- The paper introduces a dual-LLM framework that integrates structured policy retrieval and independent JudgeLLM verification to ensure safe mission orchestration in IoBT environments.
- It employs edge-deployed LLMs with closed-loop telemetry, achieving robust performance with low latency even in complex, multi-event scenarios.
- The study demonstrates that explicit policy grounding and prompt compliance significantly enhance operational reliability and mitigate risks of hallucinated or unsafe actions.
Policy-Aware Edge LLM-RAG Framework for IoBT Mission Orchestration
Introduction and Motivation
The paper presents PA-LLM-RAG, a policy-aware, edge-deployed framework that integrates LLMs with Retrieval-Augmented Generation (RAG) for the orchestration of mission-critical tasks in Internet of Battlefield Things (IoBT) environments (2604.09493). IoBT scenarios, encompassing UAV/UGV teams and distributed sensors, impose stringent constraints on reliability, safety, latency, and adherence to dynamic operational policies. Direct LLM-driven command and control in this domain raises substantial risks, including hallucinated or policy-violating outputs that can compromise mission safety and security.
The proposed approach incorporates structured retrieval of operational policy and system telemetry, feeding both into the LLM to inform generation while enforcing policy compliance. Independent command verification via a JudgeLLM module introduces an additional safeguard, ensuring that candidate mission plans are cross-examined for both policy violations and execution alignment prior to actuation.
Framework Architecture
The PA-LLM-RAG framework employs a hybrid architecture, detailed as follows:
- Semantic Policy Retrieval: Given a user- or event-initiated mission command, a retrieval module queries the knowledge base using fuzzy and token-overlap measures to identify the most contextually relevant operational rules and current telemetry.
