- The paper presents a counterfactual-guided, grammar-constrained LLM framework for refining safety operational rules in cyber-physical systems.
- It integrates minimal perturbation counterfactuals with strict syntax constraints to align simulation outcomes with engineered rules.
- Empirical evaluations show complete elimination of rule inconsistencies, emphasizing model-dependent performance and minimal rule changes.
Grammar-Constrained Safety Rule Refinement with LLMs and Counterfactual Evidence
Operational rules encode safety requirements for cyber-physical systems (CPS) such as autonomous driving controllers by specifying admissible regions over input variables, constrained by the Operational Design Domain (ODD). As real-world environments evolve, these hand-engineered operational rules often become inconsistent with observed system outcomes during simulation-based verification. This necessitates ongoing rule refinement to preserve correctness without broadening the safety envelope or changing requirements.
Previous approaches have engineered operational rules via formal specification mining, surrogate modeling, genetic programming, and temporal logic learning [gaaloul2021combining], but these typically optimize for template-based inference or parametric tuning without enforcing domain-specific grammar constraints. Recent advances in LLMs have enabled the automated construction and maintenance of safety specifications [nouri2024engineering, li2025automatic], yet existing validation focuses on syntactic compliance and not on semantic consistency with observed behavior. No prior work has combined counterfactual analysis with grammar-constrained LLMs for the targeted refinement of inconsistent operational rules, specifically within a fixed safety requirement and ODD.
Framework: Counterfactual-Guided, Grammar-Constrained Rule Refinement
The proposed framework systematically corrects inconsistent operational rules via integration of counterfactual reasoning and grammar-constrained LLMs, ensuring the refined rules remain interpretable, syntactically correct, and semantically valid.
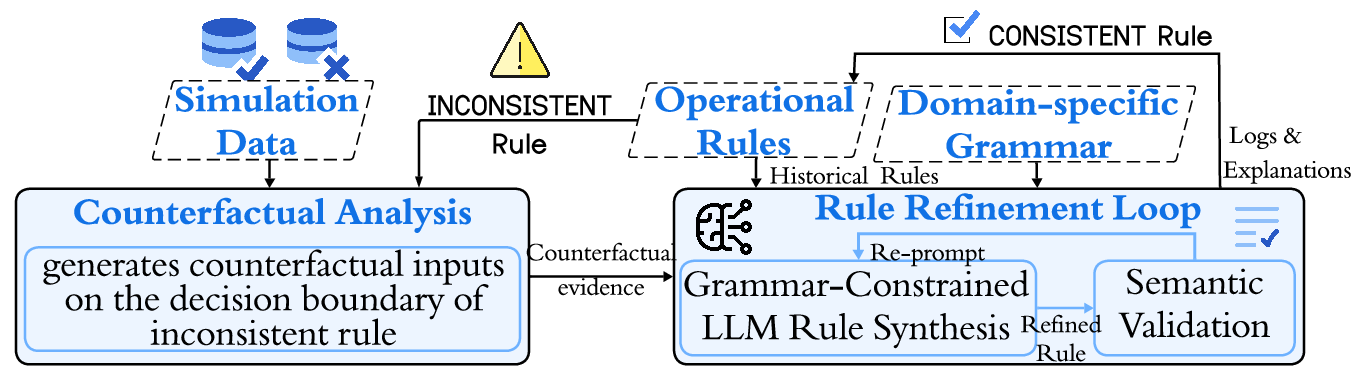
Figure 1: Overview of the operational rule refinement pipeline highlighting counterfactual generation, grammar-constrained LLM guidance, and semantic validation for rule set update.
Rule Representation and Grammar
Operational rules are logical expressions over input variables (e.g., ego vehicle speed, distance to front vehicle, lateral offset), encoded as hierarchical formulas per a domain grammar with a specified set of operators {∧,∨,<,>,≤,≥,=,=} and variables. Rules are evaluated on a labeled dataset of system executions; consistency is checked by matching rule verdicts against observed simulation outcomes.
Counterfactual Localization
For each inconsistency between a rule's verdict and observed outcome, the framework computes a minimal L1 perturbation to the input (counterfactual) that flips the outcome label, thereby localizing the boundary of the inconsistency. This step provides evidence for LLM guidance on targeted local changes that restore alignment without excessive generalization or drift.
Grammar-Constrained LLM Refinement Loop
Given the counterfactual evidence, grammar, and historical rules, an LLM is prompted with explicit syntax constraints and tasked to generate minimally revised candidate rules. The refinement loop enforces:
- Grammar compliance: By token-level whitelisting of predicates and domain variables.
