- The paper demonstrates that decoder-only transformers inherently learn lagged causal structures through gradient-based attribution during autoregressive prediction.
- It leverages Layer-wise Relevance Propagation to extract robust population-level sensitivities, yielding scalable and high-fidelity causal graphs.
- Empirical analyses show that transformers maintain precision across noise, non-stationarity, and nonlinear dynamics, outperforming classical Granger causality methods.
Theoretical Foundations
The paper establishes that decoder-only transformers, when trained autoregressively for next-step prediction in multivariate time series, naturally encode lagged causal structures in their learned representations. Crucially, under standard identifiability assumptions (conditional exogeneity, no instantaneous effects, lag-window coverage, faithfulness), the causal graph governing temporal dependencies can be directly recovered via the gradient sensitivities of the transformer's outputs with respect to past inputs. Formally, causal links j→ℓi exist if the score gradient energy Hj,iℓ=E[(∂xj,t−ℓlogp(Xi,t∣X<t))2] is positive.
Compared to classical Granger causality, this criterion operates on the full conditional distribution, not only the mean, providing higher fidelity for nonlinear and non-Gaussian dynamics. Notably, any model that fits the relevant conditional distributions is suitable for this approach; the paper advances decoder-only transformers as the architecture of choice due to scalability and alignment with contemporary deep learning practice.
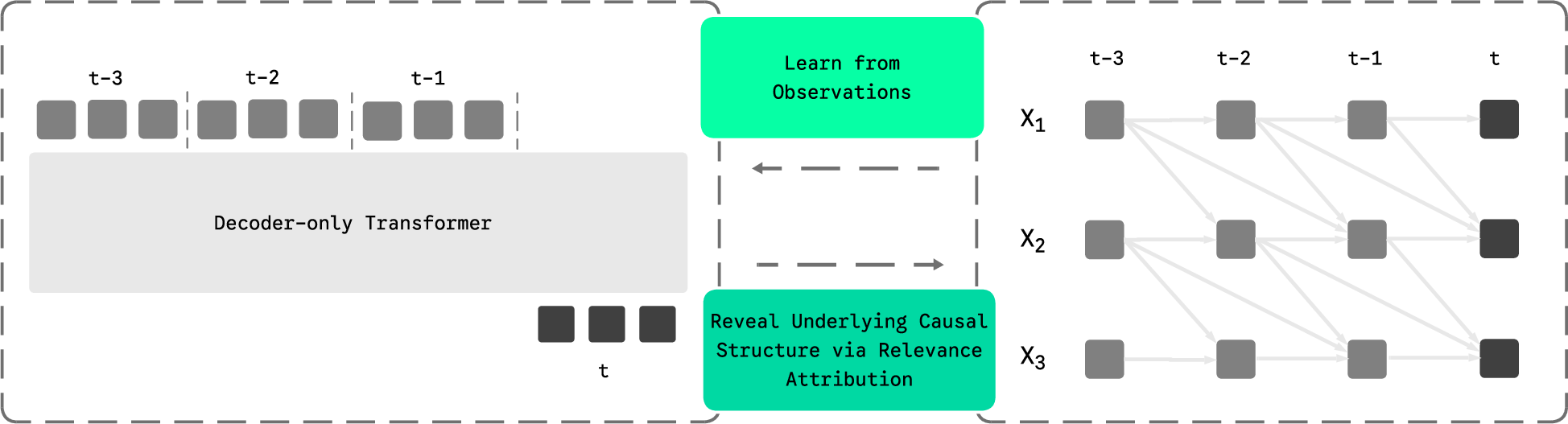
Figure 1: The autoregressive transformer connects lagged tokens to targets, modeling temporal generative processes and allowing for causal attribution via relevance scores.
Rather than relying on raw attention weights—which are confounded and non-faithful in deep transformer stacks due to token mixing—the procedure uses Layer-wise Relevance Propagation (LRP) to compute gradient-based attributions. For each output variable and lagged input, relevance scores are aggregated across the dataset to estimate population-level sensitivities, which are then binarized using top-k or uniform-threshold selection rules to yield the inferred causal graph.
