- The paper demonstrates that coordinate-wise Kolmogorov distances decay as O(d⁻¹ᐟ⁵), ensuring convergence of individual components.
- It employs Fourier analysis and concentration techniques to establish sharp lower bounds on the full-vector Wasserstein distance.
- The findings clarify that while two-block Hadamard rotations suit coordinate-specific tasks, they may inadequately capture global geometric properties.
Uniform random rotations serve as a core primitive in randomized numerical linear algebra, dimension reduction, kernel approximation, derivative-free optimization, compressed AI pipelines, and communication-efficient learning. Generating and applying a Haar-distributed rotation in Rd incurs O(d2) time and O(d2) storage, motivating practical structured surrogates. A widely-adopted construction, the so-called two-block Hadamard rotation, composes independent sign-diagonal matrices D(1),D(2) and Walsh-Hadamard transforms in the operator: T(u)=d1HD(1)HD(2)u
where H is the Walsh-Hadamard matrix (d=2m), D(1),D(2) are i.i.d.\ random sign diagonals, and u∈Rd. Empirically, this "two-block" structured transform is widely used in large-scale inference and quantization pipelines, but clear theoretical guarantees about its proximity to true random rotations are incomplete.
This work rigorously quantifies in which formal probabilistic senses T(u) approximates O(d2)0 (O(d2)1 Haar distributed) and where such a replacement fails, yielding both positive and negative results for high-dimensional regimes.
Main Results: Marginal Approximation vs. Global Discrepancy
Marginal Kolmogorov Approximation
The central positive result establishes that for any input O(d2)2 on the unit sphere and any coordinate O(d2)3, the Kolmogorov distance between O(d2)4 and the corresponding coordinate of a Haar-rotated vector O(d2)5 decays as O(d2)6, uniformly over all O(d2)7 and O(d2)8. Explicitly, there exists a constant O(d2)9 such that
O(d2)0
where O(d2)1 denotes Kolmogorov distance.
This theoretical convergence aligns with practical needs in randomization algorithms relying primarily on coordinate-wise statistics (e.g., post-rotation quantization or coordinate-wise nonlinear compression).
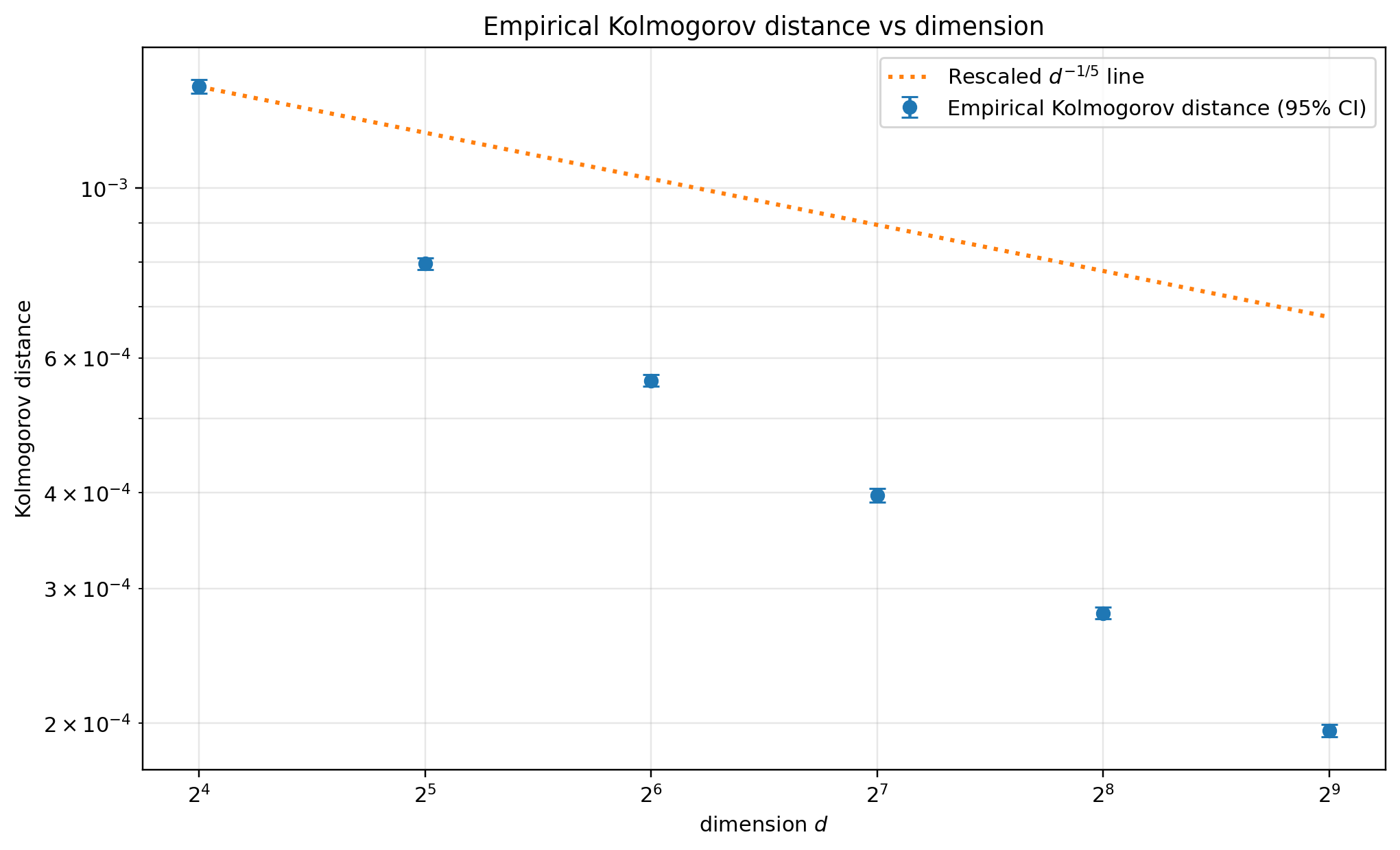
