- The paper introduces a sub-stage graph abstraction to decompose RL pipelines, enabling dynamic scheduling for improved GPU utilization.
- It demonstrates up to 1.85× throughput improvements and reduced per-pipeline latency by balancing resource allocation across heterogeneous workloads.
- The approach integrates workload migration and look-ahead scheduling to mitigate inter-worker imbalance and enhance cost-efficiency in LLM post-training.
JigsawRL: Assembling RL Pipelines for Efficient LLM Post-Training
Motivation and Problem Context
RL-based post-training has become the canonical paradigm for aligning LLM behavior with diverse objectives, now scaling to tens or hundreds of thousands of fine-tuned model variants. However, the resource and financial cost of running these RL pipelines is a persistent bottleneck, mainly due to severely underutilized GPUs—often yielding average MFU below 10% as pipeline scale increases (Figure 1). Profiling indicates that simply scaling cluster size for greater throughput exhibits rapidly diminishing returns, because of sharp utilization imbalances, especially during the rollout phase.
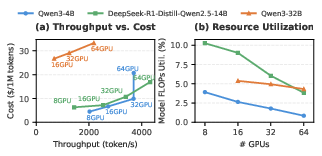
Figure 1: (a) Trade-off between RL pipeline throughput and monetary cost across models; (b) FLOPs utilization (MFU) for increasing GPU scale, demonstrating falling efficiency.
These imbalances are exacerbated by modern agentic RL workloads with long-tailed batch lengths, tool usage, multi-turn rollouts, and external feedback. Analysis demonstrates that existing RL pipeline frameworks—whether synchronous or asynchronous—remain bottlenecked by slow, underutilized rollout steps (Figure 2 and Figure 3).
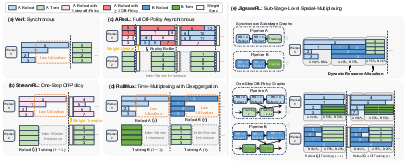
Figure 2: Execution behaviors reveal low utilization and inter-worker imbalance in current RL frameworks, which JigsawRL improves via sub-stage spatial multiplexing.
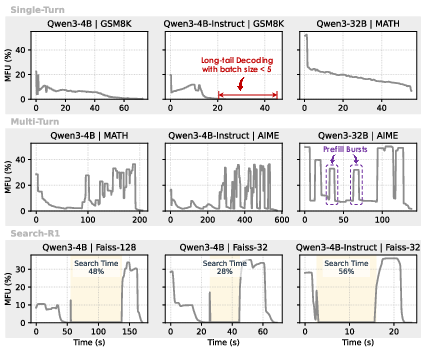
Figure 3: Diverse agentic behaviors in rollouts induce highly dynamic GPU utilization and imbalance.
Prior optimization efforts—such as asynchronous execution and time multiplexing—alleviate but do not resolve the inefficiencies rooted in the hierarchical structure and non-uniform resource demands of RL pipeline stages.
JigsawRL: System Design and Technical Approach
JigsawRL rethinks RL pipeline execution by explicitly decomposing pipelines into sub-stage graphs, exposing intra- and inter-worker imbalance hidden by conventional stage-level abstraction.
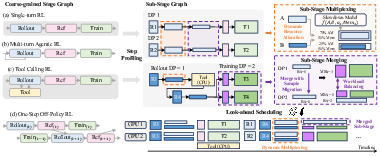
Figure 4: Dense overview of JigsawRL: Coarse pipeline graphs are expanded into fine-grained sub-stage execution graphs, facilitating concurrent, resource-coordinated multiplexing and workload merging.
Sub-Stage Graph and Behavioral Profiling
The sub-stage graph abstracts both intra-stage (e.g., prefill bursts, memory-bound vs. compute-bound decoding) and inter-worker variance. Empirical analysis shows that rollout batch size and resource use remain highly self-similar over short training windows, enabling accurate per-step profiling and dynamic graph construction (Figure 5).
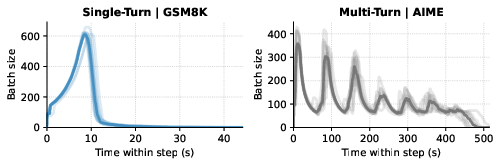
Figure 5: Rollout batch size variation across 10 steps (Qwen3-4B-Instruct), revealing strong temporal consistency.