This operationalizes the link between forecasting and structure discovery, turning the standard next-step prediction objective into a scalable estimator for temporal causal graphs within data-rich, nonlinear, and high-dimensional domains. The paper theoretically proves identifiability, derives explicit forms for various noise models (notably homoscedastic Gaussian), and connects practical LRP implementations to these theoretical results.
Empirical Analysis: Robustness and Scaling
Extensive simulation experiments demonstrate that transformer-based causal discovery is robust and exceptionally competitive across a spectrum of regimes:
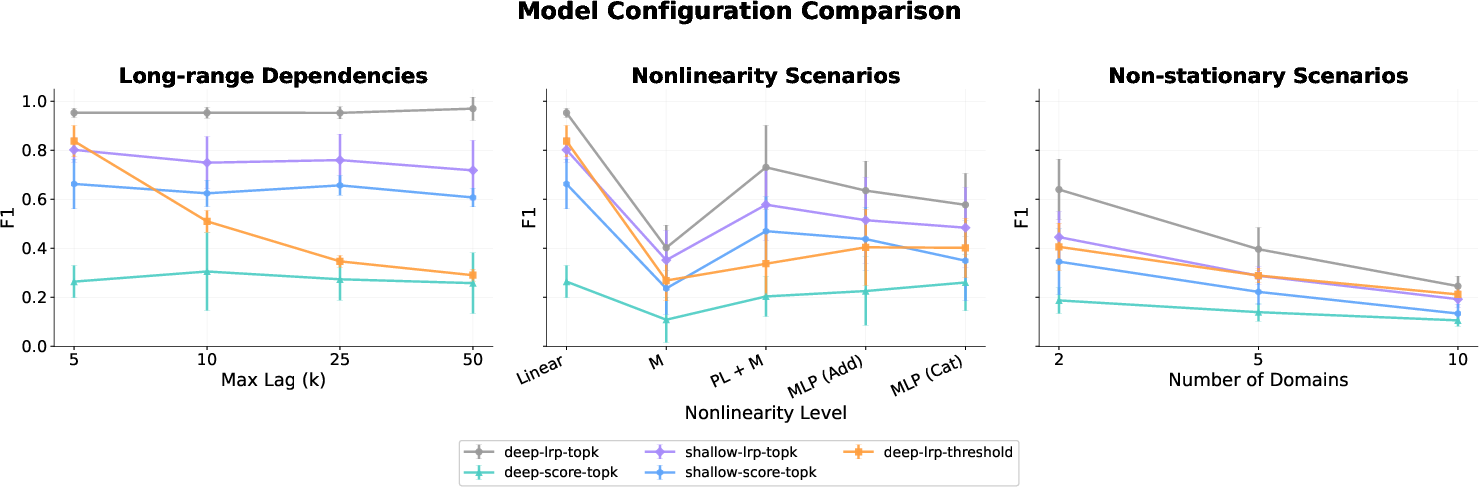
- High dimensionality: Transformers maintain precision and recall as the number of variables or maximum lag increases, outperforming constraint- and score-based baselines which degrade with dimensionality.
- Nonlinear dynamics: Accuracy steadily improves with sample size. Transformers outperform traditional methods as functional complexity grows, especially for non-additive or complex nonlinear structures.
- Non-stationarity: The approach scales favorably as data heterogeneity (number of domains) increases, in contrast to classical algorithms that struggle to separate shifting regimes.
- Noise heterogeneity: Transformer performance is invariant to noise type and variance, while baselines show pronounced degradation under heteroscedasticity.

Figure 2: Mean F1 score analysis across experimental regimes, quantifying transformer robustness to high dimensionality and data complexity.
