MEMCoder: Multi-dimensional Evolving Memory for Private-Library-Oriented Code Generation
Abstract: LLMs excel at general code generation, but their performance drops sharply in enterprise settings that rely on internal private libraries absent from public pre-training corpora. While Retrieval-Augmented Generation (RAG) offers a training-free alternative by providing static API documentation, we find that such documentation typically provides only isolated definitions, leaving a fundamental knowledge gap. Specifically, LLMs struggle with a task-level lack of coordination patterns between APIs and an API-level misunderstanding of parameter constraints and boundary conditions. To address this, we propose MEMCoder, a novel framework that enables LLMs to autonomously accumulate and evolve Usage Guidelines across these two dimensions. MEMCoder introduces a Multi-dimensional Evolving Memory that captures distilled lessons from the model's own problem-solving trajectories. During inference, MEMCoder employs a dual-source retrieval mechanism to inject both static documentation and relevant historical guidelines into the context. The framework operates in an automated closed loop by using objective execution feedback to reflect on successes and failures, resolve knowledge conflicts, and dynamically update memory. Extensive evaluations on the NdonnxEval and NumbaEval benchmarks demonstrate that MEMCoder substantially enhances existing RAG systems, yielding an average absolute pass@1 gain of 16.31%. Furthermore, MEMCoder exhibits vastly superior domain-specific adaptation compared to existing memory-based continual learning methods.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple guide to “MEMCoder: Multi‑dimensional Evolving Memory for Private‑Library‑Oriented Code Generation”
What is this paper about?
This paper looks at how AI code generators struggle when asked to use a company’s private, in‑house code libraries. These libraries aren’t public, so the AI didn’t see them during training. The authors introduce MEMCoder, a system that helps the AI learn how to use these private libraries by building and updating a “memory” of practical tips and examples as it works—without retraining the model.
What questions are the researchers trying to answer?
The paper focuses on three main questions:
- Can adding “usage guidelines” (practical tips) to normal documentation help AI write correct code with private libraries?
- Does MEMCoder, which learns from its own successes and mistakes over time, work better than other memory/continual‑learning methods?
- Which parts of MEMCoder (task-level memory, API-level memory, and the learning loop) matter most for the improvement?
How does MEMCoder work? (Explained in everyday language)
Think of coding with a new library like cooking with a new set of kitchen tools:
- The API documentation is like the tool manual: it tells you what each tool is for.
- But real cooking also needs know‑how: which tools to combine, in what order, and what common pitfalls to avoid. That’s what the paper calls “Usage Guidelines.”
MEMCoder adds these missing pieces using two simple ideas:
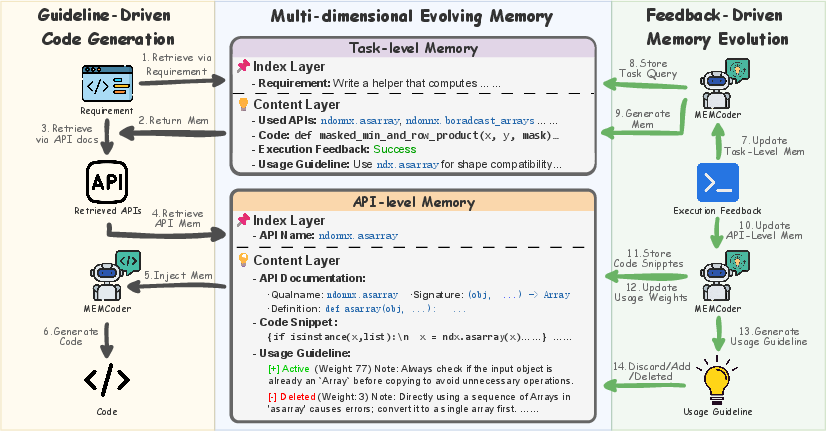
- Two kinds of memory (like two notebooks the AI keeps and updates)
- Task‑level memory: How to solve a whole type of problem by combining multiple APIs correctly. Example: “First resize the data, then apply the mask, then merge the result.”
- API‑level memory: How to use a single API safely and correctly. Example: “For function X, make sure all inputs have the same size and don’t swap the argument order.”
