- The paper presents a novel clinical error detection method that integrates retrieval-augmented generation with multi-agent debate to address terminology substitution errors.
- It employs a three-tiered pipeline featuring expert agents using partitioned evidence pools and a safety layer that mitigates false positives.
- Experimental results show significant improvements over baseline models, achieving 69.13% accuracy and balanced ROC–AUC through adversarial cross-examination.
Retrieval-Augmented Multi-Agent Debate for Clinical Error Detection: An Essay on BLUEmed (2604.10389)
Introduction
The problem of terminology substitution errors in clinical notes—where linguistically plausible but clinically incorrect terms are inadvertently introduced—has persisted as a significant challenge for automatic medical documentation error detection. Traditional systems based on typographical and grammatical rules are insufficient for such errors, as substitutions maintain local syntax and surface coherence while undermining clinical semantics. Strategies leveraging LLMs and retrieval-augmented architectures have gained prominence, but existing single-agent or rule-based approaches remain limited in robustness and fail to address the full complexity of multi-faceted medical reasoning. The BLUEmed framework addresses this gap by integrating source-partitioned hybrid Retrieval-Augmented Generation (RAG) with a rigorous multi-agent debate protocol, grounded by a domain-specific cascading safety layer to suppress common false-positive behaviors endemic to automated clinical error detection.
System Architecture and Methodology
BLUEmed introduces a three-tiered pipeline organized around evidence retrieval, adversarial clinical reasoning, and safety-driven adjudication. Each clinical note is decomposed into aspect-based sub-queries, enabling fine-grained evidence retrieval using dense, sparse, and live online strategies fused via Reciprocal Rank Fusion. Critical to the system's design, evidence is partitioned by knowledge source: one expert operates over Mayo Clinic documents, the other over WebMD, minimizing correlated retrieval bias and enforcing multi-perspective verification.
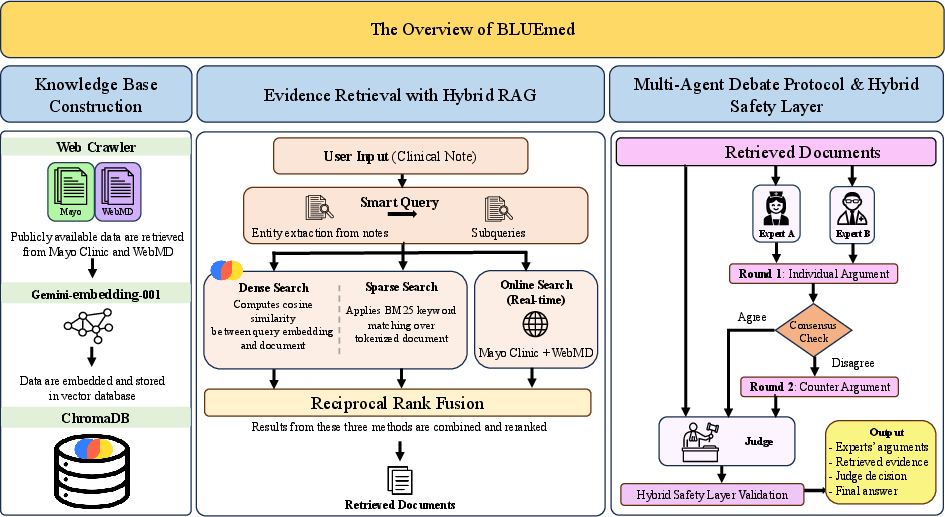
Figure 1: BLUEmed’s system architecture, combining hybrid RAG, source-partitioned expert debate, adjudicator cross-verification, and a hybrid safety layer for robust medical error detection.
By decoupling experts' evidence pools, BLUEmed enforces heterogeneity in expert clinical perspectives and reasoning trajectories. Two domain-specialized expert agents independently assess the note, supporting their conclusions with sourced evidence and structured clinical arguments. Disagreement triggers a second round of cross-argumentation, after which an adjudicator judge—blinded to the original note and acting solely on the debate transcript and cross-source evidence—delivers the provisional classification.
The post-hoc hybrid safety layer performs critical structural and heuristic validations: enforcing extraction of explicit term-pair errors, overriding decisions in light of dual-expert consensus, and filtering cases aligned with systematic false-positive motifs (e.g., process gaps, side-effect discourse, or hierarchical term substitutions with no change in clinical meaning).
