- The paper introduces the OSI property, a relaxation of OSE, enabling faster randomized linear algebra with structured, sparse sketching matrices.
- Empirical results demonstrate that constructions like SparseStack and SparseRTT achieve up to two orders of magnitude speedup with accuracy comparable to Gaussian sketches.
- Applications in scientific data compression and quantum partition function estimation validate the practical efficiency of the OSI-based algorithms.
Structured Random Matrices for Fast Randomized Linear Algebra
Introduction and Motivation
This paper develops a unified theoretical and practical framework for accelerating randomized linear algebra algorithms using structured random matrices. The central contribution is the introduction and systematic exploitation of the Oblivious Subspace Injection (OSI) property, a relaxation of the classical Oblivious Subspace Embedding (OSE) condition. The OSI abstraction enables the design and analysis of sketching algorithms that are both computationally efficient and empirically robust, even when the sketching matrices are highly structured (e.g., sparse, fast transform-based, or tensor-structured).
The authors demonstrate that many widely used randomized algorithms for low-rank approximation and least-squares regression can be implemented with OSIs, yielding near-optimal error guarantees and significant computational savings. The paper provides both theoretical analysis and extensive empirical evidence, including applications to scientific data compression and quantum partition function estimation.
The OSI Property: A New Abstraction
The OSI property is defined for a random matrix Φ∈Fd×k (over F=R or C) as follows:
- Isotropy: E∥Φ∗x∥22=∥x∥22 for all x∈Fd.
- Injectivity: For any fixed r-dimensional subspace V⊆Fd, with high probability, ∥Φ∗v∥22≥α∥v∥22 for all v∈V.
Unlike OSEs, OSIs do not require uniform control on the dilation (upper bound) of the embedding, only on the injectivity (lower bound). This relaxation is shown to be sufficient for the correctness of many randomized algorithms, and it allows for the use of much sparser or more structured sketching matrices.
The empirical study demonstrates that structured random matrices (e.g., SparseStack, SparseRTT, Khatri–Rao) achieve approximation errors nearly indistinguishable from Gaussian sketches across a large and diverse testbed of real-world matrices.
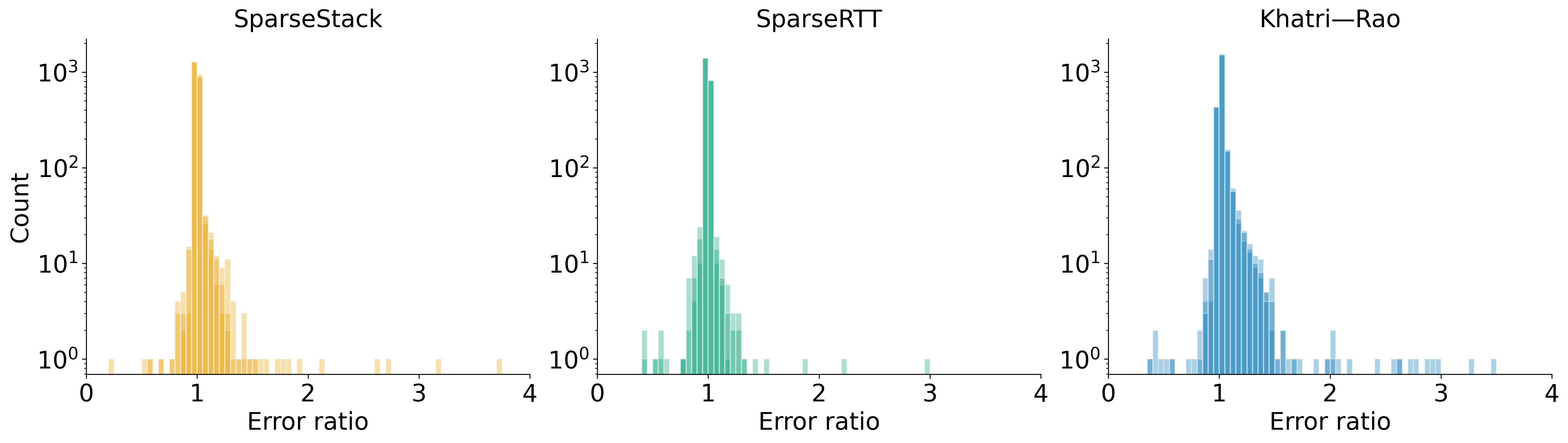
Figure 1: Histograms of the error ratio between structured and Gaussian sketches for randomized SVD on 2,314 SuiteSparse matrices; worst-case error ratio never exceeds 4, and structured sketches sometimes outperform Gaussians.