Each memory entry stores:
- The problem description, the code that was tried, whether it worked, the APIs used, and the short “tip” learned.
- A closed loop that learns from experience
- Generation: For a new task, MEMCoder pulls two sources:
- Static docs (the “manuals”) for relevant APIs.
- Relevant tips from its memory (the “notebooks”) about similar past tasks and the same APIs.
- It puts both into the AI’s prompt so the AI knows both what the APIs are and how to combine or call them safely.
- Execution: The generated code is run.
- Feedback: If it fails, the system looks at the error messages.
- Reflection: The AI then writes new or corrected tips (guidelines) based on what went wrong (or right).
- Update: These tips are stored, ranked by usefulness (like giving stars). Helpful tips get higher priority; less helpful ones get downgraded but kept, so past mistakes aren’t repeated.
Why not just use documentation? The authors show that even if you give the AI all the right docs (an “oracle” setting), it often still fails. That’s because docs tell you what each API does, but not:
- Task‑level patterns: which APIs to use together and in what order.
- API‑level traps: parameter constraints, boundary conditions, or subtle argument meanings.
MEMCoder fills both gaps.
What did they find, and why is it important?
- Static docs alone aren’t enough: Even with perfect docs, models did poorly on some benchmarks. On a challenging dataset (NumbaEval), giving full API specs barely improved results.
- Usage Guidelines make a big difference: When MEMCoder added evolving guidelines to the prompt, average pass@1 (how often the first answer passes all tests) increased by about 16 percentage points over strong retrieval baselines.
- Learns without retraining: MEMCoder improved performance by learning from runtime feedback and updating its memory—not by updating the model’s weights.
- Beats other memory methods: Compared to existing “continual learning” approaches that store experience, MEMCoder’s split memory (task-level + API-level) and feedback-driven updates handled private-library code better.
Why this matters:
- In real companies, private libraries change often. Keeping docs perfectly detailed is hard, and retraining big models is costly.
- MEMCoder is training‑free and plug‑and‑play. It can sit on top of existing AI coding systems and get better as it solves more tasks.
- It reduces common mistakes, like mixing up argument order or forgetting to align shapes, by injecting proven tips right when the AI writes code.
What’s the impact?
- Faster onboarding to private libraries: New or changing APIs become usable by the AI sooner because it learns practical patterns on the fly.
- Fewer bugs in generated code: Tips based on real errors help avoid repeated failures.
- Sustainable maintenance: Instead of manually writing lots of “how‑to” guides, the system builds and refines them automatically from execution feedback.
- Broad compatibility: MEMCoder improves several retrieval‑based setups, so teams can integrate it into their current workflows.
In short, MEMCoder turns API manuals into a smarter assistant by adding a living “notebook” of real-world usage tips—helping AI write correct code with private, evolving libraries.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and open questions that remain unresolved and could guide future research.
- External validity beyond two Python benchmarks: The study evaluates only on NdonnxEval (ndonnx) and NumbaEval (numba-cuda). It remains unclear how MEMCoder performs on real enterprise codebases, across other languages (e.g., Java/C++), or with multi-repository/private monorepos.
- Generalization to cross-library tasks: The framework organizes memory per target library; scenarios involving coordination across multiple private libraries or mixed public/private stacks are not evaluated or supported explicitly.
- Cold-start performance: The method depends on historical memory and self-derived guidelines; how well it performs on the first tasks when is empty, or when documentation is sparse/incomplete, is not quantified.
- Scalability of memory and retrieval: There is no analysis of memory growth, retrieval latency, and context-assembly costs as , , and the number of APIs scale to thousands, nor of index maintenance strategies over long-running deployments.
- Context length and selection policy: The framework concatenates documentation and multiple memory entries into the prompt; strategies for truncation, ranking, and selection under fixed token budgets are not detailed or ablated.
- Guideline reliability and verification: The LLM “Reflector” generates natural-language Usage Guidelines from single-task feedback. There is no independent validation that distilled guidelines are generally correct beyond the originating task, nor safeguards against spurious or coincidental patterns.
- Conflict resolution specifics: The “Discard/Delete/Add” routing is described conceptually; concrete criteria, algorithms, and thresholds for recognizing redundancy and contradictions are unspecified, raising reproducibility and stability questions.