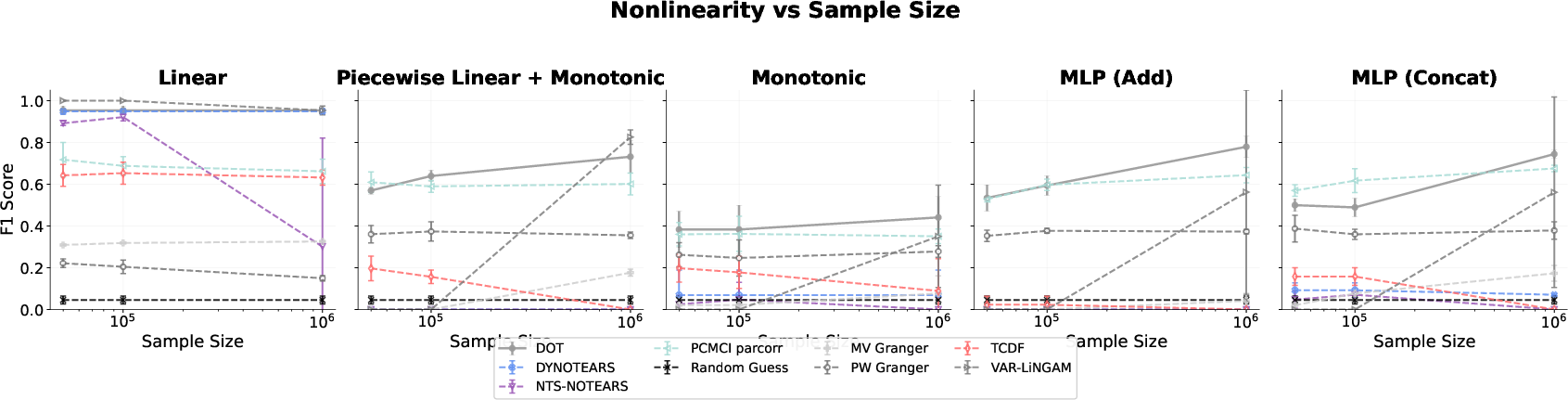
Figure 3: F1 scores under nonlinear dependency structures, illustrating superior scaling with sample size for transformers.
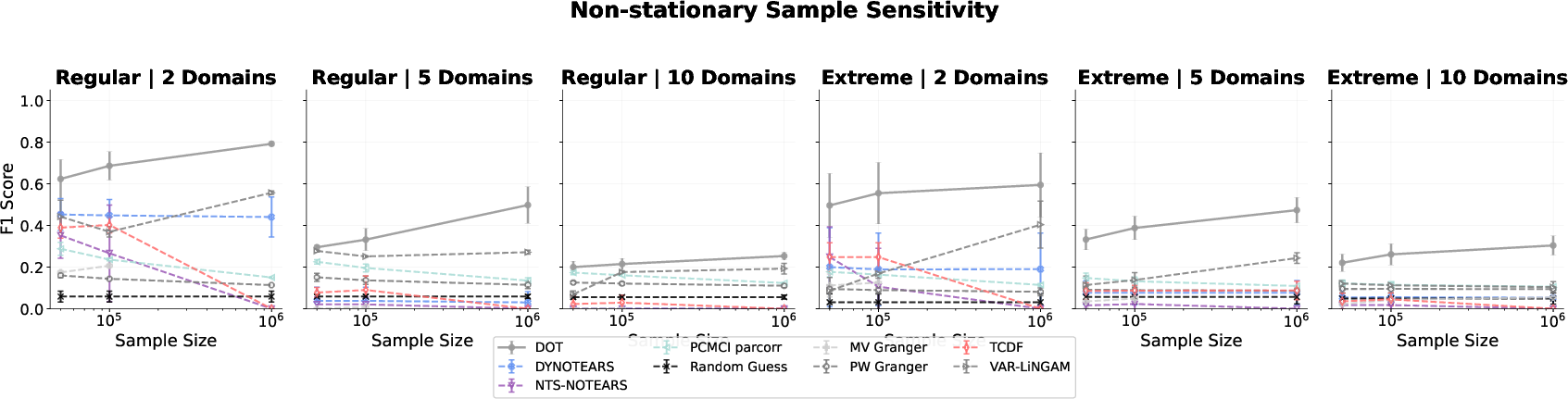
Figure 4: F1 scores in non-stationary environments, showing improved accuracy with increasing sample size and number of domains.