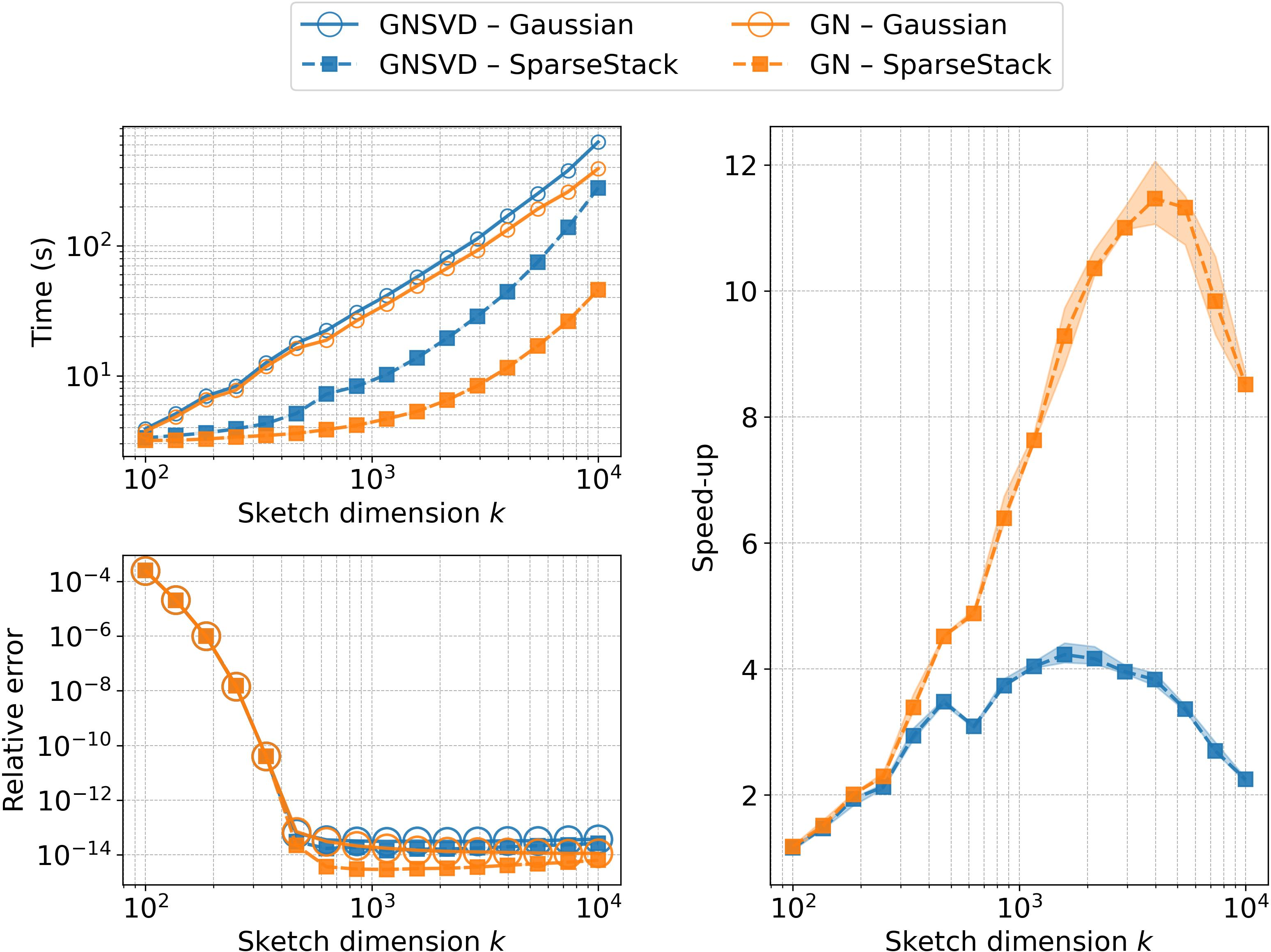
The computational advantage is substantial: for large matrices, sparse sketches can reduce the sketching time by up to two orders of magnitude compared to dense Gaussian sketches.
Sparse Sketching Matrices
Sparse random matrices, particularly the SparseStack construction, are analyzed in detail. The SparseStack is a concatenation of several CountSketch matrices, each with a small number of nonzeros per row. Theoretical results show that, for embedding dimension k=O(r) and row sparsity ζ=O(logr), SparseStack is an (r,α)-OSI with constant α. Empirically, even constant sparsity (ζ=4) suffices for robust performance.