- Weight update sensitivity: The credit assignment uses and step sizes /. Sensitivity to these hyperparameters and convergence/oscillation behavior under different task streams are not explored.
- Memory drift and bloat: Penalized guidelines are never removed (bounded below by ). Long-term effects on retrieval quality, memory size, and the risk of re-surfacing poor advice are not addressed.
- Non-deterministic and stateful APIs: The approach assumes objective execution feedback ( with traceback). Handling flaky tests, randomized behavior, stateful side effects, or environment-dependent outcomes is not discussed.
- Execution environment assumptions: Practicalities of sandboxing, resource/time budgets, and safety when executing generated code (especially for GPU/
numba-cuda) are not specified; failures due to environment misconfiguration versus logic errors are not disentangled. - Security and privacy governance: Persisting code snippets, traces, and guidelines from proprietary projects raises data governance questions (access control, PII/code leakage, retention policies) not addressed by the framework.
- Robustness to poor or misleading docs: The method relies on static documentation plus memory; behavior when docs are incomplete, outdated, or contradictory is unclear, including how the system arbitrates between doc-grounded rules and learned guidelines.
- Versioning and evolution handling: There is no mechanism for guideline/API version tagging or temporal scoping; how MEMCoder responds to API deprecations, signature changes, or breaking behavior across versions remains untested.
- Embedding and retrieval choices: The task-to-task similarity function and embedding models are not specified or ablated; domain-specific embeddings or hybrid lexical–semantic retrieval might yield different outcomes.
- Overhead and efficiency: Latency, compute overhead, and throughput impact from dual-source retrieval, reflection, and memory updates are not reported; trade-offs between performance gains and operational cost are unknown.
- Comparative baselines coverage: The evaluation omits stronger agentic/multi-iteration debugging or repair loops (e.g., iterative test-fix cycles, advanced execution-guided agents) and training-based adapters/fine-tuning, leaving the relative standing of MEMCoder to these paradigms unclear.
- Developer-in-the-loop workflows: How human feedback, code reviews, or manual curation integrate with memory evolution (e.g., approving/overriding guidelines) is not explored.
- Measures of solution quality beyond tests: Metrics focus on Pass@k and Exec@k; code readability, maintainability, and (for CUDA kernels) performance/efficiency are not evaluated, nor is unit test coverage robustness.
- Robustness to adversarial or noisy inputs: Potential “memory poisoning” from malformed tasks or adversarial code/feedback is not considered; detection and mitigation strategies are absent.
- Provenance and auditability: While code and feedback are stored, there is no mechanism to attribute successes/failures to specific guidelines or to audit the lineage of guideline evolution for debugging/compliance.
- Formalization of guidelines: Usage Guidelines are free-form text; the benefits of a structured representation (e.g., a DSL for API constraints and orchestration patterns) for validation, compositionality, and retrieval remain unexplored.
- Retrieval fusion details: How APIs proposed by doc-retrieval and task-memory union are ranked/fused and how conflicts between and are resolved in the final context are not specified or evaluated.
- Model-scale dependence: Results are on 7B–8B models; the effect of model size and family (smaller on-prem, or larger frontier models) on gains and memory utility is not studied.
Practical Applications
Practical Applications of MEMCoder’s Findings
Below are actionable, real-world applications that leverage the paper’s methods and results. Each item names potential sectors, tools/workflows, and key assumptions/dependencies that affect feasibility.
