- The paper presents a novel CanMT corpus and a multidimensional evaluation schema to benchmark culture-aware machine translation in literary texts.
- It demonstrates that scaling and test-time reasoning improve translation fidelity, while exposing persistent semantic bias and a knowledge-application gap.
- The study emphasizes the importance of reference translations and specialized cultural adaptation to enhance MT performance across diverse contexts.
Culture-Aware Machine Translation in LLMs: Benchmarking and Systematic Investigation
Motivation and Background
The paper "Culture-Aware Machine Translation in LLMs: Benchmarking and Investigation" (2604.24361) provides a comprehensive evaluation of culture-centered machine translation (MT) capabilities in LLMs. Unlike prior benchmarks that focus on narrow domains (recipes, idioms, poetry) or informative datasets (Wikipedia), this work centers on literary novels—texts that encode diverse, contextually complex culture-specific items (CSIs). The authors introduce the CanMT parallel corpus and a theoretically grounded evaluation schema aimed at diagnosing the limits and strengths of LLM-based translations in scenarios heavily mediated by cultural knowledge.
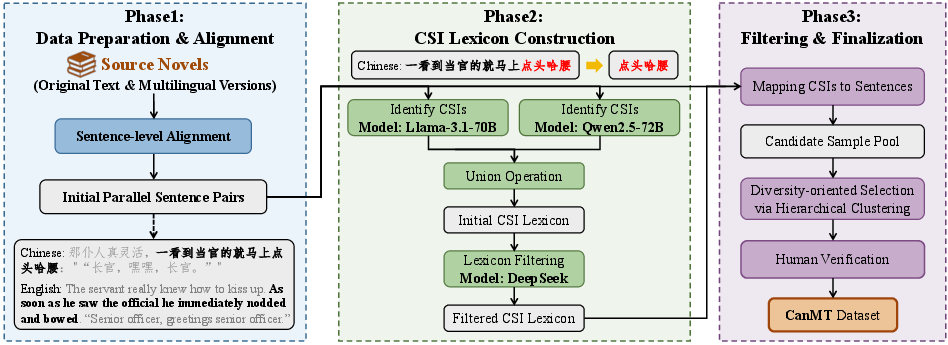
Figure 1: Overview of the CanMT dataset construction pipeline, including data preparation, sentence alignment, CSI-based sentence selection, and diversity-oriented sample selection via clustering and human verification.
Dataset Construction and Cultural Diversity
CanMT is constructed from professionally translated classic novels spanning twelve translation directions, designed for cross-cultural coverage. The pipeline utilizes sentence alignment with Vecalign, lexicon expansion via multiple LLMs (LLaMA-3, Qwen2.5), and diversity enforcement using hierarchical clustering on LaBSE embeddings. Manual filtering ensures high fidelity in both parallelism and translation quality.
Figure 2: Representative novels from diverse cultural backgrounds used as sources for building CanMT.
This approach yields a corpus rich in pragmatic, stylistic, and cultural variation, surpassing the limits of genre-focused or Wikipedia-derived datasets. Notably, the selection of multiple translations per novel and robust human annotation allows for evaluation of transferability across widely divergent sociocultural contexts.
Evaluation Framework: Multi-Dimensional Cultural Translation Quality
The paper formalizes translation evaluation along five dimensions rooted in translation studies: contextual accuracy (CA), cultural adaptation (CAD), functional equivalence (FEQ), fidelity (FID), and naturalness (NAT). Each axis captures distinctive aspects of culture-aware MT, moving beyond adequacy and fluency to interrogate target-oriented adaptation, pragmatic function, semantic preservation, and native idiomaticity.

Figure 3: Overview of the evaluation dimensions adopted in this study, including their definitions, illustrative sources, and representative examples of better and worse translations for each dimension.
The 7-point Likert scale rubric is operationalized with both human and automatic (GPT-5-nano) scoring, validated through inter-annotator (H–H τ) and model–human (M–H τ) rank correlations.