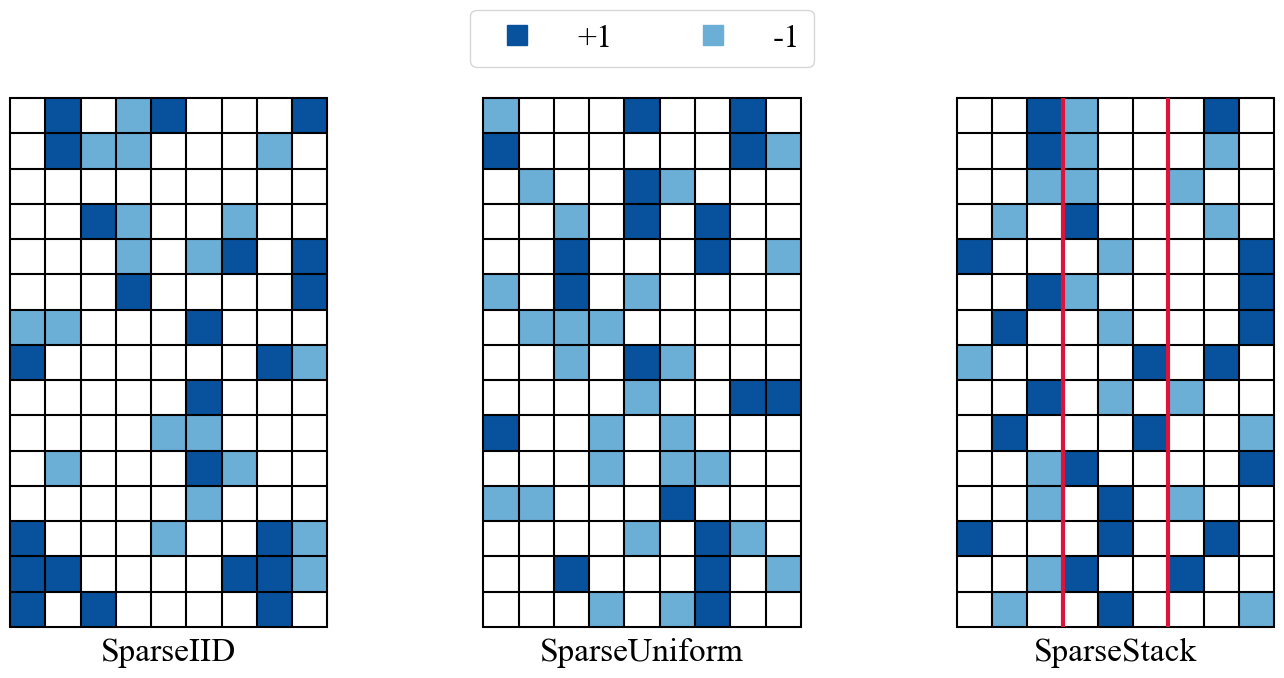
Figure 2: Sparsity patterns for several sparse sketching matrices, illustrating the structural differences between SparseIID, SparseUniform, and SparseStack.