- Semantic validation: Ensures no contradictory verdicts or out-of-ODD bounds, no introduction of unsupported operators or variables, and resolution of the initial inconsistency.
- Minimality: Prefers refinements that introduce the smallest changes required to resolve the inconsistency, preserving existing rule intent.
The process iterates until a candidate rule passes validation on the simulation suite. The output includes the refined rule, a detailed changelog, and an explanation.
Empirical Evaluation and LLM Variant Analysis
The framework was applied to an autonomous driving subsystem (ADS) implementing both lateral and longitudinal control. Using 198 simulation-based executions with labeled pass/fail outcomes, an initial pass rule obtained via genetic programming [gaaloul2021combining] demonstrated 27 inconsistencies (Decisiveness Gain, DG: 0.86). Applying the grammar-constrained, counterfactual-guided LLM framework eliminated all mismatches (DG: 1.0), surpassing the baseline.
A systematic variant study across eight state-of-the-art LLMs (e.g., GPT-5, Gemini, Claude Sonnet, DeepSeek, Qwen3) revealed model-dependent differences in the following evaluation dimensions:
- Grammar Compliance (GC): Ranged from 0.5 (DeepSeek DeepThinking) to 1.0 (most LLMs when grammar constraints are strictly enforced).
- Semantic Validity (SV): Strongest in GPT5 Thinking and Gemini Flash 2.5; weaker in LLMs prone to introducing unsupported bounds or variables.
- Interpretability (I): Highest in Claude Sonnet 4.5; models that propose more extensive changes offer fuller justifications.
- Change Minimality (CM): GPT5 Thinking and DeepSeek Normal demonstrated favorable minimality; Gemini Pro 2.5 and Claude Sonnet 4.5 produced overconstrained rules.
Key empirical findings:
- All LLMs, when guided by grammar and counterfactual evidence, succeeded in producing rules eliminating initial inconsistencies.
- However, some LLMs introduced over-conservative or semantically unjustified refinements, such as unnecessary variable constraints not present in the ODD.
- Output structure and variable naming can subtly break grammar compliance, even if the semantic intent appears valid.
- More significant rule edits were often accompanied by richer explanations and critique, potentially aiding human interpretability.
These results indicate that grammar-constrained LLM refinement, augmented with counterfactual evidence, is both effective for eliminating observed inconsistencies and sensitive to model selection and validation strategies.
Implications, Limitations, and Theoretical Insights
Grammar-constrained LLMs with counterfactual evidence can act as powerful refinement agents for safety operational rules. The procedural incorporation of counterfactuals ensures that refinements are grounded in observed behavioral boundaries. However, grammar enforcement alone does not guarantee semantic soundness; overfitting and unjustified conservative constraints remain risks, especially when LLMs extrapolate beyond the ODD or provided evidence.
The model-dependent nature of the refinement loop exposes safety risks in language-in-the-loop settings: minor, undetected syntax deviations or ungrounded refinements have potential to compromise safety assurances or increase false negatives in operational deployments. Formal methods such as SMT-based contradiction checks are necessary but insufficient; external validation via full ODD regression or adversarial simulation must be integrated for robust assurance.
Further, the framework highlights the importance of strict parser-based grammar acceptance and simulation-based falsification to mitigate the risks introduced by unconstrained generative models. Change minimality should be independently penalized to discourage unexplained or spurious logical modifications.
Theoretically, this study advances the intersection of interpretable specification refinement, LLM semantic alignment, and formal safety assurance, illuminating both the value and the hazards of automated rule evolution under constrained domains.
Conclusion
This work introduces a grammar-constrained, counterfactual-guided LLM refinement framework addressing the ongoing need to update safety operational rules in CPS as system behavior and environments evolve. The integration of local evidence and strict grammar constraints enables the effective, minimal, and explainable correction of inconsistent rules while surfacing the critical dependence on LLM quality and validation strategies.
Practical deployment of such systems necessitates further research into automated parser enforcement, simulation-based semantic validation, and minimality-driven edit penalties. Future directions include extending validation studies across multiple subsystems, ODDs, and requirements, integrating robust adversarial test mechanisms, and benchmarking against alternative interpretable rule learning paradigms.
This framework provides both a methodological advance in LLM-guided rule refinement and a cautionary foundation for semantic validation protocols in safety-critical CPS software evolution.

