- The paper introduces a novel solution using KV-mix and Latents-Shift to counter excessive source information injection during inversion-based visual editing.
- The paper demonstrates significant improvements in image and video editing, with enhanced CLIP similarity, PSNR/SSIM scores, and superior subject consistency.
- The paper offers a flexible, plug-and-play design that balances precise attribute modifications with background fidelity, enabling effective natural-language guided edits.
Introduction
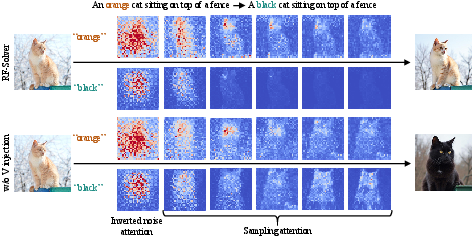
ProEdit ("ProEdit: Inversion-based Editing From Prompts Done Right" (2512.22118)) presents a solution to a critical limitation in state-of-the-art inversion-based prompt-controlled visual editing. Existing flow-based inversion methods maintain source content consistency via latent initialization and global attention injection strategies, but these approaches systematically over-inject source image information. This impedes accurate attribute editing (e.g., pose, color, number) by biasing the output towards the source distribution, reducing editability and textual guidance effectiveness. The authors introduce two modules—KV-mix and Latents-Shift—to mitigate this excessive source information injection at both the attention and latent levels, yielding markedly improved precision in image and video editing while maintaining non-edited content fidelity.
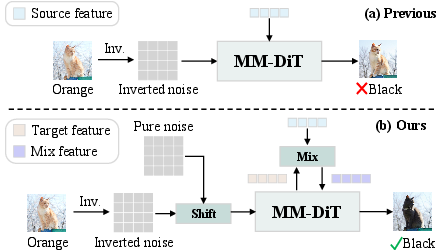
Figure 1: ProEdit introduces Latents-Shift for latent initialization and KV-mix for targeted attention injection, contrasting prior global strategies and resulting in controlled attribute editing with background consistency.
Prior works using flow-based inversion initialize the sampling process with latent variables inverted from the source image and globally attach source attention features. While preserving overall consistency, this architecture leads to two key issues:
Method: ProEdit Modules
KV-mix: Region-Specific Attention Injection
KV-mix augments the attention mechanism by distinguishing edited and non-edited regions via masks derived from attention maps. For non-edited regions, full source attention is injected; in edited regions, a weighted mix of source and target K/V features is applied, parametrized by δ. This design, applied across blocks and attention heads, eliminates manual selection and optimally balances background preservation and attribute editing.
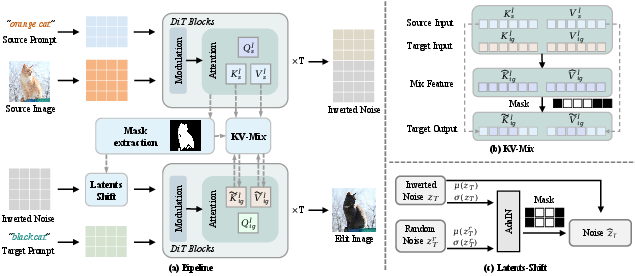
Figure 3: ProEdit pipeline delineating mask-based edited region extraction, Latents-Shift perturbation of inverted noise, and region-contingent KV-mix for controlled feature injection.
Latents-Shift: Controlled Distribution Perturbation
Inspired by AdaIN from style transfer, Latents-Shift introduces random noise into the inverted latent only in edited regions, controlled by a fusion ratio β. This shifts the local distribution away from the source, enabling greater attribute plasticity without sacrificing structural coherence in background and non-editing content.
Experimental Results
Image Editing
On PIE-Bench, flow-based inversion methods equipped with ProEdit demonstrate superior CLIP similarity in both whole image and edited regions, as well as enhanced background preservation (PSNR/SSIM metrics) compared to baseline methods. Notably, ProEdit applied to UniEdit yields top scores on most metrics, reflecting state-of-the-art editability and fidelity.