- Contextual Prompt Construction: The system constructs a deterministic, structured prompt that merges mission intent, retrieved policies, telemetry, and response format instructions, constraining the LLM’s generative process.
- Edge-Deployed LLM for Reasoning: The core LLM (e.g., Gemma-2B, Mistral-7B) is hosted locally, selected and quantized to meet edge computing constraints while preserving policy-aware reasoning capabilities.
- JudgeLLM-Based Verification: Generated mission plans are subjected to an independent LLM-based judge configured with strict validation prompts. This layer assesses rule satisfaction, operational correctness, and post-hoc telemetry to validate both command intent and outcome.
- Closed-Loop Telemetry: Upon execution, devices return telemetry enabling ongoing feedback. The system maintains up-to-date state information, facilitating closed-loop adaptation for mission orchestration.
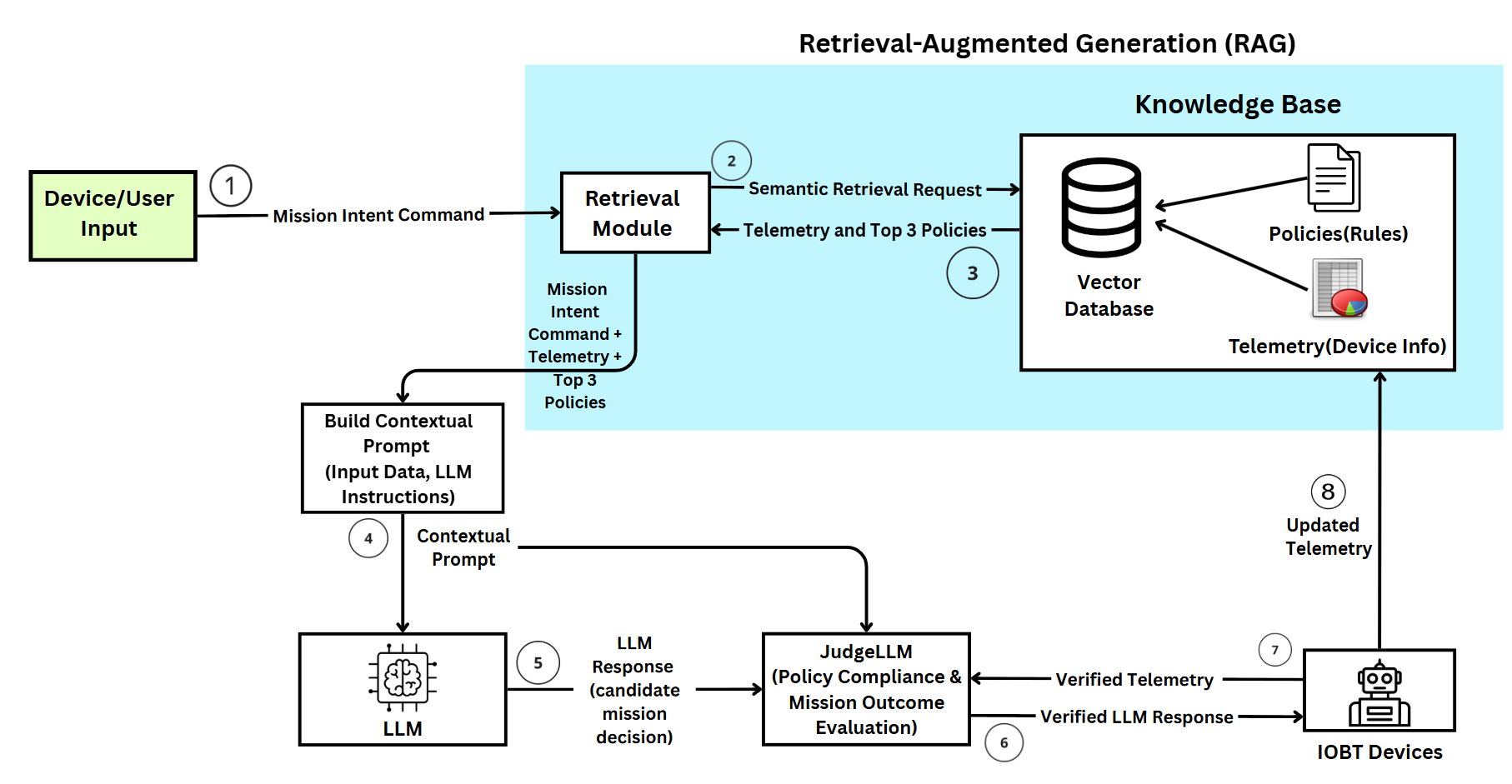
Figure 1: PA-LLM-RAG architecture outlining semantic retrieval, policy grounding, dual-LLM verification, and closed-loop telemetry feedback enabling safe IoBT orchestration.
Event-Driven Workflow and Operational Scenarios
Typical operational workflows in PA-LLM-RAG begin with event-driven triggers (e.g., unknown vehicle detection), passing through policy-aware branching and rule-grounded LLM reasoning, with all mission plans subject to JudgeLLM verification. Multi-event scenarios are supported via deterministic event handling and prioritized queuing, ensuring both mission progression and the maintenance of policy constraints (e.g., persistent gate coverage, asset handover on battery alerts).
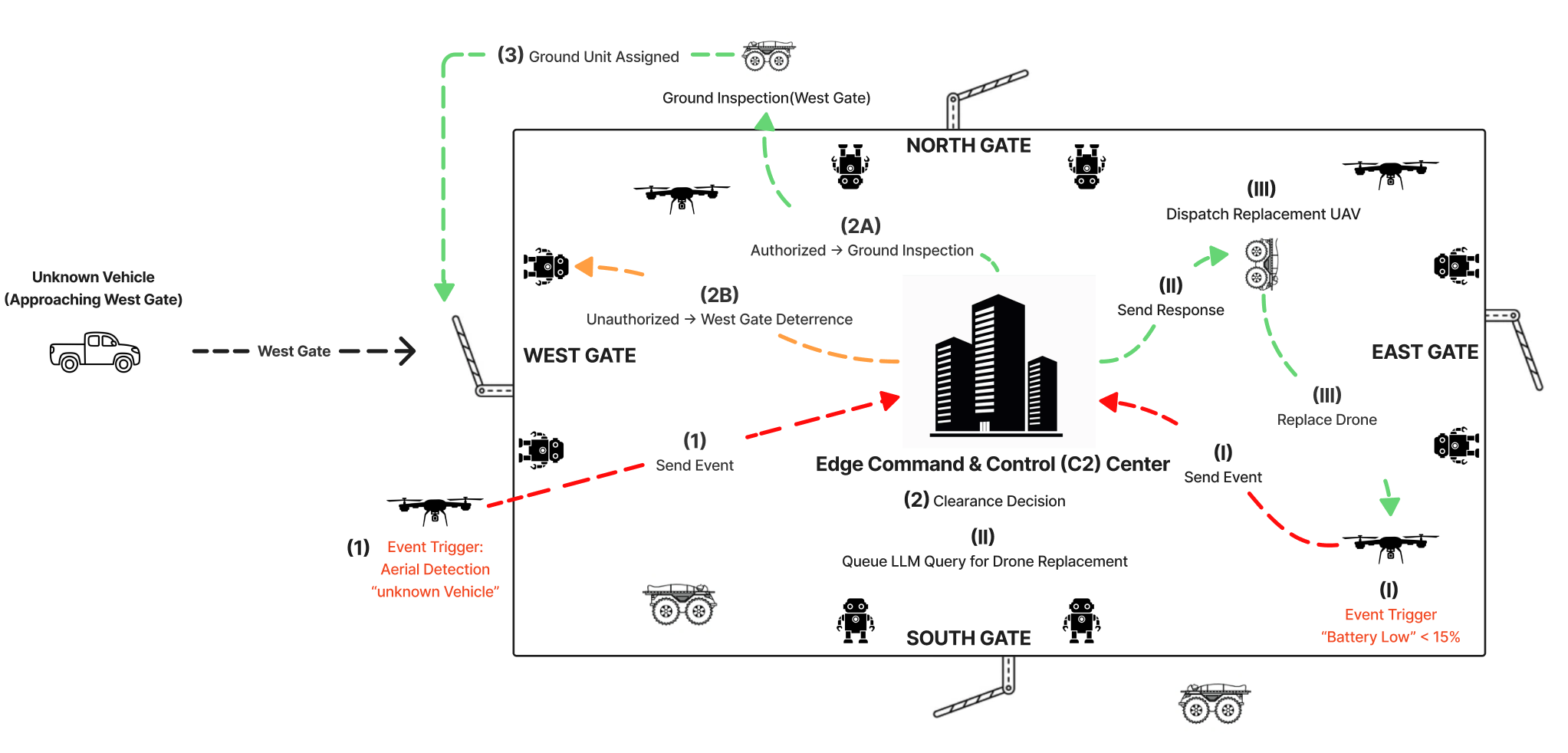
Figure 2: Event-driven workflow depicting detection, context retrieval, policy-aware LLM reasoning, JudgeLLM validation, and multi-event handling.
