- The paper introduces a safety value-constrained MPC method that cooptimizes performance and safety using a reachability-informed terminal constraint.
- It leverages DeepReach to compute the safety value function, resulting in higher safety rates and improved robustness validated in both simulation and hardware.
- The approach reduces conservativeness and enhances solver efficiency, making it effective for high-dimensional, safety-critical robotic applications.
Introduction
The deployment of autonomous robotic systems in safety-critical applications necessitates the rigorous integration of safety constraints alongside the optimization of performance objectives. Conventional approaches frequently decouple these concerns, employing state-constrained optimal control for design-time performance optimization and safety filtering for online constraint enforcement. However, such paradigms often induce conservativeness or myopia, particularly for high-dimensional systems and environments with complex state and input constraints. "Cooptimizing Safety and Performance Using Safety Value-Constrained Model Predictive Control" (2604.23863) introduces a scalable MPC-based method that synthesizes high-performance, provably safe controllers using a reachability-informed terminal constraint. The paper substantiates its theoretical framework with thorough simulation and hardware validation on the Flexiv Rizon 10s manipulator, providing quantitative and qualitative evidence of improved safety and robustness compared to standard approaches.
Methodology
State-Constrained Optimal Control and MPC
The formulation is anchored in the classical state-constrained optimal control framework, targeting a system x˙=f(x,u) with state and input constraints, and an objective defined by a running cost r(x,u) and terminal cost ϕ(x). Online trajectory synthesis is achieved via MPC with a finite horizon h, updating the state and control at each step. However, finite horizon MPC can fail to guarantee persistent feasibility since constraint satisfaction is not explicit beyond the planning horizon, resulting in potential safety violations.
Hamilton-Jacobi (HJ) Reachability-based Terminal Constraint
The central innovation is the imposition of a terminal constraint based on the safety value function V(x) derived from HJ reachability analysis. This function characterizes the maximal control-invariant set for the closed-loop system—i.e., the set from which a (possibly distinct) control policy exists that maintains safety indefinitely. The safety value function is defined by the viscosity solution to the HJB variational inequality encoding the minimal distance to violation under system dynamics and constraints.
To avoid the curse of dimensionality inherent in grid-based PDE solving in high-dimensional spaces, V(x) is computed using DeepReach, a neural-network-based PDE solver that penalizes violations across the space of possible trajectories, stabilized by supervision on sampled solution points.
The resulting Safety Value MPC imposes the terminal constraint V(xh)≥ϵ, ensuring that the terminal state at each planning window remains within the maximal control-invariant safe set. The theoretical guarantees established include:
- Recursive feasibility: Under an exact V(x) and feasible initialization, the closed-loop MPC with the safety value constraint ensures all future iterates remain feasible and persistently safe.
- Less conservativeness: The approach synthesizes the largest terminal set consistent with safety, in contrast to the local or handcrafted invariant sets required by traditional CBF or set-based MPC techniques.
Simulation Results
Experimental Setup
The method is validated on a 14D state (7 joint positions + 7 velocities), 7D torque-controlled Flexiv Rizon 10s manipulator tasked with obstacle avoidance under reduced actuator limits. Two standard baselines are compared: unconstrained state-aware MPC and a Smooth Blending (SB) safety filter that projects solved trajectories post-hoc onto the feasible set using the same safety value function.
Normalized metric plots indicate that the Safety Value MPC achieves higher safety rates compared to unconstrained MPC, and is competitive with the SB-Filter baseline, despite both using the same reachability-informed safe set. However, the proposed method shows clear advantages in solver efficiency and robustness: it requires fewer sequential convexification iterations to solve and maintains a higher average distance to obstacles across all planning horizons.
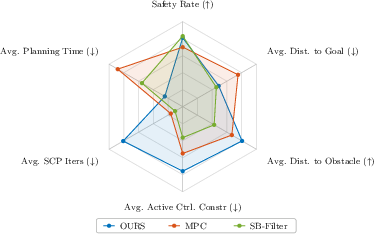
Figure 1: Normalized metrics demonstrating superior safety and constraint satisfaction for the proposed method in simulation.
