source traceability. In contrast, comparator systems encompassed Simple RAG (single-pass dense retrieval), Iterative RAG (multi-round query rewriting with hybrid retrieval), and Full Context (context-packed input) paradigms, all utilizing the same local 120B parameter LLM backbone for data privacy compliance.
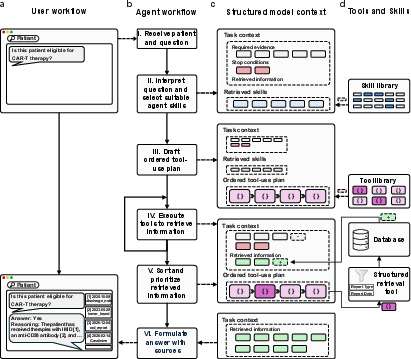
Figure 2: Agentic system workflow and internal architecture enabling structured, evidence-linked longitudinal reasoning.
Cohort Selection and Stratified Evaluation
Patient cohorts were stratified according to diagnosis, documentation density, and trajectory duration, yielding 100 patients (469 annotated pairs) for primary evaluation and 20 patients (89 pairs) for external validation. Sampling controlled for heterogeneity in documentation and disease extent, thereby facilitating evaluation across real-world clinical variability and diverse institutional contexts.
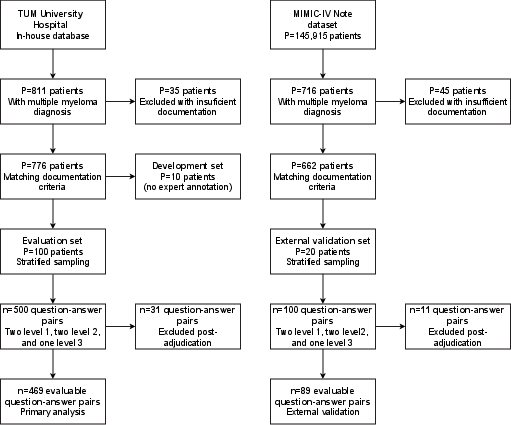
Figure 3: Inclusion flow and stratified sampling yielding representative evaluation cohorts for the reasoning benchmark.
Performance Analysis: Concordance, Complexity, and Context
Agentic reasoning achieved 79.6% overall concordance with adjudicated expert consensus, surpassing both Iterative RAG (75.4%) and Full Context (75.8%) by statistically significant margins (+4.2 and +3.8 pp, p<0.01). On external validation (MIMIC-IV, English records), agentic reasoning retained superior ranking (84.9%) across shifting documentation language, structure, and institutional workflow.
Performance degradation was observed with increasing question complexity: Level~1 (single-record lookup) yielded 86.1%, Level~3 (criteria-based synthesis) dropped to 65.1%. However, the agentic system’s advantage expanded monotonically with complexity, peaking at +9.4 percentage points over Full Context in Level~3 tasks (p=0.032). Stratification by record length revealed convergence for short trajectories, but agentic reasoning remained robust in the top decile of record length (>541k characters), where non-agentic systems declined sharply.
Citation sufficiency analysis confirmed that nearly all concordant agentic responses were fully supported by retrieved source documents; discordant outputs were typically attributable to incomplete retrieval or integration failures. External validation preserved system ranking and complexity gradient across disparate environments.
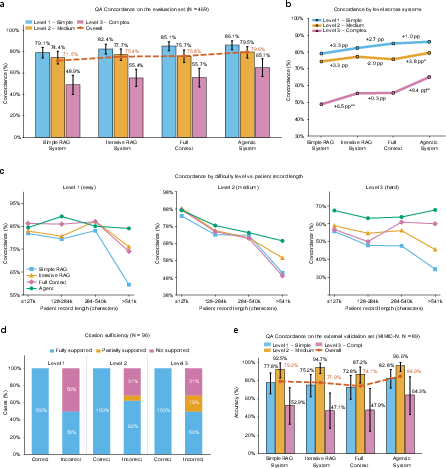
Figure 4: System concordance across complexity levels, record length strata, citation sufficiency, and external validation.
Error Profile and Failure Modes
Aggregate system error rates (12.2%) were comparable to expert disagreement rates (13.6%), yet error severity distributions were reversed: 57.8% of system errors were clinically significant versus only 18.8% for experts. Most agentic system failures during simple tasks resulted from incomplete retrieval—amenable to improvements in retrieval engineering. For complex, multi-criterion synthesis tasks, errors originated from evidence misintegration, reflecting intrinsic limitations of current long-context LLMs’ attention mechanisms, as documented in the literature [liu2024lost]. The skill library, as confirmed by ablation analysis, contributed the largest individual performance boost, reducing overall concordance by 30 percentage points if omitted.
Clinical and Practical Implications
The agentic approach demonstrated statistically robust gains in concordance for tasks and patient trajectories where manual chart synthesis is most resource-intensive and decision-critical. Its error rates fell within bounds of human annotation variability, but higher clinical consequence of errors underscores the necessity of prospective validation for clinical deployment. Methodological rigor, including external cohort transferability and stratified sampling, supports generalizability claims.
Theoretical implications are pronounced: agentic reasoning externalizes evidence decomposition, weighting, and protocol synthesis, moving beyond the limitations of both simple retrieval and brute-force context packing that saturate at a performance ceiling. The documented attention deficit in long-context models constrains brute-force approaches and highlights the necessity of hybrid agentic reasoning architectures in real-world clinical settings.
Speculation on Future Directions
Advances in LLM contextual attention and retrieval robustness are expected to narrow gaps in citation sufficiency and evidence integration. System-level improvements should focus on further optimizing skill selection, retrieval precision, and deterministic scoring integration. Larger-scale prospective trials—interactive with treating clinicians—are necessary to validate direct impacts on clinical workflow and patient outcomes, moving beyond retrospective concordance assessment.
Integration with multi-modal sources and dynamic EHR interfaces may further augment reliability and domain coverage. Benchmarking against proprietary frontier models remains challenging under strict institutional privacy constraints, yet comparative studies across backbone architectures indicate that agentic advantage varies with baseline LLM reasoning capacity.
Conclusion
Agentic clinical reasoning systems, with explicit evidence-linked longitudinal synthesis, outperform retrieval-augmented and full-context methods in concordance with expert annotations—especially as task complexity and record length escalate. System-level error rates match human annotation variability, but the clinical impact of residual errors mandates prospective validation. Structured agentic architectures externalize core medical reasoning operations, enabling verifiable and traceable outputs in complex, heterogeneous medical documentation environments.
Future developments should target improvements in retrieval and evidence integration, contextual attention, skill library optimization, and prospective clinical efficacy trials, with the expectation that agentic reasoning will become indispensable for high-stakes multi-source medical decision support.