- The paper introduces MOCA, which modularizes treatment and outcome modeling using transformers with one-way cross-attention to prevent reverse information flow.
- It employs gradient blocking to enforce causal ordering, resulting in lower bias and RMSE in treatment effect estimation across nonlinear and heavy-tailed scenarios.
- Empirical evaluations on simulation and real datasets demonstrate MOCA's robustness and improved performance compared to classical and contemporary methods.
Motivation and Background
Causal inference from observational data is critically dependent on reliable confounder adjustment, especially when treatment assignment and outcome mechanisms are high-dimensional, nonlinear, or otherwise complex. Conventional estimators—such as inverse probability weighting (IPW) and augmented inverse probability weighting (AIPW)—are robust under correct model specification but are known to be unstable in adverse settings where propensity scores become extreme, or when confounding structures deviate from linearity. Machine learning and representation learning approaches, including T-learner, X-learner, TARNet, and DragonNet, have provided greater flexibility for estimating individual-level treatment effects (ITE), particularly the conditional average treatment effect (CATE). Despite their empirical success, joint training strategies underlying such neural approaches can facilitate undesirable information flow from outcome modeling to treatment modeling, undermining causal interpretability and theoretical guarantees.
MOCA (Modular One-way Causal Attention) is introduced as a transformer-based framework designed to directly address this challenge by modularizing the causal estimation process and constraining information flow via one-way attention and explicit feedback cutting. The theoretical foundation draws on advances in attention mechanisms, modular Bayesian inference, and the necessity to preserve the independence of treatment modeling in accordance with causal inference principles.
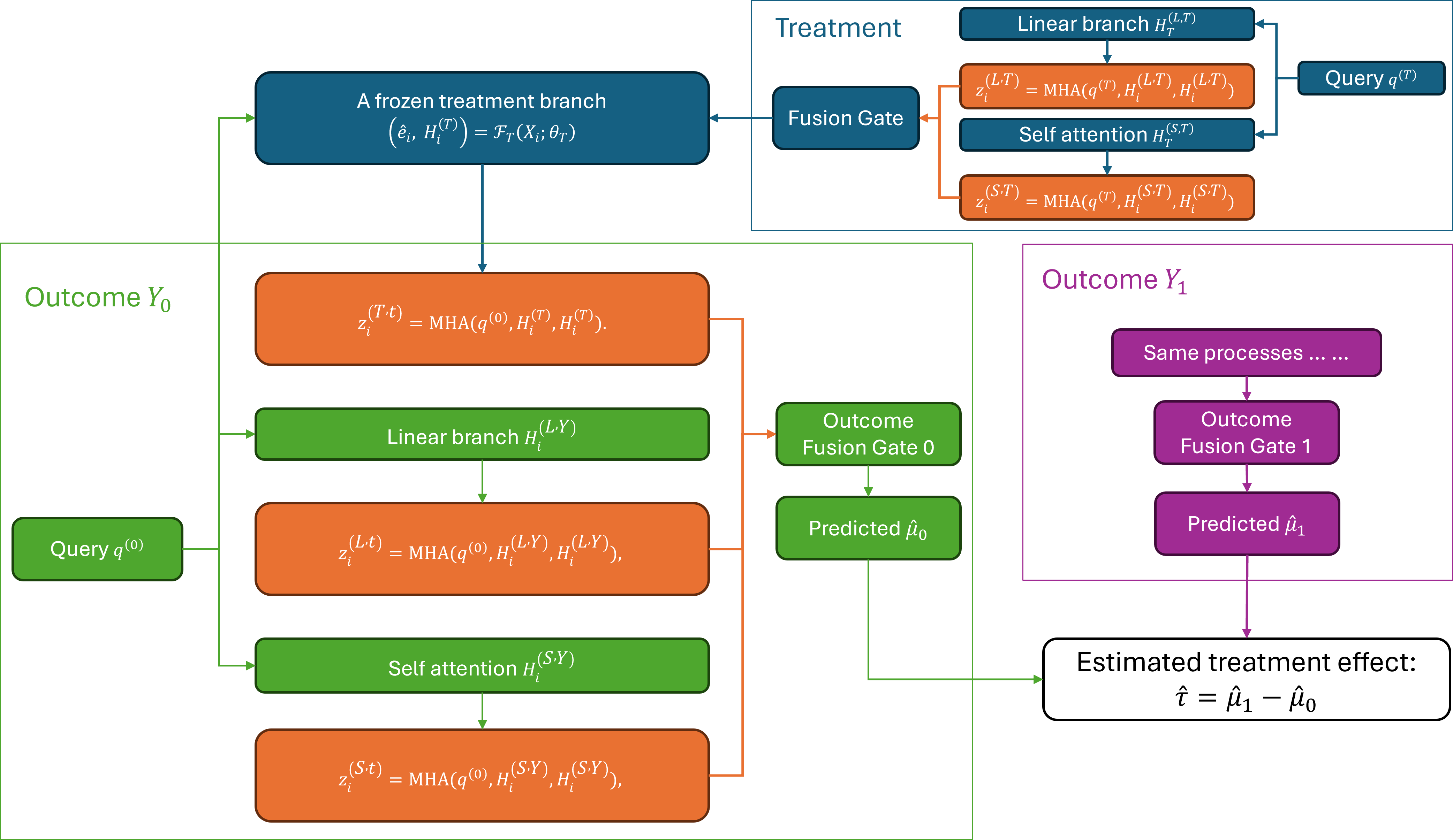
Figure 1: MOCA’s modular transformer architecture with one-way cross-attention, separating treatment and outcome modeling.