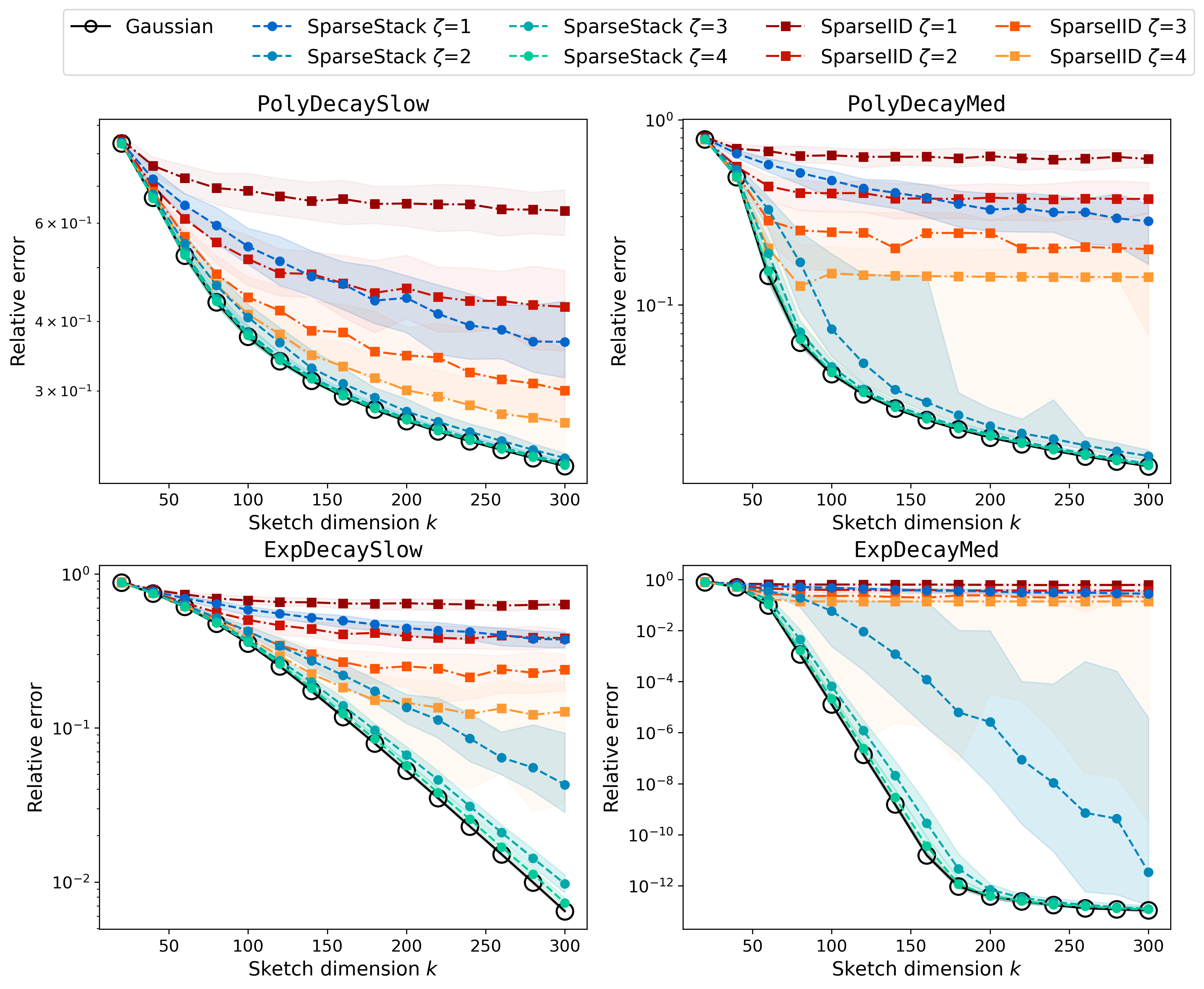
Figure 3: Relative error of RSVD using SparseStack and SparseIID sketches; SparseStack with ζ=4 matches Gaussian accuracy, while SparseIID can fail for rapidly decaying spectra.
The SparseRTT construction combines a random diagonal, a fast trigonometric transform (e.g., DCT, DFT, WHT), and a sparse sampling matrix. The authors show that, with column sparsity ξ=O(logr) and embedding dimension k=O(r), SparseRTT achieves the OSI property and supports sketching in O(ndlogr) time for an n×d input.
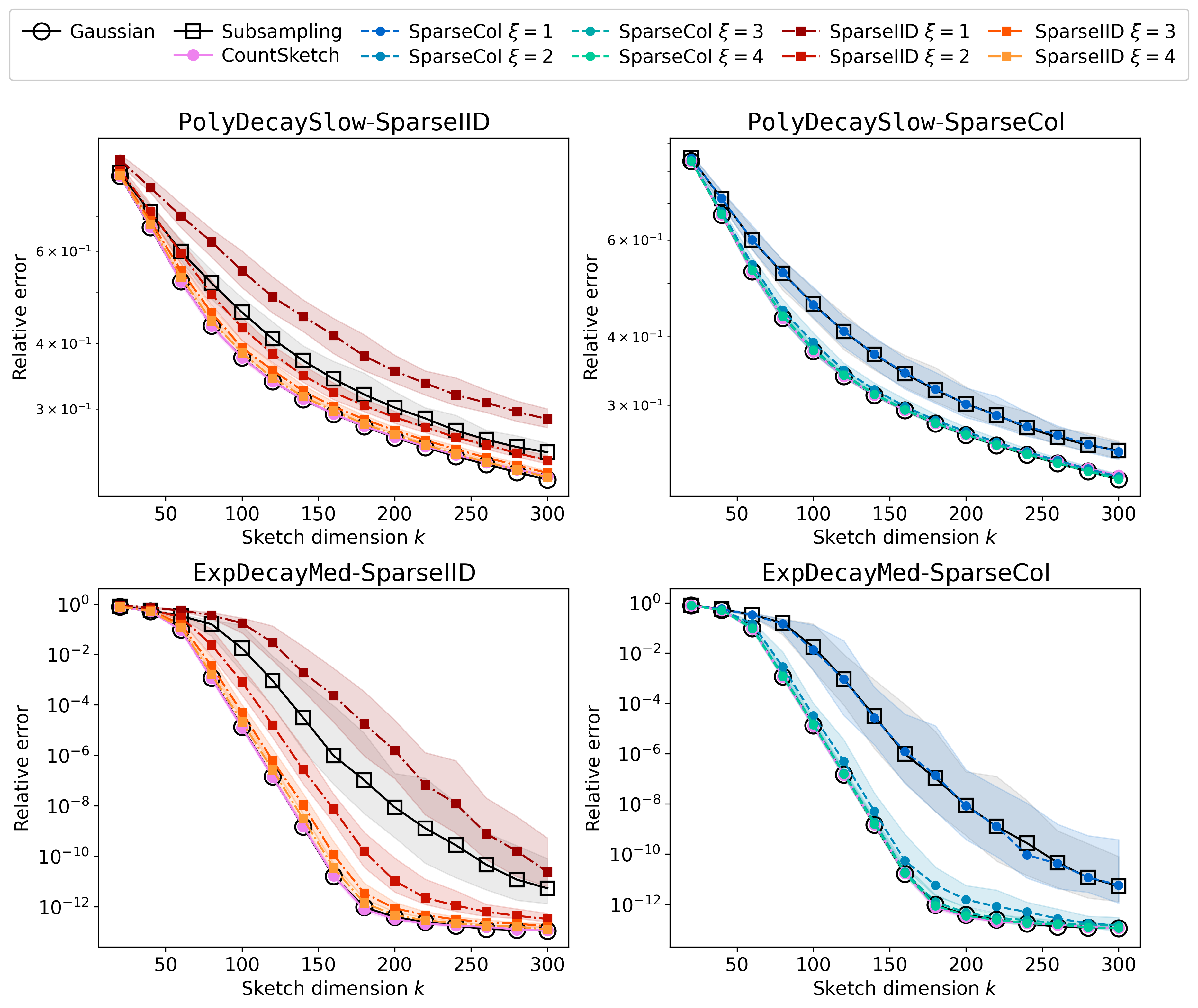
Figure 4: Relative error of RSVD using various fast trigonometric transform-based sketches; SparseCol sampling achieves superior accuracy at minimal sparsity.
Khatri–Rao and Tensor-Structured Sketches
For tensor-structured problems, the paper analyzes Khatri–Rao test matrices, where each column is a Kronecker product of independent random vectors. Theoretical results reveal an exponential dependence of the required embedding dimension on the tensor order ℓ for constant injectivity, but also show that for continuous base distributions, proportional embedding dimension is possible at the cost of exponentially small injectivity.
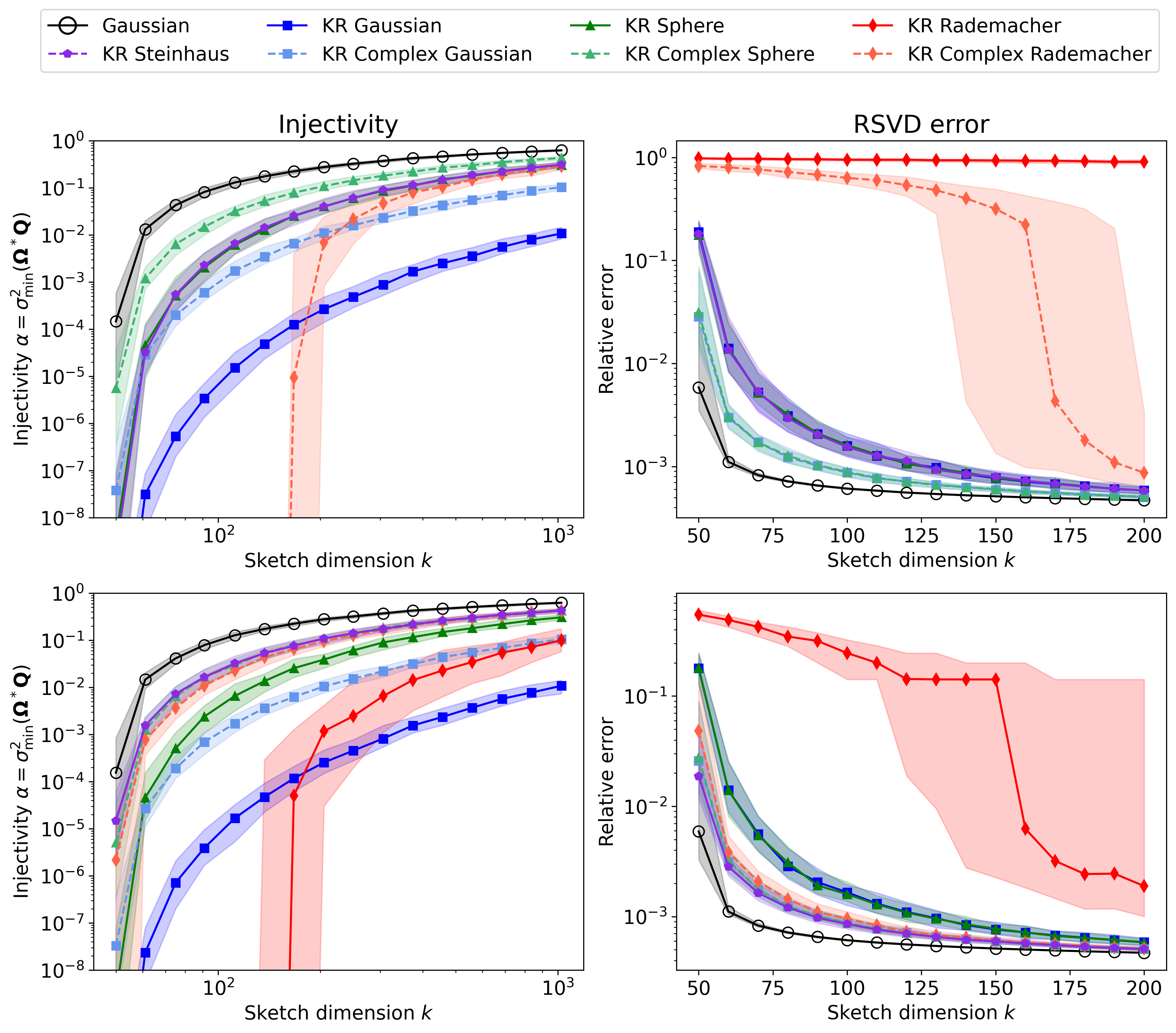