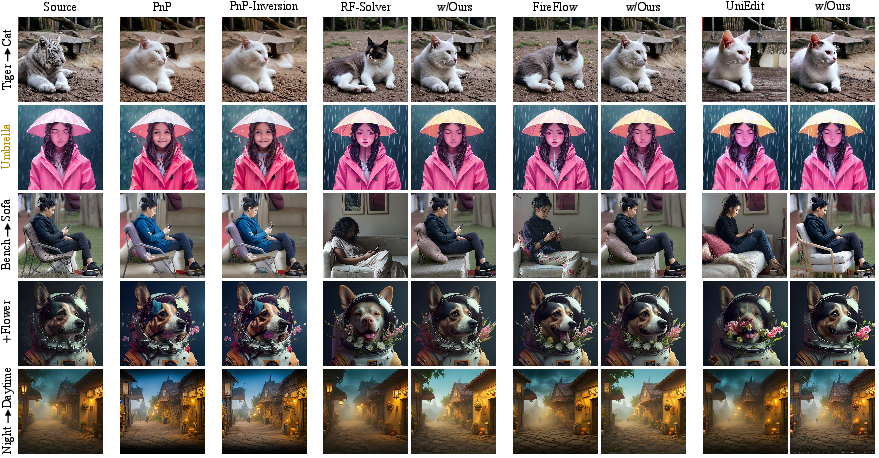
Figure 4: Qualitative comparison highlights ProEdit's ability to achieve targeted edits while maintaining precise background and non-editing attribute consistency.
Specialized color editing experiments validate Latents-Shift's efficacy: ProEdit-mediated models dramatically outperform baselines on both content preservation and targeted attribute modification.
Video Editing
In text-driven video editing, ProEdit achieves best-in-class performance on subject consistency, motion smoothness, aesthetic, and imaging quality (Table 5). Integration with RF-Solver improves temporal/spatial consistency of edits.

Figure 5: ProEdit preserves background and motion while facilitating precise attribute edits across video frames.
Instruction-Based Editing
With Qwen3-8B integration, ProEdit demonstrates robust editing via natural-language instructions, lowering usage barriers and broadening practical applicability.

Figure 6: End-to-end editing conditioned on explicit natural-language instructions.
Ablation and Design Analysis
Ablation studies confirm that KV-mix and Latents-Shift each individually enhance edit performance; their synergistic combination yields maximal gains. Comparative analysis of attention feature injection combinations substantiates that joint KV fusion is strictly optimal. ProEdit’s region-aware mask extraction method (applied to last Double block attention) achieves reliable region selection with reduced computational overhead, and mask diffusion ensures robust boundary coverage for semantic alignment.
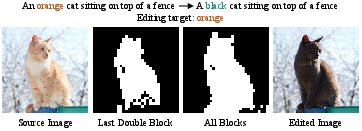
Figure 7: Mask extraction from last Double block and averaged blocks both robustly segment editing regions for effective injection control.
Theoretical and Practical Implications
The decomposition of editing imperfection into attention and latent injection components provides a foundation for more granular control in prompt-based inversion editing across image and video domains. ProEdit’s design demonstrates that region-aware intervention—both in attention and latent initialization—can simultaneously achieve non-edited content fidelity and high editability, without manual head/layer/block specification. This points to a future direction of modular, plug-and-play editing protocols for generative models, supporting customizable edit strengths (via δ and β) and seamless integration into evolving flow-based architectures.
Further research may extend ProEdit’s paradigm to non-flow models, adaptive mask extraction, and multimodal tasks, as well as end-to-end learned variants informed by user intent.
Conclusion
ProEdit resolves the excessive source information injection inherent in prior flow-based inversion editing by introducing KV-mix and Latents-Shift modules operating at the attention and latent levels. Extensive experiments on image and video benchmarks demonstrate that ProEdit delivers precise attribute editing and robust non-edited content preservation, outperforming existing methods. The plug-and-play property and principled region-wise design position ProEdit as a flexible foundation for the next generation of high-fidelity prompt-based visual editing systems.