Architecture and Algorithmic Innovations
MOCA consists of separate treatment and outcome modules, each implemented via transformer-based architectures capable of capturing both linear and nonlinear interactions in high-dimensional covariates. Scalar covariates are tokenized and embedded with learnable positional information, enabling the application of self-attention and feed-forward neural networks within each module. The treatment module captures propensity score-related representations using both linear and self-attention branches, subsequently integrating branch outputs via a gating mechanism informed by multi-head cross-attention from a global treatment query.
One-way Cross-attention and Feedback Cutting
A critical innovation of MOCA is its explicit restriction on information flow: outcome modules are allowed to access frozen treatment representations via cross-attention; however, gradients from the outcome loss are prevented from propagating back and updating the treatment module—realized via gradient detachment or stop-gradient operations. This “cutting feedback” design strictly adheres to causal ordering, reflecting the logic of modular Bayesian inference and enforcing a directed acyclic structure.
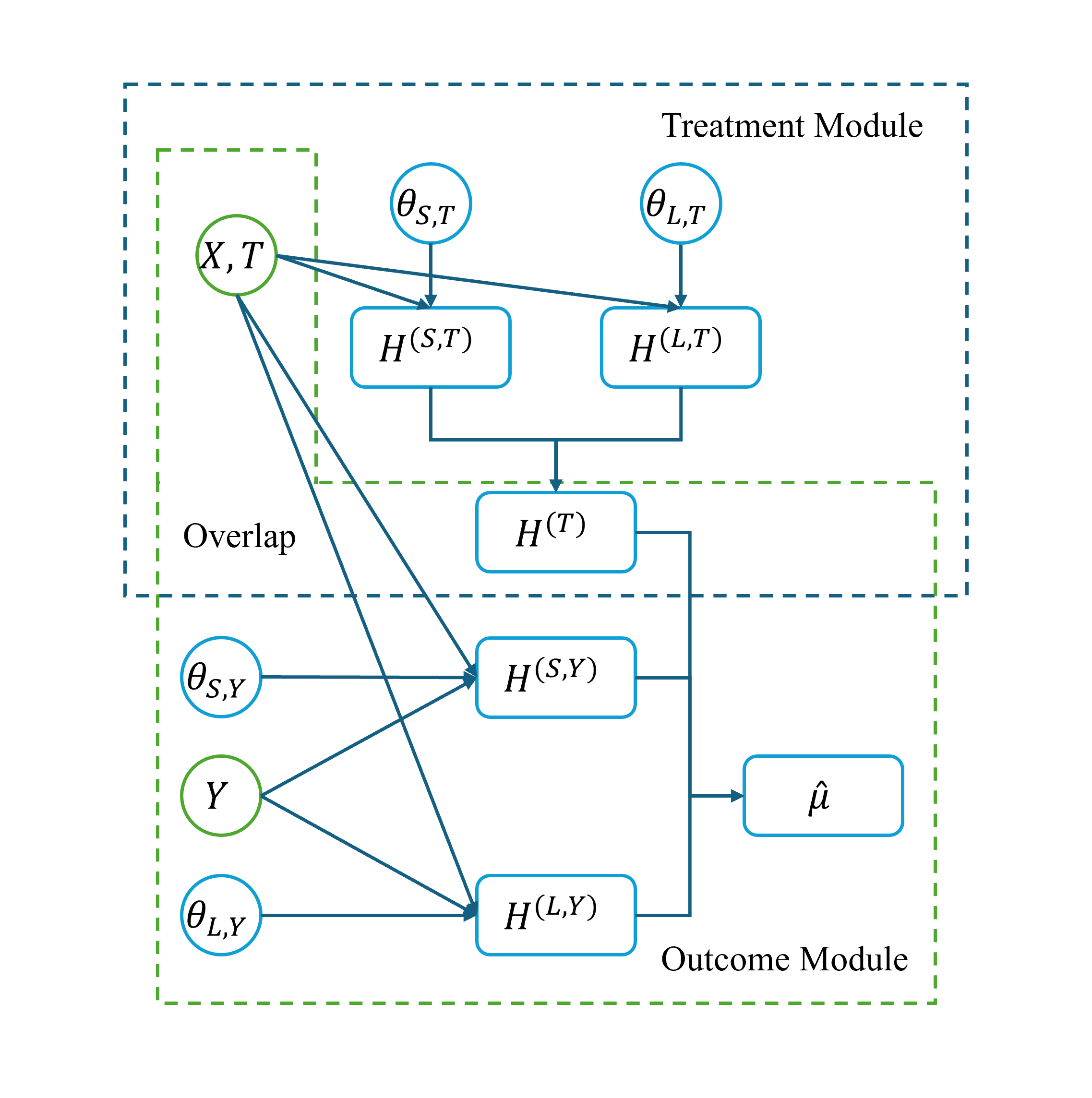
Figure 2: Information flow outlining modular separation and gradient feedback cutting between treatment and outcome modules in MOCA.