Figure 1: Empirical one-coordinate Kolmogorov distance versus dimension, showing mean and confidence intervals over random inputs, compared to the theoretical O(d2)2 upper-bound shape.
The figure demonstrates empirical decay rates of Kolmogorov distance, confirming that one-dimensional marginals of the two-block structured rotation become increasingly similar to those induced by the Haar measure.
Wasserstein Discrepancy in High Dimension
Contrastingly, on the level of the full vector distribution, the situation is fundamentally different. By constructing explicit test functions (specifically, the Euclidean distance to the embedded hypercube vertex set), the paper proves that the O(d2)3 Wasserstein distance between the law of O(d2)4 and O(d2)5 does not vanish but remains bounded away from zero as O(d2)6: O(d2)7
For fixed large O(d2)8, the supremum over O(d2)9 is at least D(1),D(2)0 for D(1),D(2)1 and at least D(1),D(2)2 for D(1),D(2)3.
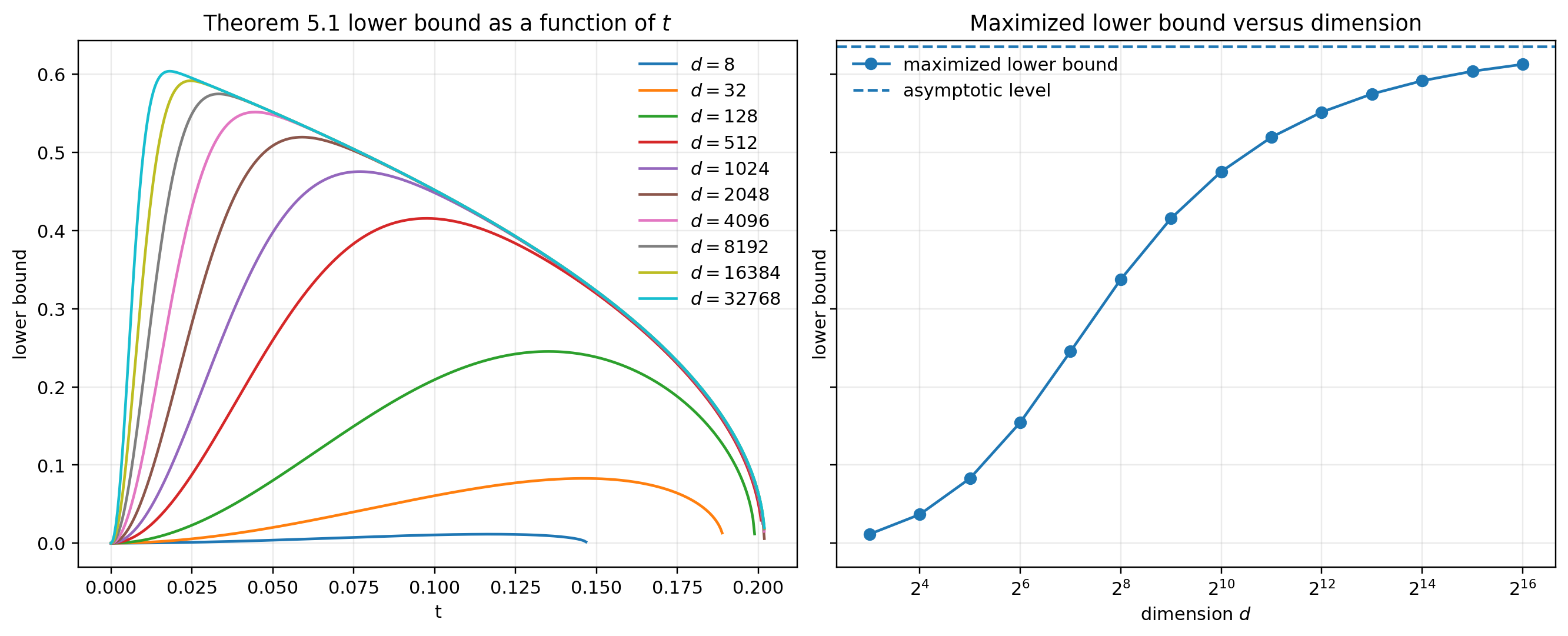
Figure 2: Lower-bound phenomenon: explicit non-vanishing Wasserstein distance as a function of dimension and parameter, visualizing the persistent global discrepancy.
The lower-bound argument is sharp for the "worst-case" (e.g., D(1),D(2)4), with matching upper and lower asymptotics, confirming that the two-block Hadamard is not a globally accurate surrogate for uniform rotation with respect to the joint law.
Technical Analysis
The positive coordinate-wise result proceeds via detailed conditioning arguments and characteristic function manipulations, reducing the distribution of each coordinate to a sum of essentially independent signed contributions. The key is Gaussian approximation via Fourier methods, together with sharp control of higher moments of the inner random coefficients arising from the two independent sign layers.
For the negative result, the structured law D(1),D(2)5 with D(1),D(2)6 is reducible to images of uniform distributions on the hypercube vertices under orthogonal transformation, whose separation from the Haar distribution is measured using Lipschitz test functions (distance to the embedded hypercube). Concentration inequalities for Lipschitz functions on the sphere, together with properties of D(1),D(2)7 norms for random points on the sphere, yield explicit lower bounds for the Wasserstein distance and establish non-vanishing separation in high dimension.