Figure 5: Injectivity and RSVD error for Khatri–Rao sketches with various base distributions; real Rademacher fails catastrophically, while complex spherical and Steinhaus distributions are robust.
Scientific Applications
The practical impact of these methods is demonstrated in two scientific domains:
Theoretical Techniques for OSI Analysis
The paper develops and applies several probabilistic tools for establishing the OSI property:
- Fourth-Moment Bounds: Used for Khatri–Rao sketches with constant injectivity.
- Small-Ball Probabilities: Enable proportional embedding dimension for continuous base distributions.
- Gaussian Comparison: Provides sharp lower bounds for the minimum singular value of sparse sketching matrices.
- Matrix Concentration: Used for classical OSE analysis, but shown to be suboptimal for OSI.
Implications and Future Directions
The OSI framework unifies the analysis of a broad class of structured random matrices, enabling the design of faster and more resource-efficient randomized linear algebra algorithms. The empirical and theoretical results challenge the prevailing view that only OSEs (and thus, typically, dense Gaussian sketches) are suitable for high-quality randomized algorithms. The evidence supports the deployment of highly sparse and structured sketches in large-scale scientific and machine learning applications.
Notably, the paper provides strong numerical evidence and theoretical justification that constant-factor error guarantees are sufficient for most practical applications, and that the OSI property is both necessary and sufficient for many randomized algorithms. This opens the door to further research on even more efficient sketching constructions, as well as the extension of the OSI framework to other algorithmic domains.
Conclusion
This work establishes the OSI property as a central abstraction for the design and analysis of fast randomized linear algebra algorithms with structured random matrices. By decoupling the requirements for injectivity and dilation, the authors enable the use of highly efficient sketching matrices without sacrificing output quality. The theoretical framework is complemented by extensive empirical validation and practical guidance, making the results immediately applicable to large-scale scientific and data-driven computing. Future research may focus on extending OSI-based analysis to broader classes of algorithms and exploring the limits of sparsity and structure in randomized numerical linear algebra.