Experimental Results: Model Scaling, Reasoning, and Paradigm Effects
Systematic evaluation across open-source, proprietary, specialized MT, and production engines reveals several strong claims:
- Scaling correlation: For open-source LLMs, translation quality improves monotonically with parameter count (e.g., Qwen2.5-7B < Qwen2.5-72B).
- Reasoning boost: "Test-time Scaling Reasoning" (think mode) consistently yields incremental gains, with the strongest improvements in fidelity.
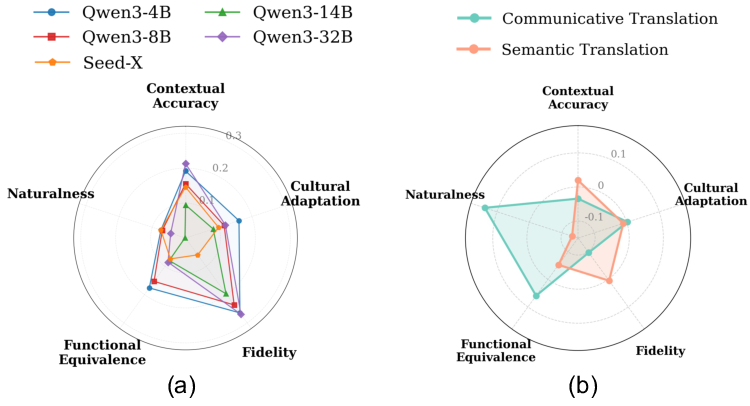
Figure 4: a) Improvement from "Test-time Scaling Reasoning" across evaluation dimensions. b) Comparison of strategies across evaluation dimensions.
- Constraint effects: Communicative translation enhances naturalness and functional equivalence, while semantic translation stabilizes fidelity and contextual accuracy. Default model outputs show strong semantic bias, confirmed via cosine similarity with constrained outputs.
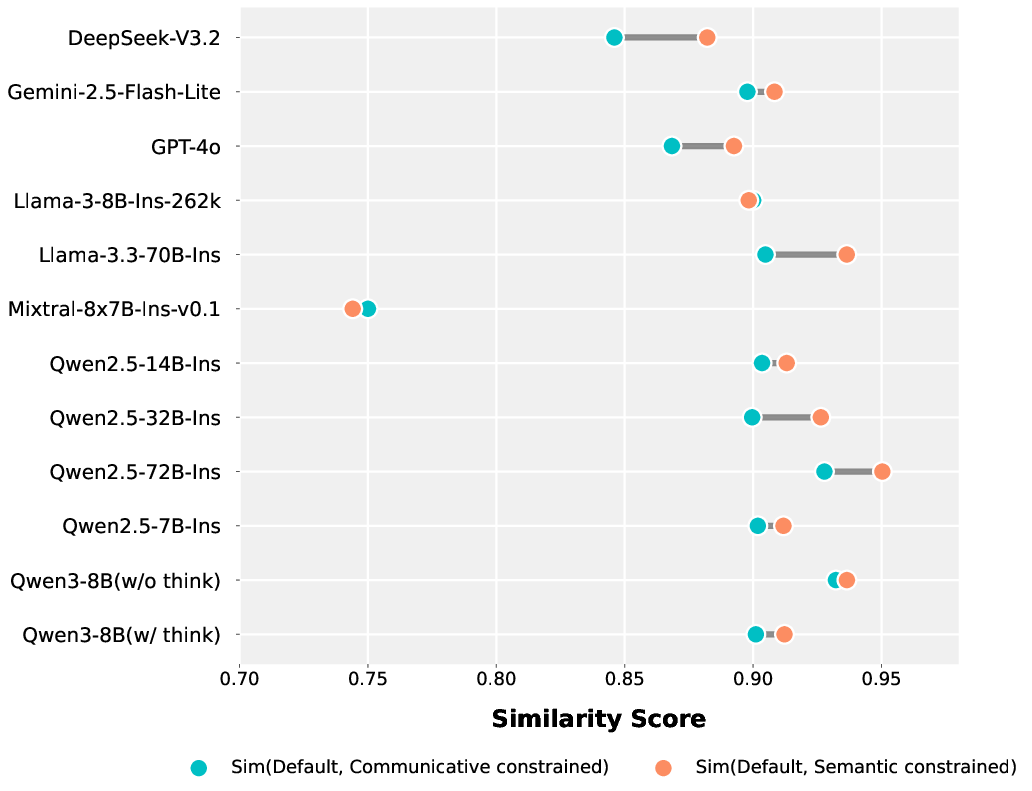
Figure 5: Similarity of default translations to semantic and communicative-constrained translations.