Each outcome head (corresponding to Y(0) and Y(1)) receives the covariate embeddings through its own linear and self-attention branches, in addition to the frozen treatment token. Fusion gates mix these sources, with arm-specific gating weights, followed by arm-specific prediction heads for estimating potential outcomes.
Training and Modularization Rules
MOCA is trained in two discrete stages: treatment module optimization (via binary cross-entropy on treatment assignment), followed by outcome module optimization (via factual outcome regression), with the treatment module’s parameters frozen in the latter stage. This aligns with four modularization rules borrowed from modular Bayesian analysis: self-contained modules, explicit ordering, feedback cutting, and cut-style downstream updates. The framework thus enforces directional independence and information isolation between treatment and outcome models, theoretically reducing information contamination and improving causal interpretability.
Empirical Evaluation
Simulation Studies
Comprehensive simulation experiments illustrate MOCA’s comparative performance across scenarios including linear, nonlinear, heavy-tailed, hidden confounding, and high-dimensional covariate structures. Two model variants are compared: MOCA with one-way cross-attention and feedback cutting, and a two-way version allowing bidirectional information flow.
Average Treatment Effect (ATE) Estimation
Results indicate MOCA—with its one-way design—exhibits competitive or improved performance relative to IPW, AIPW, X-learner, TARNet, and DragonNet in ATE estimation, with consistently lower bias and RMSE, particularly in settings with nonlinear or heavy-tailed covariate effects. In scenarios with hidden confounding, MOCA retains robust performance when sample size is small, outpacing competing methods in bias reduction.
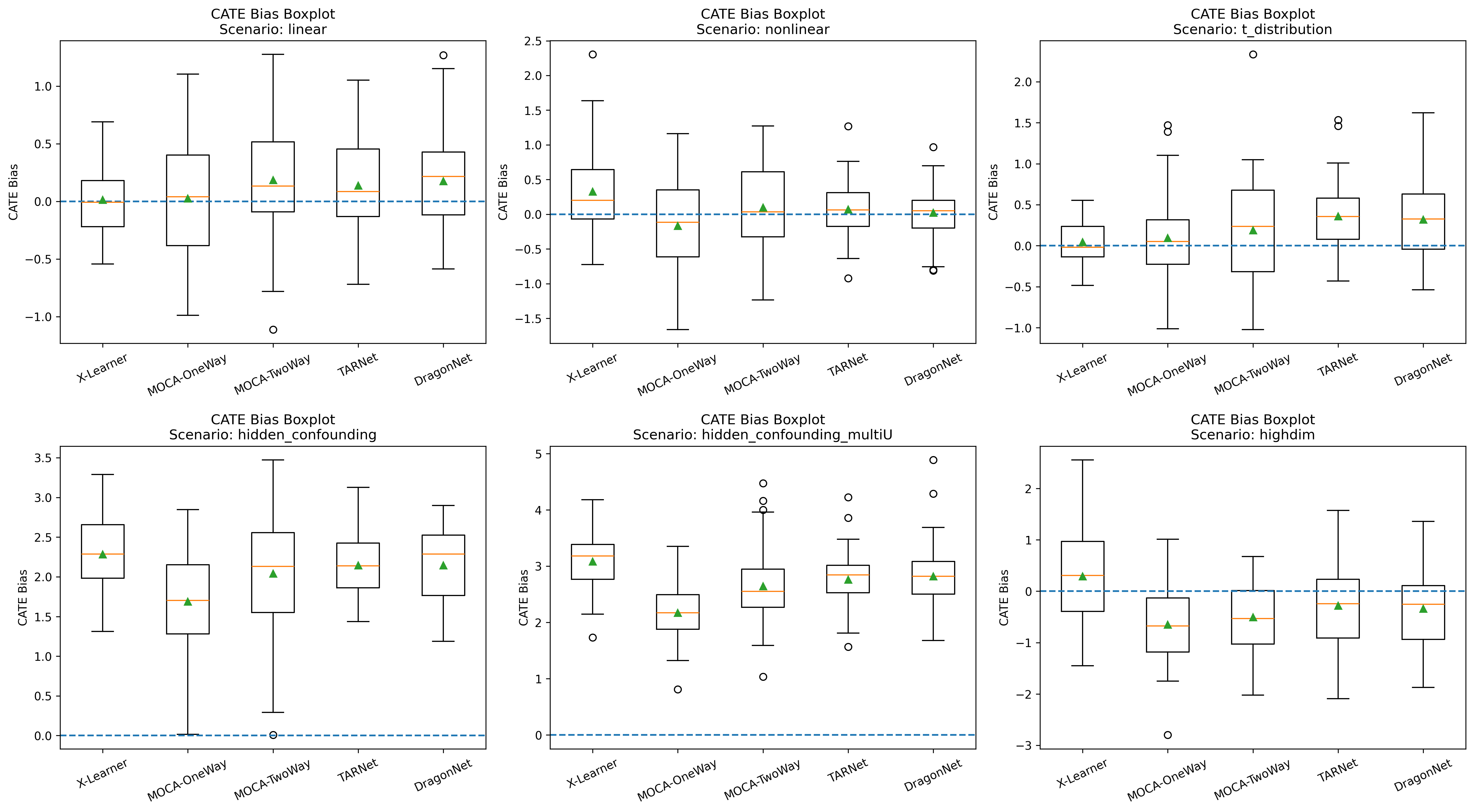
Figure 3: Boxplots of ATE estimation bias across all methods for test set size 100 highlight MOCA’s reduced bias and outliers.
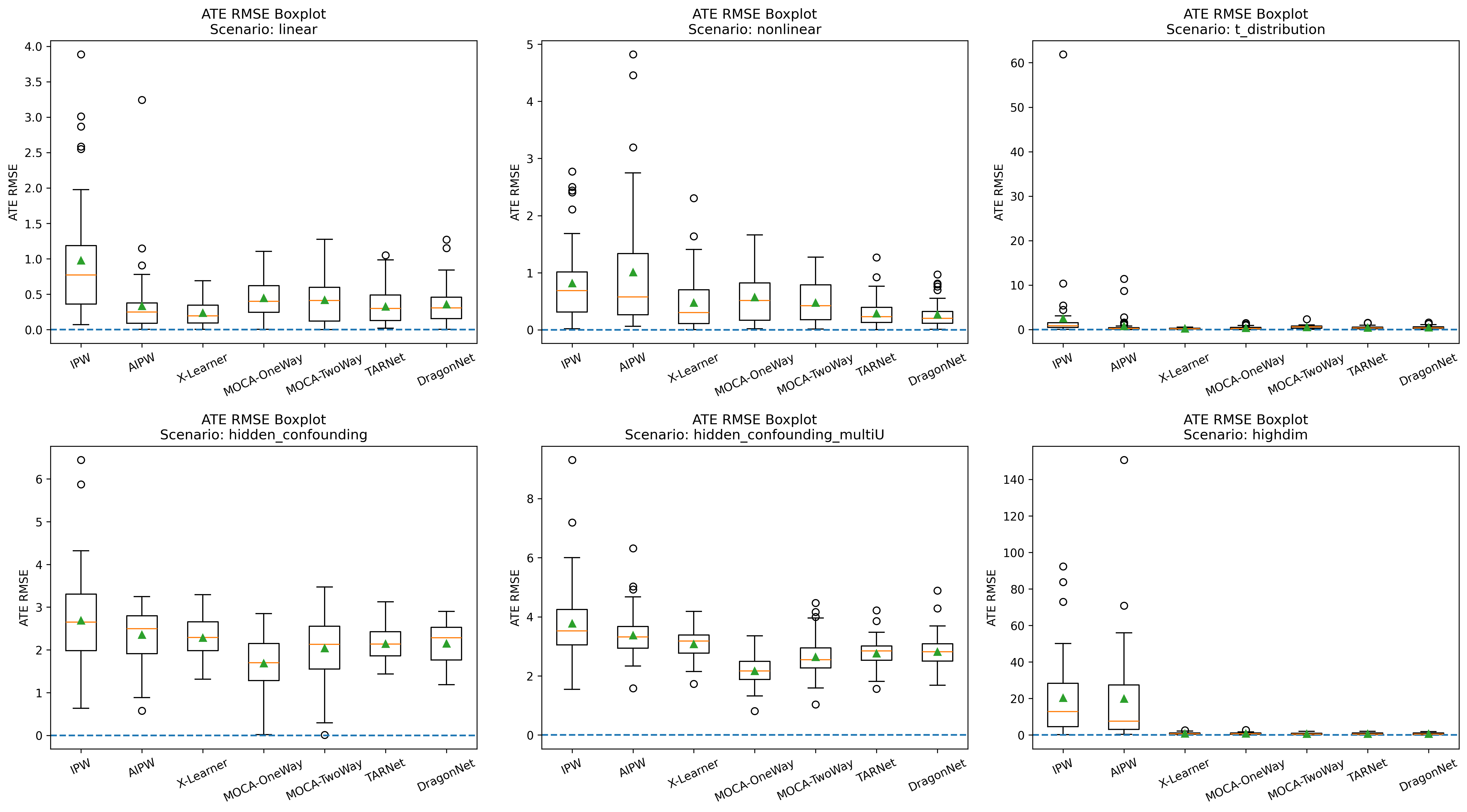
Figure 4: ATE RMSE boxplots for test size 100; MOCA’s one-way variant achieves stable, lower RMSE compared to classical estimators.
Performance degrades for all methods when ignorability is violated and sample size increases, reinforcing the necessity of valid identification assumptions.
Conditional Average Treatment Effect (CATE) Estimation
Machine learning approaches, including MOCA, provide CATE estimates for individual-level predictions. MOCA demonstrates effective CATE estimation across scenarios, especially when compared against representation learning models (TARNet, DragonNet) under heavy-tailed outcomes, where shared representations can be less stable.
Figure 5: Boxplot of CATE bias for test sample size 100 quantifies MOCA’s CATE prediction quality and competitive stability.
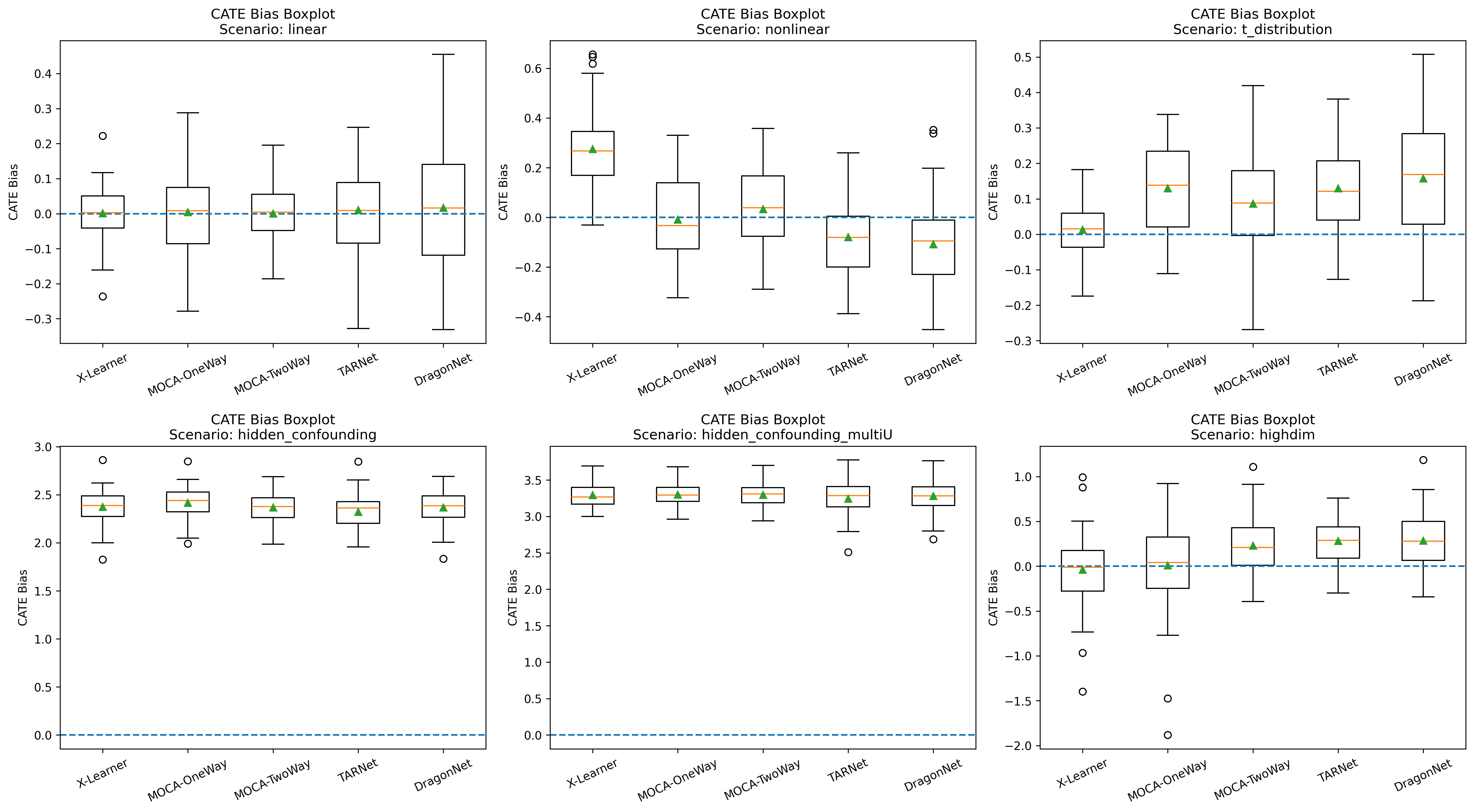
Figure 6: CATE bias boxplot for test sample size 1000 illustrating scalability and comparative bias control across approaches.
