- The paper introduces a novel diffusion-based image editing framework that integrates bounding box guidance via a two-stage multi-level architecture.
- The method combines early and deep fusion techniques to inject clear spatial priors, enhancing both edit localization and background integrity.
- Reinforcement learning with decoupled rewards for ROI and background enables high-fidelity, robust edits validated by superior quantitative and qualitative benchmarks.
FineEdit: A Multi-Level Architecture for Fine-Grained Diffusion-Based Image Editing with Bounding Box Guidance
Introduction and Motivation
FineEdit (2604.10954) addresses fundamental limitations of current diffusion-based image editing models, particularly the inability of text-only guidance to achieve precise spatial localization and background consistency in complex multi-object scenes. Existing paradigms, including mask-based and global structural priors, either lack fine control over edit regions or suffer from boundary leakage and background artifacts. FineEdit integrates explicit bounding box guidance via a two-stage multi-level architecture, unifying token-level fusion in both shallow and deep transformer layers, and augments learning with a decoupled region/background reward during post-training. The resulting system enables precise, high-fidelity, and robust controllable image editing.
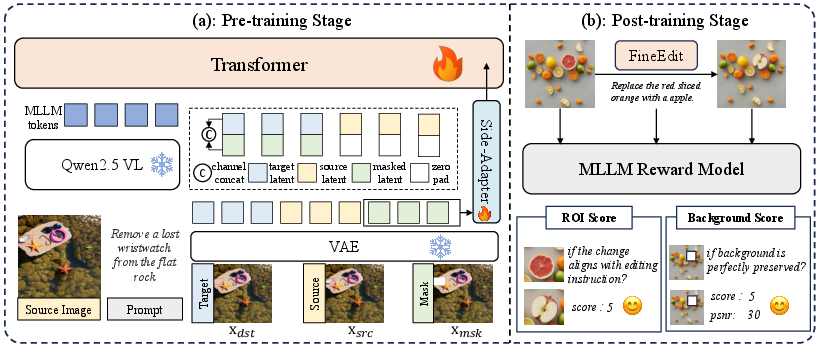
Figure 1: Overview of FineEdit framework, which includes two training stages: (a) Pre-training stage establishes multi-level spatial priors using early and deep fusion. (b) Post-training stage applies reinforcement learning with a novel decoupled reward function.
Architecture and Training
Multi-Level Spatial Condition Injection
FineEdit adapts the MM-DiT backbone with two orthogonal fusion mechanisms:
- Early Fusion: Encodes bounding box masks at the input space and concatenates masked source latents with noisy target latents along the channel dimension. This provides strong spatial priors explicitly localizing the edit area.
- Deep Fusion: Employs a side-adapter transformer that injects features extracted from the masked source image into intermediate transformer layers, enhancing alignment and accelerating convergence while maintaining the integrity of both ROI and the background manifold.
Ablation demonstrates that exclusive reliance on either strategy is suboptimal; only the joint application realizes both convergence and optimal quantitative/qualitative results.
Reinforcement Learning with Decoupled Rewards
FineEdit introduces a post-training RL stage with a decoupled reward:
- Foreground (ROI) Reward: Assesses semantic compliance within the bounding box using Qwen3-VL to estimate instruction adherence.
- Background Reward: Utilizes a fusion of model-based (e.g., semantic similarity) and pixel-level metrics (e.g., PSNR), measuring fidelity outside the ROI.
- This design overcomes the reward signal entanglement inherent in global VLM evaluation—enabling a controlled tradeoff between localized edit fidelity and global context preservation. The ablation validates superior background consistency and increased ROI accuracy compared to global reward RL.
Unified Visual Instruction Paradigm
FineEdit utilizes a unified interface for visual instructions, meaning the same underlying architecture handles:
A key capability—demonstrated in extensive qualitative examples—is bounded style transfer, where stylistic operations are effectively restricted to an object or region without undesired global spillover.
Dataset and Benchmark Construction
FineEdit-1.2M Dataset
FineEdit-1.2M is a 1.2M pair dataset with strict filtering, bounding box annotation, and human-in-the-loop/automated multi-stage validation:
- Data Sources: Combinations of LAION-Aesthetic-6M, Megalith-10M, diverse perception datasets, and internal images.
- U-GAF Pipeline: Integrates automated object localization (Co-DETR), bounding box filtering, prompt curation (InternVL3), rigorous edit synthesis (Flux1-kontext-dev, Qwen-Image-Edit), and a multi-stage filtering regime using IoU, RGB entropy, VLM scoring, and EditScore validation.