The taxonomy of CSIs shows a strong difficulty hierarchy: geographic/ecological terms are reliably translated, material culture and organizations fare moderately, but language symbols—abstract, non-compositional entities—consistently yield the lowest scores on both CA and CAD metrics. This result highlights the inherent challenges LLMs face in handling linguistic symbolism and deep cultural referents.
Knowledge-Application Gap and Reference Translation in Evaluation
Probing with automatically generated CSI translation questions reveals that correct knowledge does not guarantee appropriate application in final translation output—a persistent "knowledge-application gap". Sentences where models correctly identify CSI renderings achieve higher scores, but a significant subset of knowledge-correct cases still yield subpar translations.
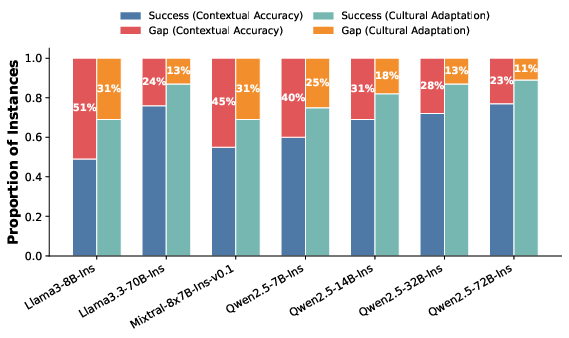
Figure 6: Distribution of CSI translation scores within the knowledge-correct subset. The lower segments indicate scores ≥4 in the corresponding dimension.
Furthermore, the inclusion of reference translations substantially improves the alignment between LLM "judge" scores and human evaluation across all dimensions, underscoring the necessity of reference-based calibration for reliable culture-aware MT evaluation.
Implications and Future Directions
Empirical findings demonstrate that current LLMs, even with increased scale and reasoning augmentation, exhibit a default orientation toward semantic translation and struggle with highly abstract, culture-dependent references. The knowledge-application gap highlights unresolved issues in extraction and operationalization of cultural knowledge during generation.
Practical implications include:
- Enhanced prompts and inference-time reasoning to mitigate the knowledge-application gap.
- Corpus expansion beyond literary fiction, with discourse-level evaluation to capture broader cultural meaning construction.
- Integration of automatic evaluation with reference translations for more robust metric calibration.
- Development of models or sub-modules specializing in context-sensitive cultural adaptation, potentially leveraging latent cross-lingual transplantation and explicit knowledge retrieval mechanisms.
Theoretically, the paper suggests that scaling alone does not fully solve semantic-pragmatic misalignment, and that progress in culture-aware MT requires advances in both model design and evaluation methodology.
Conclusion
"Culture-Aware Machine Translation in LLMs: Benchmarking and Investigation" (2604.24361) establishes a rigorous benchmark and evaluation schema for culture-centric MT. Strong numerical results show marked scaling and reasoning improvements, yet reveal persistent semantic bias and difficulty with abstract CSIs. The importance of reference translations for evaluation reliability and the knowledge-application gap in cultural translation pose future challenges. The CanMT corpus and the multidimensional evaluation system provide a foundation for advancing research on cultural adaptability in LLMs and specialized MT systems.