Real Data Benchmarks
Two real-world datasets are evaluated: IHDP (Infant Health and Development Program) and Dehejia–Wahba (DW, Lalonde subset). MOCA leverages Rubin-style variance pooling to estimate uncertainty, facilitating comparison with classical and machine learning methods. On IHDP, MOCA achieves the smallest ATE bias (0.006) and point estimate (3.991, 95% CI: 3.69–4.29). In DW, MOCA’s ATE estimate aligns closest to the AIPW benchmark. These results validate MOCA’s robustness and utility in practical settings.
Implications, Limitations, and Future Directions
MOCA’s modular transformer architecture effectively combines representational flexibility of modern neural models with strict adherence to causal inference methodological requirements. By preventing reverse information flow via feedback cutting and enforcing explicit modularity, MOCA aims to preserve the independence of propensity modeling and enhance interpretability. Empirical results suggest clear advantages in complex, nonlinear, high-dimensional settings and improved robustness under confounding and sample imbalance.
MOCA’s computational demands exceed those of classical methods (IPW, AIPW), and hyperparameter sensitivity—especially in transformer-based components—poses practical challenges in model tuning and stability. The modular design’s effectiveness hinges upon correctness of the treatment module; hard feedback cutting, though beneficial, may be overly restrictive for some applications. The framework remains fundamentally dependent on standard identification assumptions (consistency, ignorability, positivity) and cannot fully address hidden confounding in the absence of observability.
Future work should explore hybrid modularization architectures, sensitivity analysis integration, and proxy-variable strategies to further mitigate information contamination and address unidentifiable settings. MOCA’s principles may be extended to time-varying treatments and more general causal tasks in tabular and sequential domains.
Conclusion
MOCA introduces a principled, modular transformer-based causal modeling framework that enforces directional information flow and gradient feedback cutting between treatment and outcome modules. By combining the strengths of attention-based architectures with causality-aware modularization, MOCA achieves effective confounder adjustment, robust treatment effect estimation, and improved interpretability in challenging observational settings. Empirical evidence from simulation and real data demonstrates superiority or competitiveness relative to classical and contemporary machine learning methods, particularly under complexity, nonlinearity, and sample imbalance. The modular causality paradigm represented by MOCA signals a significant methodological advance for deep causal inference and warrants further exploration in both theoretical and applied research.