Efficient Sub-Stage Multiplexing
Contrasting with naive spatial approaches that overlap entire RL pipelines (leading to memory contention or wasted compute), JigsawRL schedules only complementary sub-stages for concurrent execution. It uses discrete resource partitioning (via NVIDIA Green Context and MPS) to limit SM and memory allocation and leverages a pre-profiled slowdown model covering key sub-stage/resource allocation states (Figure 6–Figure 7).
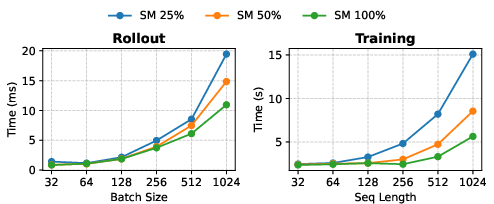
Figure 6: Differential latency of rollout and training sub-stages under various SM allocations.
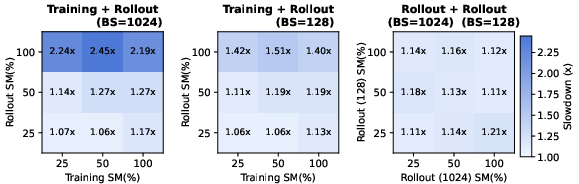
Figure 8: Slowdown surface for two sub-stages co-located under variable SM splits.
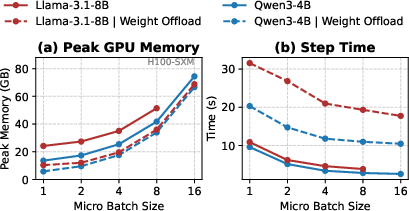
Figure 7: Micro-batch size impact on per-GPU memory usage and training time for standard vs. offloaded weights.
Mitigating Multi-Worker Imbalance via Sample Migration
Long-tail rollout samples cause persistent resource fragmentation in distributed settings. JigsawRL dynamically migrates these samples across data parallel (DP) workers, aggregating low-utilization fragments to a subset of GPUs and thereby freeing others for more productive sub-stage execution (Figure 9).
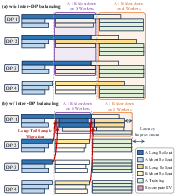
Figure 9: Inter-worker imbalance resolved via sample migration and multiplexing-aware workload balancing.
Look-Ahead Graph Scheduling
Sub-stage scheduling is cast as a windowed critical-path minimization problem: a look-ahead heuristic enumerates possible multiplexing and merger actions, using the slowdown model to select for globally minimized completion time—outperforming greedy policies that optimize instantaneous pairing (Figure 10).
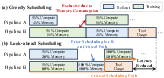
Figure 10: Look-ahead vs. greedy scheduling—look-ahead preserves co-location opportunities, lowers critical path time.
Empirical Evaluation
Comprehensive experiments cover 4–64 A100/H100 GPUs, diverse RL pipelines (single-turn, multi-turn, tool-usage), multiple model sizes (Qwen3-{0.6B, 4B, 14B, 32B}, Llama-3.1-8B, DeepSeek-R1-14B), and both synchronous/asynchronous RL settings.
Throughput and Cost Efficiency
JigsawRL achieves up to 1.85× throughput improvement over Verl (synchronous baseline) and 1.54× over StreamRL/AReaL (asynchronous baselines), with consistent gains across modalities and cluster scales (Figure 11 and Figure 12). This improvement is most pronounced where rollout imbalance is greatest. Aggregated throughput scales with cluster size, and the moderate per-pipeline latency penalty (∼1.14–1.48×, Figure 13) is substantially less than naive serialization.
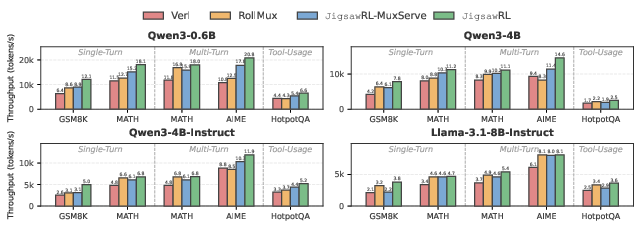
Figure 11: Homogeneous RL pipeline throughput improvements (8× H100).
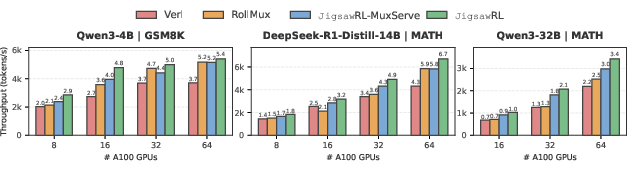
Figure 12: Scalability to 64× A100: JigsawRL maintains throughput gains and scales efficiently with larger models.