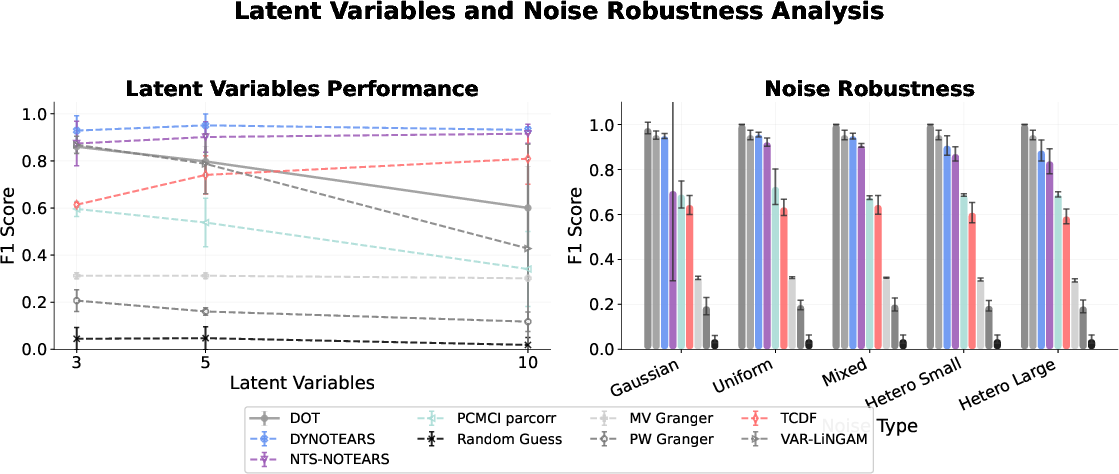
Figure 5: Robustness of transformer causal inference to latent variable prevalence and noise type.
Addressing Latent Confounding and Instantaneous Effects
The native architecture does not explicitly model latent confounders or contemporaneous relationships, leading to spurious edges under assumption violations. However, integrating domain knowledge, post-processing with latent-aware methods (e.g., L-PCMCI), or combining transformer-inferred lagged structures with traditional causal discovery dramatically improves robustness and accuracy.
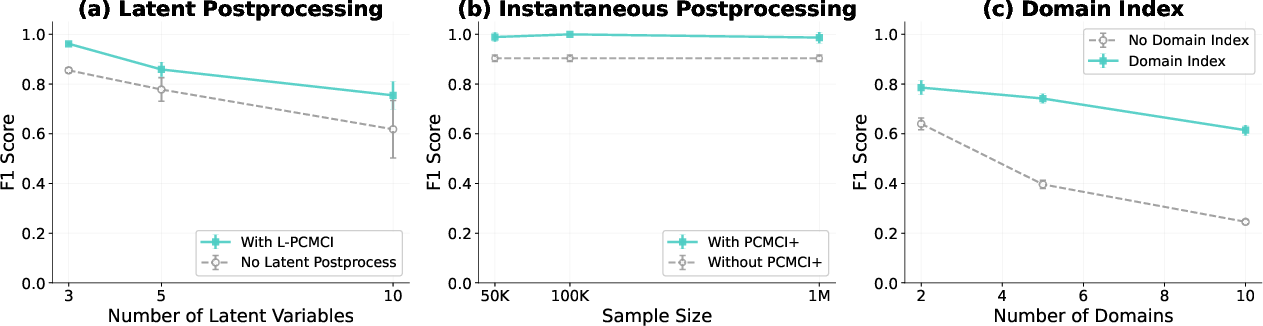
Figure 6: Postprocessing and domain indicator integration to optimize causal graph recovery under latent confounding and regime shift.