Immediate Applications
- Enterprise IDE code assistant for private libraries
- Sectors: Software, Finance, Healthcare, Manufacturing, Telecom
- Tools/workflows: IDE plugins (VS Code/JetBrains), dual-source retrieval (docs + task memory), task/API-level “Usage Guidelines” injection, inline fix-it hints
- Assumptions/dependencies: Local LLM or approved on-prem deployment; access to internal API docs; sandboxed execution for feedback; vector DB for memory; unit/integration tests or sample inputs
- CI/CD autorepair and guideline-curation bot
- Sectors: Software, DevOps, SRE
- Tools/workflows: GitHub/GitLab/Jenkins bots that (1) run failing tasks, (2) extract execution feedback, (3) update task/API-level guidelines, (4) propose patches in PRs with rationale
- Assumptions/dependencies: Safe, deterministic tests in CI; permission to run code in a sandbox; governance for storing execution logs and traces
- Living API documentation augmentation
- Sectors: Software platforms and SDK providers (internal platforms, infra teams)
- Tools/workflows: Doc site plugin that adds “Usage Guidelines,” “Known pitfalls,” and “Verified examples” sourced from evolving memory; cross-links to code snippets and test IDs
- Assumptions/dependencies: Existing doc build pipeline; human moderation for high-impact APIs; access control to avoid leaking sensitive traces
- Onboarding accelerator for new hires and teams
- Sectors: Enterprise software, consulting
- Tools/workflows: Team-specific “cheatsheets” auto-generated from successful tasks; playgrounds seeded with top-weighted guidelines and snippets
- Assumptions/dependencies: Curated memory bootstrapped from recent projects; role-based access to memory entries
- API adoption and migration assistant (deprecation-aware)
- Sectors: Software platforms, SDK owners, internal platform teams
- Tools/workflows: Detect deprecated APIs from docs; mine task-level patterns to generate migration recipes and refactoring suggestions
- Assumptions/dependencies: Clear deprecation metadata; staging environment to validate transformed code; coverage to confirm correctness
- Exception-to-constraint triage for support/SRE runbooks
- Sectors: SRE, Customer support, Internal platform support
- Tools/workflows: Map recurrent error traces to API-level constraints; recommend fixes and pre-validated patterns; auto-annotate runbooks
- Assumptions/dependencies: Stable error signatures; telemetry/log access; safe anonymization of traces
- Internal coding copilot for data/ML pipelines using proprietary libs
- Sectors: Data engineering, MLOps (e.g., proprietary Spark/Snowflake wrappers)
- Tools/workflows: Generate data transformations that comply with internal APIs; inject guidelines about schema, partitioning, boundary conditions
- Assumptions/dependencies: Representative datasets or mock inputs for execution feedback; guardrails for data privacy
- Security-hardening assistant for API misuse
- Sectors: AppSec, Fintech, Healthcare IT
- Tools/workflows: Promote guidelines that avoid insecure API combinations; export high-confidence rules to linters (e.g., Semgrep/CodeQL) or pre-commit hooks
- Assumptions/dependencies: Security review of guidelines before rule export; policy to prevent false positives/negatives in CI
- Customer/partner integration helper for proprietary SDKs
- Sectors: B2B SaaS, Platform vendors
- Tools/workflows: Share a scoped, sanitized guideline bundle with customers to improve SDK integration success rates; embed as a lightweight copilot in partner portals
- Assumptions/dependencies: Redaction of sensitive internals; clear licensing and support boundaries
- Lightweight research testbed for private-library code generation
- Sectors: Academia, R&D labs
- Tools/workflows: Reproducible pipelines for RAG+memory ablations, oracle vs. naive comparisons, pass@k and exec@k tracking
- Assumptions/dependencies: Open-access “private-like” benchmarks (e.g., NdonnxEval, NumbaEval) or internal analogs; local inference hardware
Long-Term Applications
- Organization-wide evolving memory service (“Guideline Graph”)
- Sectors: Enterprise platform engineering
- Tools/workflows: Central service with APIs/SDKs for IDEs, CI, doc sites; governance for retention, deduplication, conflict resolution, and weights
- Assumptions/dependencies: Cross-team identity/access management; data lifecycle policies; performance SLAs for retrieval
- API design feedback loop and analytics
- Sectors: SDK owners, Platform teams
- Tools/workflows: Dashboards surfacing frequent failure modes, conflicting guidelines, and workarounds; auto-suggested doc clarifications or API redesigns
- Assumptions/dependencies: Sufficient volume and diversity of tasks; product/process to route insights into roadmaps
- Autonomous refactoring at scale using learned patterns
- Sectors: Large codebases (monorepos), legacy modernization
