- The paper introduces SpotEdit, a training-free, token-level selective region editing framework that leverages perceptual scoring to update only necessary areas.
- Methodologically, it combines SpotSelector for dynamic region identification with SpotFusion for temporally consistent feature blending, ensuring fidelity in unchanged regions.
- Quantitative results demonstrate a 1.7–1.9× speedup with maintained perceptual and semantic quality, and the approach integrates well with other acceleration techniques.
Introduction and Motivation
Efficient and faithful selective image editing remains a challenge for diffusion transformer (DiT) models that commonly regenerate all image regions for each editing instruction. This indiscriminate denoising introduces unnecessary computation and may degrade unchanged areas. The central observation motivating this work is that, during partial editing tasks, many regions of an image rapidly stabilize and require no further modification; global denoising thus both wastes compute and risks artifact introduction in those regions.

Figure 1: Reconstruction results at different timesteps for the prompt "Add a scarf to the dog." Regions visually consistent with the target stabilize early, motivating selective updates.
“SpotEdit: Selective Region Editing in Diffusion Transformers” (2512.22323) proposes a training-free framework, SpotEdit, which integrates two key mechanisms—SpotSelector and SpotFusion—to answer whether full-image regeneration is necessary and operationalizes the principle: "edit what needs to be edited." The approach achieves region-localized editing with high background fidelity and significant computational savings.
Methodology
SpotEdit is composed of SpotSelector and SpotFusion, which together enable token-level selective processing for DiTs while guaranteeing contextual consistency and visual coherence.
SpotSelector: Dynamic Region Identification
SpotSelector's objective is to identify, at each step in the denoising trajectory, which spatial regions (tokens) require modification. Drawing upon the closed-form reconstructions available in the rectified flow formulation, SpotSelector contrasts the reconstructed, denoised latent with the reference (condition) image in a perceptual (LPIPS-like) feature space. By thresholding this token-wise perceptual score, it routes tokens to either the regeneration path (full DiT computation) or the reuse path, where condition-image features are retained without further computation.
Critically, measuring perceptual rather than raw ℓ2 distances avoids spectral bias toward low-frequency content and aligns region selection with human visual similarity, as demonstrated in additional analysis.
SpotFusion: Temporally Consistent Feature Blending
Efficient region-skipping inadvertently removes the contextual support (via self- and cross-attention) vital for the successful synthesis of edited regions. SpotFusion addresses this by maintaining a temporally consistent “condition cache” of key-value (KV) pairs across all steps for both the reference and skipped regions. Instead of statically reusing cached features (which would become temporally misaligned due to feature drift in DiTs), SpotFusion performs a smooth, time-dependent interpolation between cached and reference features, informed by empirical PCA analysis illustrating rapid alignment between non-edited and condition-image latent representations.
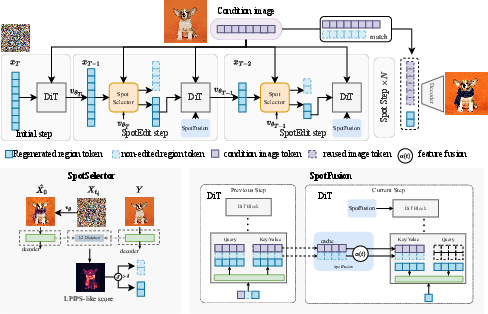
Figure 2: The SpotEdit pipeline: initial standard denoising, SpotSelector-based region routing, SpotFusion-based contextual blending, and final token replacement.
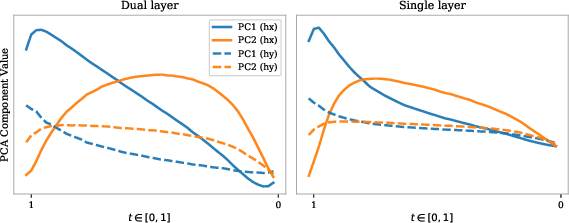
Figure 3: PCA trajectories illustrate how non-edited tokens quickly converge to the reference latent subspace, justifying feature reuse.
Together, SpotSelector and SpotFusion enable computation to be restricted to edited regions, while preserving attention context, spatial structure, and visual consistency.
Quantitative and Qualitative Results
SpotEdit is evaluated on PIE-Bench++ and imgEdit-Benchmark in comparison to several acceleration and localized editing baselines, including TaylorSeer, TeaCache, FollowYourShape, and standard inference. Comprehensive metrics (CLIP similarity, PSNR, SSIM, DISTS, and VL scores) confirm that SpotEdit achieves nearly identical editing quality to the full-transformer baseline, with substantial speedup (1.7–1.9×) and no significant drop-off in perceptual or semantic fidelity.

Figure 4: Non-edited region preservation comparison. SpotEdit maintains background color and structure, while other approaches introduce artifacts and distortions.
SpotEdit's region-skipping is orthogonal to temporal or full-token accelerators; it can be composed with systems like TeaCache or TaylorSeer for even higher speedup without quality loss, empirically verified in dedicated experiments.
Ablation Studies
Ablations underline the necessity of the core architectural choices:
- Token Fusion: Removing SpotFusion or implementing static KV caching yields significant degradation. Adaptive, temporally consistent fusion is essential for both background preservation and edit fidelity.

Figure 5: Qualitative ablation on token fusion; adaptive SpotFusion removes artifacts introduced by static or naive skipping.
- Similarity Metric: Using ℓ2 as a selection criterion introduces false positives for brightness or low-frequency changes and misses subtle texture edits. LPIPS-like perceptual scoring is robust to these issues.

Figure 6: Comparison of ℓ2 and LPIPS-like scores. ℓ2 leads to incorrect region allocations; LPIPS-like features result in perceptually correct detection.
- Reset Mechanism: Periodic refreshing of the condition cache is necessary to prevent numerical drift in token values.
- Condition Cache: Caching both condition and non-edited region features balances compute savings with minimal perceptual quality loss.
Generalization and Additional Results
SpotEdit generalizes to other DiT-based editors such as Qwen-Image-Edit, yielding equivalent or improved results with 1.6–1.7× acceleration ratios. Extensive qualitative results across various editing instructions further demonstrate consistent, high-quality region editing with strict preservation of unedited content.

Figure 7: Extended SpotEdit results on diverse instructions, demonstrating localized regeneration and faithful background maintenance.
Implications and Future Directions
SpotEdit challenges the tradition of blanket per-token denoising in diffusion-based editing, instead supporting a resource-aware, region-selective paradigm. This directly impacts scalable interactive editing, real-time applications, and compute/battery-constrained deployment. Further, SpotEdit's framework is orthogonal to—and thus composable with—existing acceleration work and is applicable to any DiT architecture with flow-based or rectified flow generative processes.
Beyond immediate acceleration, the approach prompts new research into dynamic region selection, adaptive contextual attention in generative transformers, and fine-grained interpretability of diffusion editing trajectories. Extensions could explore semantic-guided region selection or content-aware allocation of computational resources.
Conclusion
SpotEdit introduces a principled, training-free approach for selective region editing in diffusion transformers. By leveraging token-wise perceptual analysis and temporally consistent feature blending, it achieves significant editing acceleration without sacrificing content fidelity. Extensive benchmarks validate its effectiveness, and the method synergizes with established acceleration techniques, positioning SpotEdit as a strong candidate for efficient and precise generative image editing frameworks.