Experimental Evaluation
A high-fidelity RoboDK simulation is used to empirically validate PA-LLM-RAG under ten representative mission scenarios: steady-state control, unknown vehicle engagement, coverage loss, concurrent events, and explicit policy-violation tests. Four open-source LLMs (Gemma-2B, LLaMA-3.1-8B, Mistral-7B, Qwen-2.5-7B) are evaluated in CPU-only edge setups using 4-bit quantization. Mission prompts and policy sets are standardized for cross-model comparability.
Key Results
- Mission Success: Under both strict and hybrid evaluation, Gemma-2B achieves 100% mission success with latency of 4.17s, demonstrating robust policy adherence and responsiveness. Contrastingly, Qwen-2.5-7B shows the lowest overall success, highlighting significant inter-model variability even among similarly scaled LLMs.
- Scenario Complexity: Reliability divergence increases with scenario complexity. Multi-event and policy-constrained commands reveal failures in some models to preserve checkpoint coverage or avoid rule violations, despite reasonable output under looser evaluation.
- Latency vs. Robustness Tradeoff: Smaller models (Gemma-2B) maintain lower end-to-end latency, critical for edge deployment, but do not sacrifice reliability compared to larger models, challenging assumptions of monotonic accuracy gain with scale in policy-constrained reasoning.
- JudgeLLM Efficacy: The dual LLM/judge setup eliminates hallucinated or invalid actions prior to execution, substantially reducing the risk envelope typical in LLM-enabled control.
Theoretical and Practical Implications
The research yields several strong and, in some cases, contradictory claims relative to previous work:
- Explicit Policy Grounding as Essential: The integration of policy retrieval into both generation and validation is found essential—without such enforcement, LLMs frequently produce actions that, while superficially aligned with intent, violate mission constraints.
- LLM Scale Is Not a Guarantee of Robustness: Larger parameter LLMs do not universally achieve higher reliability in policy-dense, real-time control domains, especially under edge constraints.
- Model Robustness vs. Prompt Compliance: The best-performing configurations are tightly prompted, format-constrained, and externally validated; unrestricted natural language interaction is unsafe in adversarial or mission-critical settings.
These findings have strong implications for LLM deployment in autonomous cyber-physical systems. Policy-aware RAG, dual LLM validation, and closed-loop telemetry must be standard for safety-critical applications, extending beyond battlefield to critical infrastructure and industrial IoT control.
Limitations and Future Directions
Primary limitations include the reliance on simulation (RoboDK) and the limited scale (single checkpoint deployment). Physical-world validation, large-scale multi-agent scenarios, adversarial threat modeling (prompt injection/KB poisoning), and JudgeLLM hardening are identified as future work. Distributed orchestration and resilience under variable hardware and network conditions must be examined to ensure framework viability in operational battlefield ecosystems.
Conclusion
PA-LLM-RAG systematically addresses the safety, reliability, and policy-compliance gaps inherent in LLM-driven IoBT orchestration. By combining retrieval-augmented reasoning, explicit operational rule grounding, and dual LLM validation, the framework enables intent-driven autonomy while constraining unsafe action generation. Empirical evidence challenges assumptions of LLM scaling benefits and highlights the necessity of explicit policy structures. The framework establishes a foundational architecture for future edge-centric, adaptive, and trustworthy autonomy in real-world IoBT and other safety-critical CPS domains.