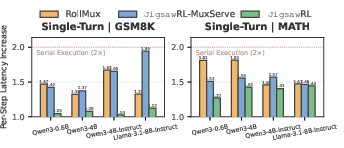
Figure 13: Latency increase of multiplexed execution is sublinear vs. serialization—per-step penalty limited for most workloads.
JigsawRL's throughput benefit is robust across asynchronous, heterogeneous, and mixed pipeline settings (Figure 14–Figure 15). Notably, disparate model sizes (e.g., 0.6B vs. 8B) can exploit complementary resource usage for superadditive utilization.
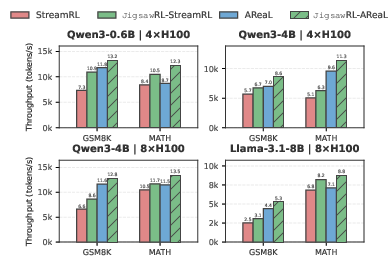
Figure 14: Throughput gains under one-step off-policy (StreamRL) and fully asynchronous (AReaL) pipelines.
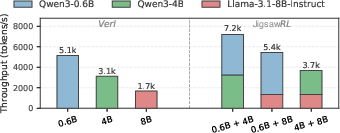
Figure 16: Heterogeneous pipeline throughput (Qwen3–0.6B, Llama-3.1–8B) demonstrates resource complementarity.
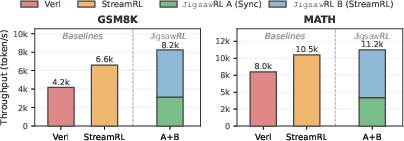
Figure 15: Multiplexing synchronous (A) and asynchronous (B) pipelines; both benefit in aggregate throughput.
Cost-Throughput Tradeoff and Parallelism Integration
JigsawRL adds a new, orthogonal parallelism dimension agnostic to the data or tensor parallelism already used in current LLM training, improving throughput/cost tradeoff curves across cluster scales (Figure 17).

Figure 17: JigsawRL's pipeline multiplexing preserves cost-efficiency as cluster/GPU count ramps, unlike naive scaling.
Sub-stage-level control yields higher utilization (MFU) versus rollout-only spatial multiplexing (Figure 18), and targeted DP workload migration further reduces step latency (Figure 19).
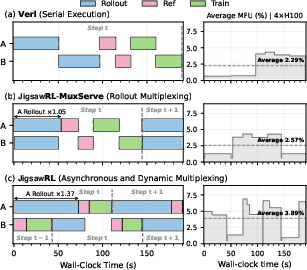
Figure 18: Pipeline multiplexing strategies' effect on MFU—JigsawRL achieves the best average utilization.
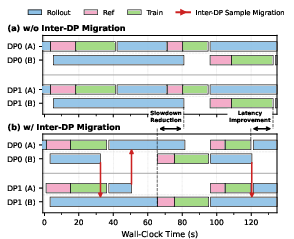
Figure 19: DP workload migration lowers training step latency by isolating long-tail rollouts.
Contrasts with Previous Work
Compared to prior systems—most of which focus on either pipeline (RollMux, StreamRL) or inference serving (MuxServe, WarmServe, Aegaeon, Prism)—JigsawRL uniquely exploits the sub-stage temporal and spatial complementarity inherent to RL (rather than mere batching or model colocation). Its graph-based policy outperforms static or greedy heuristics and is robust to agentic behaviors, synchrony constraints, and heterogeneity.
Implications and Future Directions
JigsawRL establishes pipeline multiplexing and sub-stage graph scheduling as first-class resource allocation axes for RL post-training of LLMs. This has immediate implications for operationalizing large-scale, heterogeneous cluster training, especially in serverless or shared environments, and materially improves the marginal cost of developing new RL-tuned LLM variants.
Looking forward, natural extensions include adaptation for MoE architectures (enabling sub-expert-level multiplexing exploiting even finer granularity of imbalance) and parameter-efficient strategies such as LoRA or weight sharing. Additionally, tighter integration with online pipeline parallelism search and automated resource allocation via system telemetry remains a promising avenue for further throughput and cost minimization.
Conclusion
JigsawRL defines a practical, technically robust framework for maximizing GPU utilization in RL-fine-tuning of LLMs via a sub-stage graph abstraction and look-ahead resource-aware scheduling. It consistently yields strong throughput improvements with modest latency overhead, supports workload heterogeneity, and is compatible with existing parallelism methods. These results suggest a clear path toward scalable, affordable RL-based LLM development for both research and production contexts (2604.23838).