Experiments dissect the effects of architecture choices:
Uncertainty Quantification and Model Selection
Aggregation of per-sample relevance scores and rank-based metrics enables uncertainty quantification, facilitating confidence estimates for inferred edges. This approach can prioritize edges for further analysis or application in domains where false positive rates must be tightly controlled.
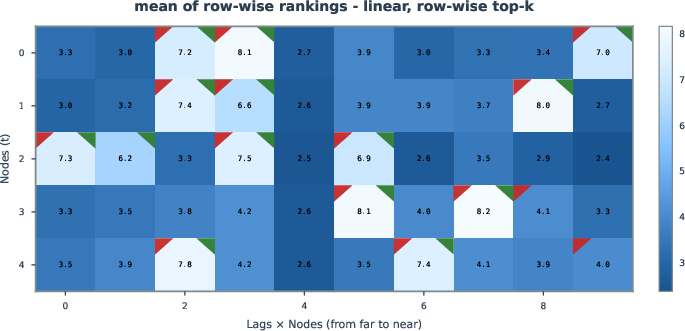
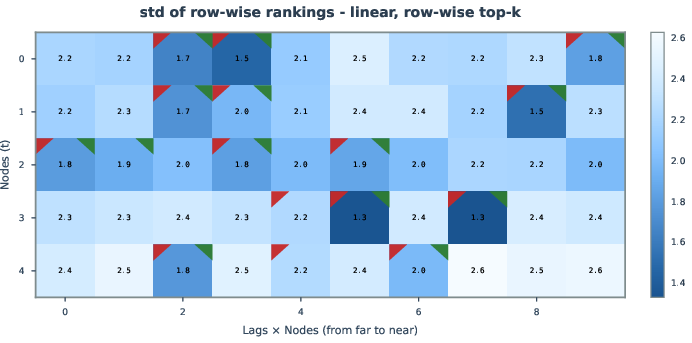
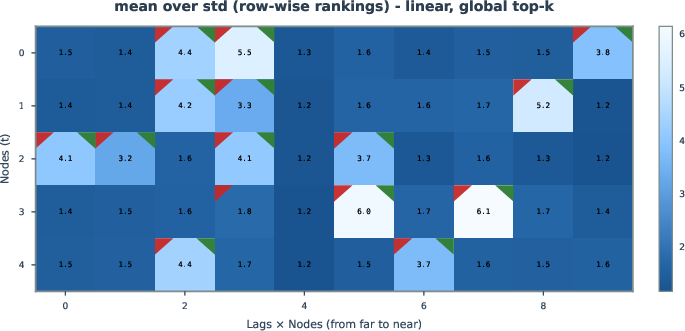
Figure 8: Uncertainty analysis via mean and variance of edge relevance rank, surfacing high-confidence causal edges.
Implications and Future Directions
This work posits a unifying paradigm for causality in sequence modeling: large foundation models are inherently causal learners when equipped with gradient-based attribution. This reframes causal discovery as a secondary effect of scalable representation learning, with implications for zero-shot adaptation, data efficiency, cross-modal transfer, and interpretability in foundation models. The underlying theory motivates future model developments—such as native integration of structural priors, latent variable handling, and environment-invariant mechanism modeling—potentially leading to universal causal structure learning across scientific and industrial domains.
Conclusion
The paper rigorously demonstrates that decoder-only transformers trained for autoregressive prediction can recover temporal causal graphs via gradient-based relevance attributions, under modest and standard identifiability assumptions. Empirical results highlight strong accuracy, robustness, and scalability that surpass classical causal discovery algorithms, particularly in data-rich, complex, and heterogeneous regimes. This elevates the transformer architecture as an interpretable and robust causal learner, suggesting that the next generation of foundation models may unify forecasting and structure discovery, achieving generalizable mechanism-level understanding and diagnostic capability for real-world systems (2601.05647).