- Tools/workflows: Bulk transformations guided by task-level patterns; staged verification; rollback and canary releases
- Assumptions/dependencies: High-fidelity tests; safe refactor tooling integrated with code owners; change management
- Privacy-preserving, federated guideline sharing across teams/orgs
- Sectors: Regulated industries (Finance, Healthcare), multi-subsidiary enterprises
- Tools/workflows: Differentially private or federated exchange of normalized guidelines (no raw code/logs); trust and policy layers
- Assumptions/dependencies: Legal/compliance approvals; robust anonymization; federation infrastructure
- Compliance and audit trails for AI-assisted coding
- Sectors: Finance, Healthcare, Public sector
- Tools/workflows: Provenance tracking (which guidelines influenced which code); auditable records for change justification and regulatory reviews
- Assumptions/dependencies: Immutable logging; retention policies; mapping guidelines to PRs/deployments
- Self-healing systems that learn from production incidents
- Sectors: SRE, High-availability services, Edge/IoT
- Tools/workflows: Controlled “repair agents” that propose hotfixes or config changes based on production traces; memory updated with postmortem outcomes
- Assumptions/dependencies: Strong sandboxing and approvals; incident rehearsal environments; guardrails for high-stakes systems
- Cross-modal hardware-in-the-loop (HIL) code generation for robotics/embedded
- Sectors: Robotics, Automotive, Industrial automation
- Tools/workflows: Closed-loop generation and validation against simulators/HIL rigs; API-level constraints capture real-time and safety boundaries
- Assumptions/dependencies: Deterministic simulators; safety certification processes; latency-aware retrieval and inference
- Curriculum generation and continuous training for developers
- Sectors: Education, Corporate L&D
- Tools/workflows: Auto-generated labs from common failure modes; adaptive lessons linked to evolving APIs; assessments tied to pass@k/exec@k metrics
- Assumptions/dependencies: Alignment with pedagogy; de-identified examples; periodic human curation
- Standardization and benchmarks for private-library code intelligence
- Sectors: Standards bodies, Research consortia
- Tools/workflows: Shared task suites, evaluation harnesses, and memory-evolution protocols for fair comparison across tools/vendors
- Assumptions/dependencies: Community buy-in; reproducibility infrastructure; neutral governance
- Policy frameworks for safe execution feedback and memory storage
- Sectors: Policy, Risk, InfoSec
- Tools/workflows: Best-practice guidelines on sandboxing, PII handling in traces, retention and access control for evolving memories
- Assumptions/dependencies: Cross-functional sign-off (Legal, Security, Eng); periodic audits and incident playbooks
Notes on feasibility and dependencies across applications:
- Execution feedback quality is pivotal; availability of robust tests or realistic sandboxes strongly impacts outcomes.
- Data privacy and governance must be addressed for storing code, traces, and guidelines; some use cases require redaction or DP/federated approaches.
- Integration overhead includes vector search infrastructure, doc ingestion, and IDE/CI connectors.
- Human-in-the-loop curation remains advisable for high-stakes domains to validate new or conflicting guidelines.
- Performance/computational constraints for on-prem LLMs may necessitate model distillation or caching strategies.
These applications directly reflect MEMCoder’s core innovations—multi-dimensional evolving memory, dual-source retrieval, and feedback-driven refinement—and leverage the demonstrated pass@1 gains (average +16.31%) to justify near-term deployments and guide longer-term platform and policy investments.
Glossary
- API-level memory: The memory dimension that captures per-API usage constraints, failure modes, and examples to ensure correct invocation. "task-level memory and API-level memory"
- APIFinder: A retrieval-based approach that locates relevant APIs or documents to assist code generation. "APIFinder~\cite{apifinder}"
- CAPIR: A RAG variant that leverages an LLM to rerank and filter retrieved APIs for higher precision before generation. "CAPIR~\cite{capir}"
- Content Layer: The memory component holding prompt-injected materials (e.g., code, feedback, guidelines) for generation. "Content Layer designed for prompt injection."
- Continual Learning (CL): A paradigm where models incrementally accumulate, retrieve, and reuse knowledge over time without full retraining. "representative memory-based Continual Learning (CL) frameworks."
- CUDA JIT compilation: Just-in-time compilation of CUDA kernels for high-performance GPU execution. "high-performance CUDA JIT compilation."
- Data contamination: Leakage where evaluation benchmarks or recent APIs appear in a model’s training data, inflating results. "to mitigate data contamination."
