- The paper demonstrates that LLMs exhibit significant representational collapse, often defaulting to canonical Western metaphors instead of culturally nuanced reasoning.
- It employs quantitative embedding analyses (e.g., cosine distances and t-SNE) alongside qualitative reviews to assess how cultural prompts shape metaphorical concepts.
- Findings indicate that persona conditioning alone is insufficient for genuine cultural pluralism, highlighting the need for training on more diverse corpora.
Introduction
This study systematically investigates whether LLMs exhibit genuine cultural reasoning or perform cultural translation when prompted to generate culturally grounded creative content. Unlike prior works that focus on multilinguality or question-answering to evaluate cultural knowledge, this research analyzes the structural properties of LLM-generated metaphors across five abstract concepts and six cultural conditions, utilizing both quantitative embedding analyses and qualitative inspection. By dissecting metaphor generation, the research probes the extent to which LLMs can act as culturally pluralistic agents or if they merely adapt a dominant (frequently Western) conceptual framework with culture-specific surface forms.
Methodology
The authors focus on metaphor generation for five abstract concepts (Time, Death, Success, Family, Freedom) across the U.S., Japan, China, India, Brazil, and a culture-unspecified (Default) condition. For each (concept, culture) pair, 20 metaphors are sampled using a carefully constructed prompt designed to discourage stereotypes and clichés. All outputs are in English to isolate semantic phenomena from translation artifacts.
Metaphors are embedded in a 3072-dimensional space using a Gemini embedding model, allowing for geometric analyses of cross-cultural and intra-cultural diversity. Three main analyses are performed:
- Intra-cultural Semantic Diversity: Assessed by average pairwise cosine distances within a set of metaphors generated for the same concept and culture.
- Conceptual Space Geometry: Visualized using t-SNE to examine the separation and clustering of concepts under each cultural condition.
- Cultural Defaultism: Tests whether LLMs' "culture-agnostic" outputs are semantically aligned with a specific (typically Western) culture, using centroid distances and Fisher randomization for significance assessment.
Intra-Cultural Semantic Diversity and Representational Collapse
The intra-cultural diversity analysis reveals substantial asymmetry in metaphor variety depending on both concept and culture. Certain pairs, such as Death–India (average cosine distance 0.066) and Death–China (0.076), exhibit severe representational collapse, where output diversity is minimal and the model repeatedly produces the same culturally-salient metaphor (e.g., the clay pot–air analogy in India and the “fallen leaf returning to roots” in China).
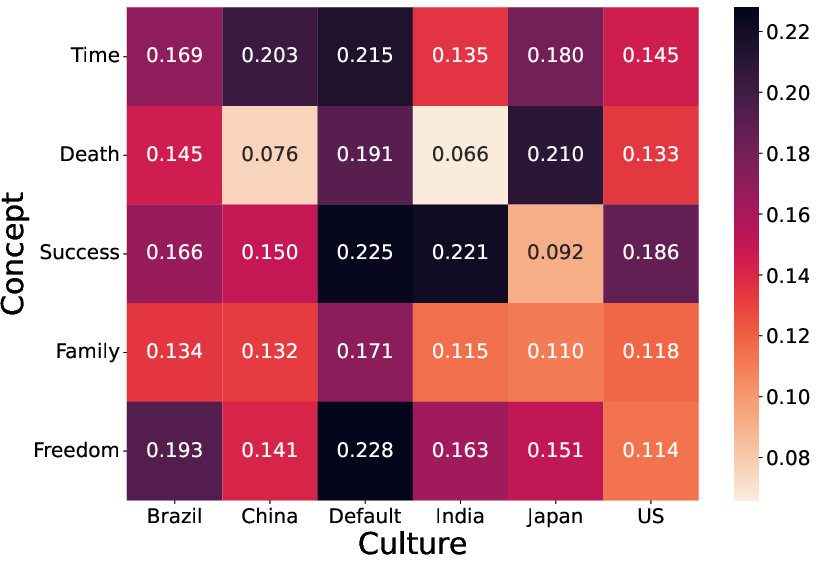
Figure 1: Within-culture and -concept diversity of metaphors, with higher values indicating broader semantic range and lower values signifying representational collapse.
Conversely, for some settings such as Freedom–Default (0.228), diversity is markedly higher, indicating that the model generates a broader array of metaphors when unconstrained by strong, known tropes. Importantly, the Default condition sometimes supports higher creativity than culture-specific prompts, suggesting that persona conditioning can, in some cases, narrow the representational space due to over-reliance on dominant or prototypical cultural mappings.
Geometry of Conceptual Embedding Spaces
t-SNE analyses uncover that cultural prompts significantly reshape the organization of concepts in embedding space. In the Default and Brazil scenarios, the metaphors for each concept form well-separated clusters, whereas in China, India, Japan, and U.S., conceptual clusters are more compact with increased proximity between certain concepts (e.g., Success and Family), reflecting culturally contingent overlaps in conceptualization.