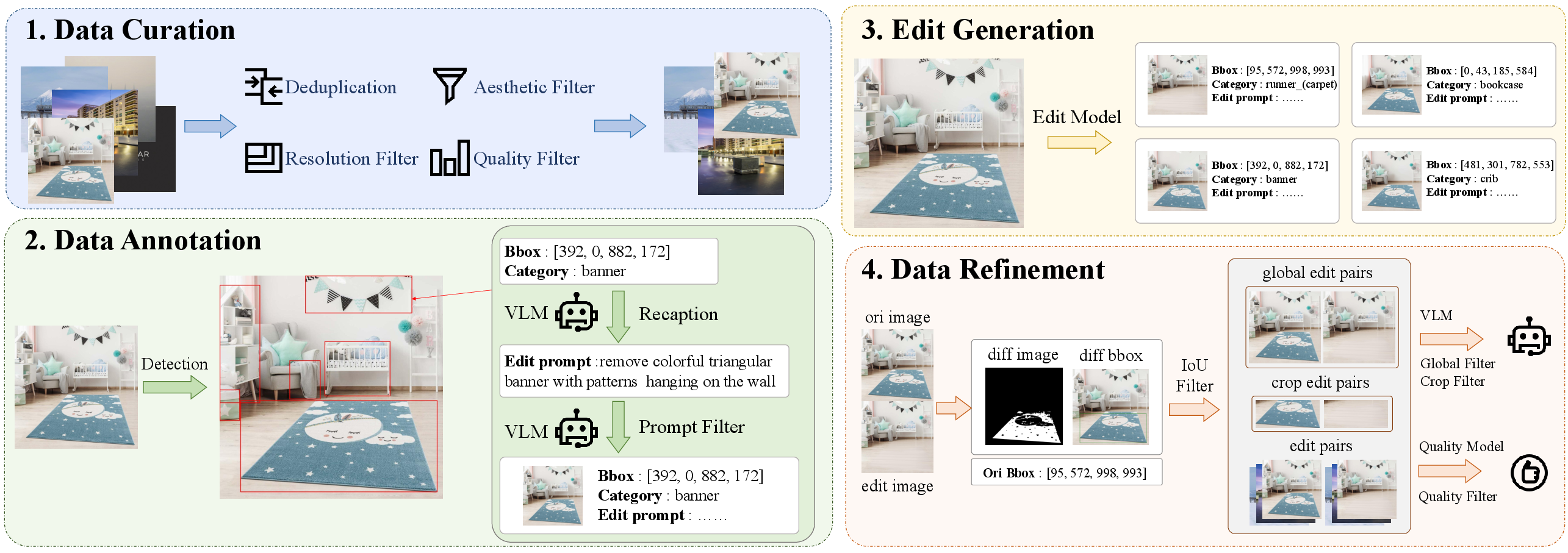
Figure 3: The U-GAF Pipeline integrates data curation, annotation, edit synthesis, and refinement for dataset construction.
- Evaluation Dataset: FineEdit-1k—1,000 images across broad categories, manually validated with pixel-differencing and realignment between pre- and post-edit bounding boxes.
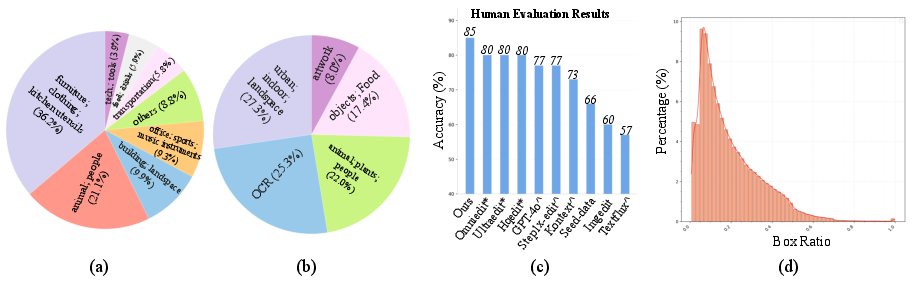
Figure 4: Dataset analysis showing distributions and human evaluation accuracy—demonstrating precise annotation and broad diversity.