The analysis reveals a significant dichotomy: coordinate-level statistics converge in law, but joint high-dimensional structure remains imbalanced. Notably, this provides a rigorous theoretical explanation for empirical effectiveness in coordinate-focused algorithmic settings but cautions about global geometric or joint-distributional guarantees.
Practical and Theoretical Implications
These results decisively clarify when two-block structured Hadamard rotations can be treated as reliable surrogates for Haar rotations:
- For coordinate-wise functions (e.g., quantization, per-entry nonlinearities, coordinate thresholds), performance guarantees derived for Haar rotations are justifiable with only negligible asymptotic loss.
- For global geometric properties (e.g., distributional concentration, isoperimetry, or higher-order statistical interactions), structured Hadamard surrogates can substantially diverge: any transfer of Haar-based guarantees must be re-examined or supported empirically.
This distinction is critical for state-of-the-art AI compression and federated learning pipelines (e.g., DRIVE, EDEN, TurboQuant, RaBitQ) that employ fast structured orthogonal transforms (2604.23418).
By formalizing these limitations and strengths, the work motivates task-aware analyses when deploying structured random rotations. Results also suggest an open direction in developing alternative or more complex structured randomization strategies, or in quantifying their trade-offs under other probability metrics reflective of downstream algorithm requirements.
Conclusion
This paper rigorously delineates the high-dimensional approximation behavior of two-block structured Hadamard rotations toward uniform random rotations. While coordinate-wise convergence is rapid and supports their widespread adoption in coordinate-centric randomized algorithms, a persistent global distributional gap remains, precluding them as total replacements for true Haar measure in applications relying on global random orthogonality. The implications affect both theory-driven algorithm design and the principled justification of emerging structured compression pipelines for modern AI systems.