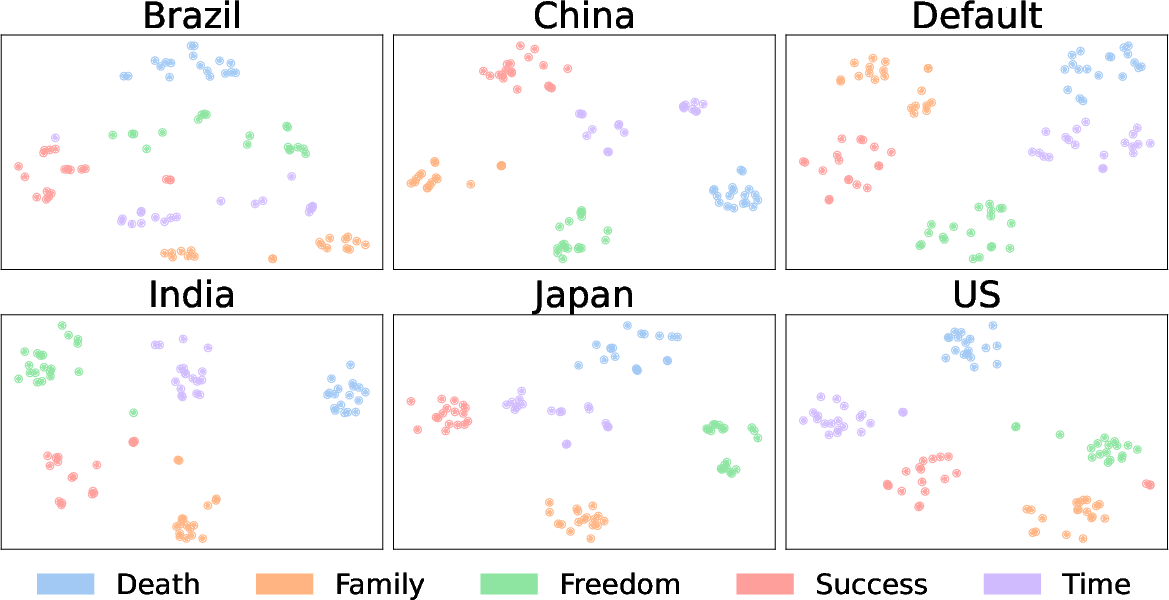
Figure 2: t-SNE visualization of metaphor embeddings across cultures, illustrating how culture conditions modulate the relational geometry among abstract concepts.
While some concept-concept relationships are robust across cultures (e.g., separation of Freedom), others are highly sensitive to cultural context, leading to tighter or looser clustering of metaphorical representations. These findings demonstrate that LLMs' abstract reasoning is at least partially modulated by cultural prompts, yet such modulation does not universally produce distinct cultural worldviews.
Cultural Defaultism and Asymmetric Baselines
The analysis of cultural defaultism shows that the culture-agnostic prompt yields metaphor clusters that are more closely aligned to the U.S., especially for Time, Death, and Freedom. Statistical tests confirm this alignment is significant (p<0.05 to p<0.001 for many comparisons), indicating that the Default condition is not a neutral or equidistant baseline but instead reflects the dominant culture(s) represented in the training corpus. For other concepts such as Family, no significant alignment with any single culture is found, and for certain concepts, Default aligns closer with non-U.S. cultures.
This finding indicates that LLMs may act as cultural translators, re-skinning Western conceptual structures with localized phrases, rather than constructing meaning within diverse cultural frameworks when not explicitly prompted.
Qualitative Analysis of Metaphor Content
Review of low-diversity outputs reveals frequent repetition of canonical metaphors tightly linked to a specific culture, confirming that the embedding-based findings are reflected at the surface linguistic level. In contrast, high-diversity cases lack a dominant trope and utilize a wider range of culturally-resonant themes. This suggests that when LLMs possess only a small set of prototypical examples for a (concept, culture) pairing, representational collapse is likely, whereas a richer set of cultural references enables more varied and creative analogy production.
Implications and Future Directions
The study demonstrates that prompt-based cultural conditioning is insufficient to ensure culturally heterogeneous reasoning in LLMs. The persistent Western defaultism and representational collapse observed have several implications:
- Practical Risks: LLM-powered tools for education, co-creative writing, or cross-cultural ideation may homogenize or inadequately reflect cultural perspectives, functioning as paraphrasing tools rather than authentic collaborators.
- Theoretical Implications: The results call into question the assumption that multilingual or cultural persona prompting imbues models with meaningful cultural worldviews, highlighting the need for auditing conceptual and geometric representation, not just surface outputs.
- Directions for Model Development: Fostering culturally nuanced AI requires augmented training on diverse, non-Western conceptual corpora, as well as new metrics that quantify representational pluralism in embedding space. Human evaluation remains necessary to supplement embedding-based audits, given that certain nuances may not be captured geometrically.
Limitations include the focus on metaphors (excluding other forms of creative or logical reasoning), operation in only English, and exploration of a single LLM. Expanding to other models and including pragmatic stylistic evaluation would further illuminate the depth and limitations of cultural reasoning in LLMs.
Conclusion
This audit finds that LLMs exhibit substantial representational collapse and a persistent bias toward Western cultural frameworks under default and even some culture-specific prompts. Although models can replicate salient metaphors from underrepresented cultures, they rely heavily on canonical examples, and persona conditioning alone is insufficient for cultural pluralism. Developing genuinely inclusive AI co-creators will require systematic advances in data, modeling, and evaluation methodology to move beyond translation toward computational reasoning that authentically reflects the worldviews of diverse cultures.