- Dense vector space: An embedding space used for efficient semantic retrieval of similar tasks or documents. "embedded into a dense vector space"
- DocPrompting: A method that prompts models with retrieved documentation to guide code generation. "DocPrompting~\cite{docprompting}"
- Dual-source retrieval mechanism: A retrieval strategy that pulls both static documentation and historical memory/guidelines. "employs a dual-source retrieval mechanism"
- Dynamic Cheatsheet: A memory-based method that curates reusable strategies and snippets across tasks at inference time. "Dynamic Cheatsheet~\cite{suzgun2025dynamic}"
- EpiGEN: A retrieval approach that decomposes tasks into subtasks/intents to improve API matching. "EpiGEN~\cite{epigen}"
- Exec@k: Metric measuring the probability that at least one of k sampled solutions executes without runtime errors. "Exec@k to measure basic executability."
- Execution trajectory: The sequence of generated code and its runtime outcomes used for reflection and learning. "analyzing the execution trajectory"
- ExploraCoder: A system that incorporates real-time execution feedback within a task to improve API usage. "ExploraCoder~\cite{exploracoder}"
- Feedback-Driven Memory Evolution: A module that refines and updates memory entries based on execution feedback. "Feedback-Driven Memory Evolution"
- Few-shot demonstrations: Stored example snippets or attempts used as in-context guides for future tasks. "serve as few-shot demonstrations"
- Guideline-Driven Code Generation: A generation pipeline that conditions on retrieved usage guidelines alongside documentation. "Guideline-Driven Code Generation"
- Index Layer: The memory component optimized for semantic indexing and retrieval of relevant entries. "Index Layer designed for semantic search"
- Instruction tuning: Fine-tuning LLMs on instruction-following datasets to improve adherence to prompts. "pretraining or instruction tuning"
- Knowledge cutoffs: The latest dates or releases covered by a model’s training data, after which new knowledge is absent. "knowledge cutoffs"
- LLM Reflector: The LLM component that distills, refines, and routes Usage Guidelines from feedback into memory. "the LLM Reflector"
- Multi-dimensional Evolving Memory: A structured memory storing both task-level and API-level guidelines that evolve over time. "Multi-dimensional Evolving Memory"
- NdonnxEval: A benchmark for private-library code generation centered on the ndonnx (ONNX-based) tensor library. "the NdonnxEval and NumbaEval benchmarks"
- NumbaEval: A benchmark for private-library code generation tasks involving numba-cuda and GPU kernels. "the NdonnxEval and NumbaEval benchmarks"
- ONNX: An open standard format/ecosystem for representing and running machine learning models across frameworks. "an ONNX-based tensor library."
- Oracle setting: An evaluation regime where all required documentation is perfectly injected to remove retrieval errors. "even in an Oracle setting where the complete set of required documentation is perfectly injected"
- Oracle study: An experiment designed to assess the upper bound of documentation-based assistance by injecting all specs. "we design an Oracle study."
- Pass@k: Metric estimating the probability that at least one of k sampled solutions passes all tests. "Pass@k using the unbiased estimator:"
- Private-Library-Oriented Code Generation: The task of generating code that correctly uses proprietary, project-internal APIs. "Private-Library-Oriented Code Generation"
- ReMem: A memory-based agent that retrieves, refines, and updates experiences using a “Think-Act-Refine” loop. "ReMem~\cite{wei2025evomem}"
- Retrieval-Augmented Generation (RAG): A framework that augments LLM prompts with retrieved external documents at inference. "Retrieval-Augmented Generation (RAG) offers a training-free alternative"
- Rerank: To reorder retrieved candidates (e.g., APIs) by estimated relevance or usefulness. "rerank and filter the retrieved candidate APIs"
- Semantic gap: A mismatch between natural-language requirements and code/API signatures that hinders retrieval. "semantic gaps."
- Semantic similarity score: A numeric measure of closeness between embeddings used for retrieval. "semantic similarity score."
- Task-level memory: The memory dimension capturing cross-API orchestration patterns for solving tasks. "task-level memory"
- Top-K relevant APIs: The K most relevant APIs selected for injection into the prompt. "top- relevant APIs"
- Usage Guidelines: Concise, reusable instructions that explain how to coordinate or invoke APIs correctly. "Usage Guidelines"
Collections
Sign up for free to add this paper to one or more collections.

