- The paper introduces a continual training pipeline that combines expert iteration, utility-aware preference learning, and perplexity-weighted DPO to bridge Olympiad mathematics with optimization formalization.
- It demonstrates that targeted fine-tuning on Lean optimization problems can achieve up to 55.25% Pass@32, significantly outperforming traditional whole-proof generation methods.
- The approach mitigates catastrophic forgetting while enhancing cross-domain generalization, with improvements evident on both in-domain and out-of-domain benchmarks.
OptProver: Continual Training for Domain Adaptation in Formal Theorem Proving
Motivation and Problem Setting
Formal theorem proving with LLMs has advanced substantially in Olympiad-style mathematics, but the transition to undergraduate optimization exposes critical limitations. Optimization, underpinning modern ML and OR, presents non-trivial domain-specific shifts: formalizations must operate on convexity, optimality conditions, and algorithmic analyses less prevalent in Olympiad corpora. Existing step-level provers trained on competition mathematics exhibit catastrophic forgetting and strategy drift when naively fine-tuned on optimization-related data, as empirically characterized by interactive distribution shift and statistical signals such as perplexity (Figure 1).
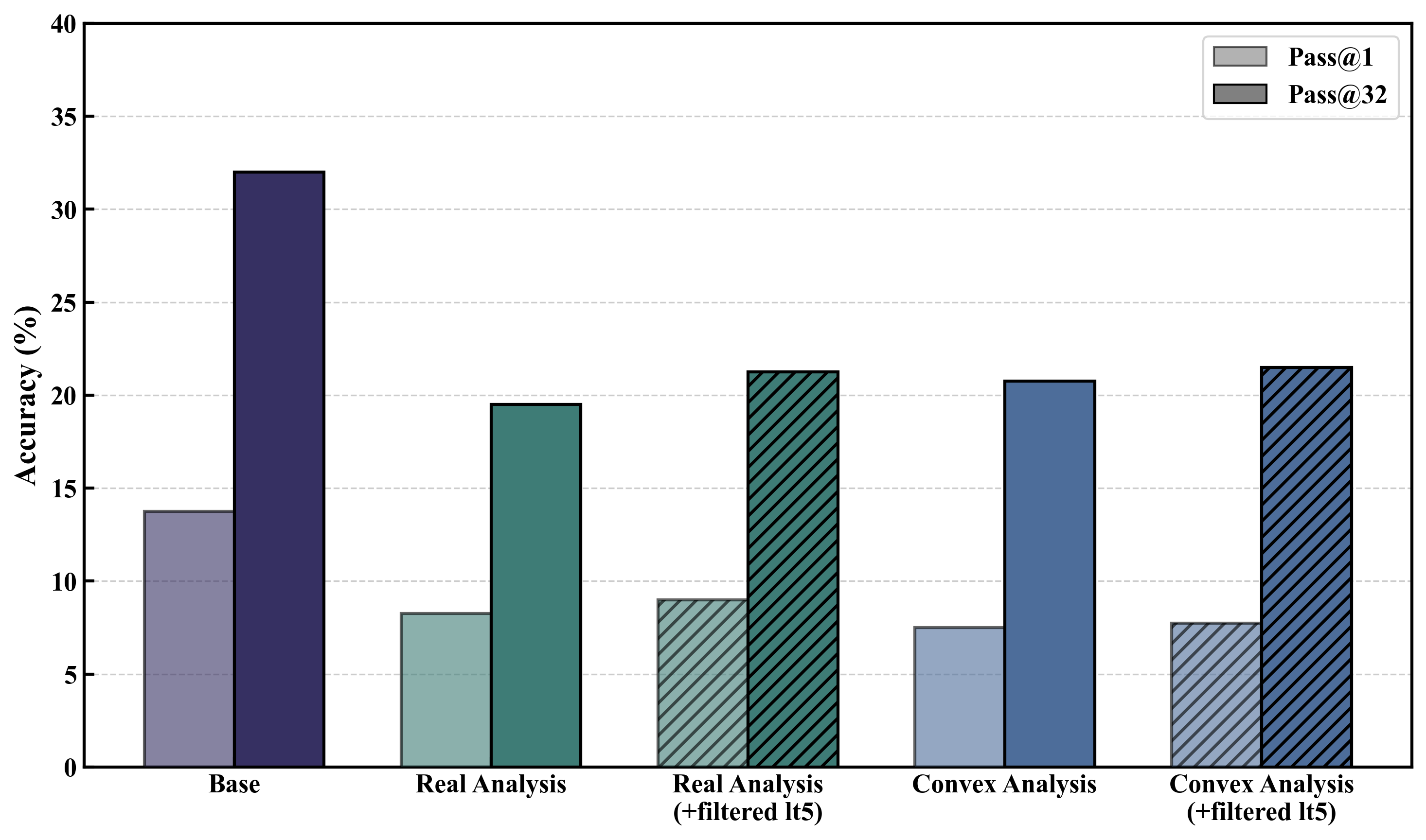
Figure 1: Pass@1 accuracy decay on OptBench during direct supervised fine-tuning (SFT), showing that even with perplexity filtering, whole-proof-trace training degrades the model’s proving power relative to the BFS-Prover-V2-7B base.