End-effector trajectories further illustrate that the reachability-based approach often selects less 'direct' tasks-space trajectories to maintain safety, thereby sacrificing some performance metrics (increased task completion distance/time) for robust constraint satisfaction.
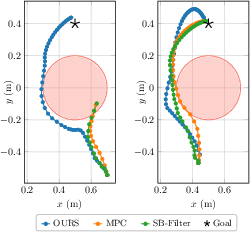
Figure 2: Example end-effector trajectories showing safe avoidance of obstacles by the proposed method where baselines may fail.
Safety rates and obstacle margins are visualized across increasing planning horizons. Unlike traditional MPC, which only approaches high safety rates for large horizons, the Safety Value MPC maintains superior safety even for short horizons, confirming that its look-ahead is unbounded in principle.
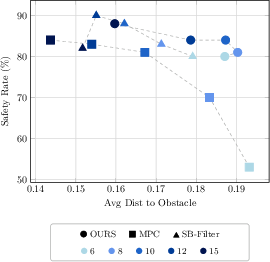
Figure 3: Safety rate and average distance to obstacle visualized across methods and planning horizons; the proposed method is robustly safe across settings.
Ablation and Discussion
The ablation across horizon lengths highlights:
- MPC safety is strongly horizon-dependent, improving with longer prediction windows.
- Safety Value MPC and SB-Filter are largely horizon-invariant, underscoring the theoretical safety guarantees conferred by terminal-value reachability sets.
It is noted, however, that the learned neural safety value function introduces practical imperfections (non-convexity, optimization challenges, rapid local variations). These issues manifested as failures to satisfy the terminal constraint before state constraint violation in some trials, even though the system state remained within the safe set prior to optimization failure. The authors provide an in-depth examination of the influence of the level-set buffer ϵ, highlighting a trade-off between numerical robustness and solver tractability.
Hardware Validation
The framework is further validated on physical hardware with the Flexiv Rizon 10s manipulator carrying a 7.5 kg payload. The system performs real-time planning at 20 Hz, leveraging a low-level PD controller at 1 kHz to track planned trajectories.
Across ten randomized initialization trials, Safety Value MPC achieves an 80% safety rate, significantly outperforming both the unconstrained MPC (30%) and SB-Filter (40%). Minor performance disparities in distance to goal/obstacle are observed but are statistically negligible due to safety-centric tuning and reduced actuator aggressiveness.

Figure 4: Hardware experiment snapshots illustrating safely planned manipulator motions around computationally modeled obstacles.
Practical and Theoretical Implications
This approach demonstrates that certified reachability analysis, integrated with online MPC in high-dimensional robotic task spaces, can systematically outperform both myopic performance-centric MPC and purely corrective safety filtering, particularly in regimes where fast online reaction and persistent feasibility are critical. The learning-based approximation of V(x), while practical for high dimensions, currently precludes formal safety guarantees when used with (non-convex and non-smooth) gradient-based optimization. Thus, research directions include enhancing the verifiability and gradient properties of neural approximators for safety value functions, and integrating robust neural verification techniques.
Theoretically, the framework provides a constructive path for systematic co-optimization of safety and task objectives at control synthesis time, bridging the divide between performance and certification in real-world autonomous systems.
Conclusion
The Safety Value-Constrained Model Predictive Control framework advances the state of the art in real-time, safety-critical trajectory optimization for high-dimensional robotic systems by marrying maximal-invariant reachability with tractable MPC. Its empirical superiority in safety rate, robustness, and solver efficiency is validated in simulation and hardware under stringent constraints. While reliance on learned safety value functions introduces limits on formal guarantees, future work on robust neural safety value verification and improved optimization strategies promises further progress in scalable safe control.