Experimental Protocol and Baselines
The BLUEmed system is rigorously evaluated on the MEDEC [abacha2025medec] benchmark, focusing on error flagging (binary discrimination between correct and incorrect clinical narratives). Experiments are structured around comparisons to two established baselines: (1) RAG-Single agents (using either Mayo Clinic or WebMD) operationalize classic retrieve-then-predict paradigms; (2) LLM-Debate applies multi-agent debate without retrieval augmentation, permitting adjudication based solely on agent-derived arguments.
To ensure comparative integrity, experiments are conducted under both zero-shot and few-shot prompting, leveraging diverse backbone LLMs including GPT-4o, GPT-5.2, Gemini-2.0-Flash, and instruction-tuned open-source models (Qwen3, Llama 3.2). Evaluation metrics include accuracy, F1, precision, recall, ROC–AUC, and PR–AUC, computed with minimal variability across repeat trials due to deterministic sampling and output structure controls.
Results
BLUEmed consistently surpasses retrieval-only and debate-only baselines across all key metrics. Using GPT-4o, BLUEmed attains 69.13% accuracy, ROC–AUC of 74.45%, and PR–AUC of 72.44% under few-shot conditions—markedly outperforming single-agent (accuracy <59%, ROC–AUC ≤63%) and retrieval-unaugmented debate approaches (accuracy <56%, ROC–AUC <60%).
This is attributable to the synergistic effect of retrieval augmentation and adversarial debate: single-agent retrieval systems are susceptible to recall collapse under few-shot prompting and error propagation from pool-specific evidence bias, while multi-agent debate without evidence grounding suffers from inflated recall, poor precision, and high false-positive rates. BLUEmed’s partitioned retrieval framework promotes evidentiary diversity, and the debate protocol’s counter-argumentation corrects over-flagging tendencies, stabilizing both sensitivity and specificity.
Impact of Model Capacity and Prompting
Large proprietary models (Gemini-2.0-Flash, GPT-4o) consistently outperform smaller open-source competitors. For instance, Gemini-2.0-Flash achieves up to 69.18% accuracy and 71.44% ROC–AUC zero-shot; lower-capacity instruction-tuned models collapse to near-chance discrimination (ROC–AUC ≈50–54%) with diminished recall and precision, often returning unstructured outputs incompatible with downstream parsing and safety checking. This underscores the necessity of advanced instruction-following capacity and clinical comprehension within each debate agent.
Few-shot prompting catalyzes performance improvements in BLUEmed but is detrimental to RAG-Single. The structure and shared context of exemplar guidance benefit multi-perspective debate (accuracy +1.5 points for GPT-4o) but induce over-conservativeness and recall decay in single-agent settings.
Practical and Theoretical Implications
BLUEmed demonstrates that robust terminology error detection in EHRs requires both adversarial cross-examination and evidence-grounded argumentation, with context separation minimizing collective hallucination risk. The system’s most consequential advance is the explicit partitioning of the evidence pools across expert agents, empirically confirming the orthogonality and complementarity of retrieval augmentation and multi-agent protocol structures. The hybrid safety layer, combining structural parsing and domain heuristics, materially mitigates false positives from semantic drift and documentation redundancy.
Diagnostically, BLUEmed’s pipeline embodies principles applicable to a wide range of medical auditing, chart review, and legal compliance tasks. Its reliance on consumer-oriented KBs (Mayo Clinic, WebMD) facilitates transparency but may restrict coverage for rare, specialist, or newly approved terminologies, thereby highlighting the centrality of KB curation for clinical-grade systems.
Limitations and Future Directions
BLUEmed’s best accuracy (69.13%) remains below conservative deployment thresholds for high-stakes autonomous review. The cost profile (∼12k prompt tokens per case, ∼$0.04 at GPT-4o rates) may be prohibitive in high-throughput or latency-bound environments. The evaluation dataset comprises expert-injected errors, which, while systematically diverse, may not exhaust the expression and distribution of naturally occurring notes. Future work should investigate scalability to specialist KBs, custom ensemble generation for rare case types, real-world chart review feedback loops, and expansion to multilingual, multimodal, and specialty domains.
Conclusion
BLUEmed establishes a new standard for error detection in clinical NLP by integrating hybrid RAG, source-partitioned expert debate, blinded adjudication, and a domain-driven safety net. Its empirical superiority over classical and recent baselines underscores the necessity of combining adversarial multi-agent reasoning with authoritative evidentiary grounding. While not yet sufficient for independent deployment, BLUEmed is well-positioned as an auditable, clinician-in-the-loop triage tool and offers a paradigm for future AI systems requiring robust, evidence-auditable, multi-perspective reasoning in safety-critical domains.