Experimental Results
Quantitative Benchmarks
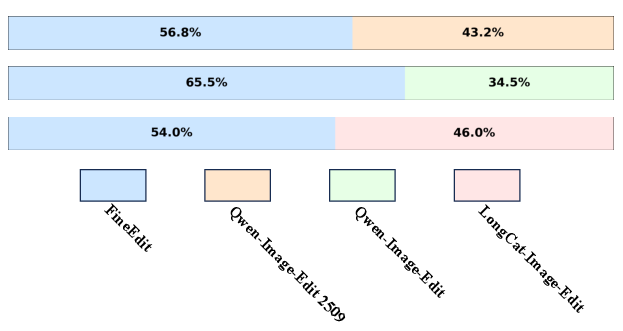
FineEdit establishes SOTA across broad image editing benchmarks, outperforming Qwen-Image-Edit, LongCat-Image-Edit, Step1X, BAGEL, OmniGen2, and FireRed-Image-Edit. Evaluations show:
Qualitative and Robustness Analyses
FineEdit delivers artifact-free, semantically accurate, and visually natural edits under all settings, including complex multi-object, style transfer, and text edits. Robustness analyses validate insensitivity to bounding box scale variation and tolerate moderate spatial perturbation in box definition.

Figure 7: Qualitative Results Across Diverse Editing Tasks, illustrating the flexibility and high fidelity of FineEdit.
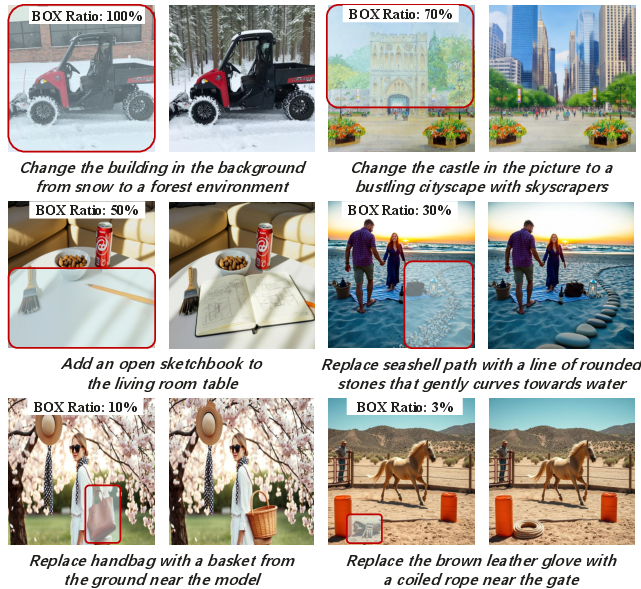
Figure 8: Robustness to Various Bounding Box Scales and Ratios, maintaining edit quality from small to large regions.

Figure 9: Robustness to Bounding Box Perturbations, highlighting resilience to imprecise user input.
Ablation Study
Ablation experiments systematically validate:
- Multi-Level Fusion Superiority: Early or deep fusion mechanisms alone yield suboptimal localization or convergence; only their combination achieves top performance across both background and ROI metrics.
- Decoupled RL Reward: Isolating ROI and background rewards directly improves fine-grained edit accuracy and prevents background collapse observed under global reward RL.
Theoretical and Practical Implications
FineEdit substantiates a paradigm shift in controllable diffusion image editing. Its architecture demonstrates that explicit spatial priors, injected at both low and deep representational levels and paired with decoupled localized reward optimization, are the keys to high-precision and robust controllable region editing. This finding generalizes to any editing system where fine synchronization between instruction, spatial prior, and latent generation is required.
Practically, FineEdit enables real-world deployment in scenarios that demand reliable object manipulation without background drift—relevant in professional graphics, AR/VR content authoring, commercial image editing, and interactive human-in-the-loop creative systems.
Limitations and Future Work
While FineEdit advances spatial control, it relies on rectangular bounding box cues; it cannot handle free-form, irregular, or fine-shape specified edits. Extending the interface to include point, scribble, and polygonal inputs, while maintaining training efficiency and edit fidelity, is a key next step. Future architectures may generalize the multi-level spatial condition framework to arbitrary visual prompts.
Conclusion
FineEdit introduces a cohesive architectural and dataset innovation, solving key challenges in fine-grained, background-preserving, and controllable diffusion-based image editing. Its technical contributions—including multi-level spatial instruction injection, a decoupled RL reward strategy, and the accompanying high-precision dataset and benchmarks—yield performance improvements substantiated by both quantitative and qualitative evaluation. The methodology and analysis inform continued progress toward reliable and flexible visual instruction editing systems in large-scale vision models.