Technical Approach
OptProver attacks this domain adaptation challenge through a robust continual training pipeline that integrates three core innovations:
- Optimization-Centric Data Curation via Expert Iteration: Rather than directly mixing textbook-derived optimization traces with prior Olympiad training, OptProver employs large-scale expert iteration from a BFS-Prover-V2-7B base. This iterative self-distillation on Mathlib and formalized textbooks generates only those trajectory steps that the current policy can verify, guaranteeing data validity and progressive curriculum alignment.
- Utility-Aware Preference Learning: Standard likelihood objectives over-emphasize syntactic validity without accounting for tactic utility in proof search. OptProver constructs a utility-annotated preference dataset from search trees, labeling tactics as proven (useful), stagnant (locally valid but globally unproductive), or invalid. Direct Preference Optimization (DPO) is extended: correct-but-stagnant transitions, which lead search into dead-ends or exponentially expand the branching factor, are explicitly penalized. Preference pairs are drawn across sibling tactic branches to reinforce realized efficiency over mere local correctness.
- Perplexity-Weighted Direct Preference Optimization (PW-DPO): High-perplexity tokens (with respect to the reference model) in formal corpora correlate with either true out-of-distribution semantics or noise and induce unstable optimization when applying pairwise objectives. OptProver applies token-level weighting to suppress contributions from low-probability regions (based on the reference), prioritizing reliably supported updates and further mitigating catastrophic forgetting. The resulting PW-UAPO loss provides principled stability for domain transfer.
Experimental Validation
The newly constructed OptBench benchmark comprises 400 Lean-formalized optimization problems spanning analysis, convexity, and algorithmic domains with substantial distributional divergence from Olympiad mathematics. Models are evaluated under Lean 4 and LeanDojo environments using Pass@1 and Pass@32/256 metrics.
Key findings and strong numerical results include:
- Step-level provers decisively outperform whole-proof generators. For example, the best whole-proof baseline (DeepSeek-Prover-V2-7B, 7B) yields < 20% Pass@256. In contrast, BFS-Prover-V2-7B baseline achieves 32% Pass@32.
- OptProver with expert iteration jumps to 50% Pass@32, while further preference optimization gains additional points—PW-UAPO delivers 55.25% Pass@32. The improvement is most pronounced in basic and algorithmic subdomains.
- Robustness is sustained: Out-of-domain scores on MiniF2F and ProofNet not only avoid decay but show slight improvements, indicating no catastrophic forgetting or overfitting to optimization. Reasoning skills generalized to other undergraduate-level math.
- Expert iteration scaling: The majority of performance improvements accrue in early rounds, with diminishing returns in later iterations. This points to residual hardness in problems requiring logic outside the accessible proof curriculum.
Analysis and Implications
OptProver’s pipeline reveals that perplexity minimization alone is not indicative of downstream utility in formal domains—interactive proof search exposes the decoupling of syntactic validity from search efficacy. The integration of utility-aware and perplexity-aware objectives is essential to avoid both search inefficiency (by penalizing stagnant actions) and forgetting (by stabilizing gradient updates on reference-supported data). The demonstrated success on OptBench and standard theorem proving benchmarks validates both in-domain adaptation and out-of-domain preservation.
Practically, OptProver makes automation of optimization proofs accessible at the 7B model scale, directly impacting formalization efforts in ML, operations research, and scientific computing. Theoretically, it reifies the principle that formal reasoning model adaptation requires feedback-driven, verifier-informed loss shaping, not just data mixture or naive likelihood transfer.
Future Directions
Automatic curriculum discovery for even deeper mathematical subdomains, more aggressive leveraging of symbolic search traces, and a formal quantification of “preferred tactics” for arbitrary proof libraries represent logical next steps. Extension of the preference-learning framework to multi-agent settings or RL, as well as adaptation to larger parameter scales and other proof assistants, could further enhance coverage and robustness.
Conclusion
OptProver operationalizes continual training with rigorous utility-aware and perplexity-weighted preference learning, bridging the distributional chasm between competition proof corpora and undergraduate optimization formalization. The resulting system achieves state-of-the-art in-domain accuracy (55.25% Pass@32) on Lean optimization problems without sacrificing generalization. This establishes a new paradigm for domain-adaptive formal theorem proving using LLMs (2604.23712).

