- The paper presents a hybrid model that integrates three domain-specialized priors and fuses their knowledge via augmented distillation, enabling real-time, photorealistic portrait relighting.
- It achieves superior visual results with the lowest MSE, highest PSNR and SSIM, and flexible deployment across devices while preserving subject identity.
- The methodology significantly cuts computational costs, offering up to 240× speedups and bridging the gap between synthetic and real-world data.
Hybrid Domain Knowledge Fusion for Portrait Relighting
Portrait relighting requires producing physically-plausible renderings under arbitrary HDR environment maps, with strong constraints on visual fidelity, identity preservation, and inference latency. Existing works tend to optimize individually for photorealistic synthesis (e.g., diffusion-based generative models), physical accuracy (physically-based rendering), or efficiency, but real-world adoption is circumscribed by domain gaps (synthetic vs. real-world data), camera robustness, and computational cost. Diffusion models excel at synthesizing details but exhibit stochasticity-induced identity drift and temporal instability, precluding real-time applications. Conversely, explicit reflectance-model-driven networks preserve identity and photometric linearity but degrade on in-the-wild data and remain computationally expensive.
This work proposes Hybrid Domain Knowledge Fusion, a bifurcated paradigm involving (1) the training of three domain-specialized prior models mastering synthetic, OLAT, and real-world distributions, and (2) augmented knowledge distillation to fuse their expertise via a compact, single student model, robustly deploying across diverse cameras and environments in real time.

Figure 1: Real-time portrait and video relighting under arbitrary HDR environments, preserving subject identity and illumination fidelity across camera types, with temporally-stable outputs.
Methodology and Architecture
Specialized Prior Model Training
Three prior models are engineered:
- Physics Prior (Pphys): Trained on extensive synthetic data, targeting the accurate extraction of surface normal and albedo under physical light transport and rich intrinsic labels.
- Reflectance Prior (Prefl): Supervised on synthetic and OLAT data, with augmentations (glare, noise, motion blur) imitating real camera artifacts and simulating subsurface scattering and specularity.
- Realism Prior (Preal): Fine-tuned on real-world data (unlabelled), focusing on device variations, identity diversity, and environmental noise.
Domain adaptation is addressed by radiance-based augmentations, albedo consistency losses (decoupling intrinsic reflectance from illumination), and domain-aware 2D layer normalization to stabilize feature statistics across source domains.
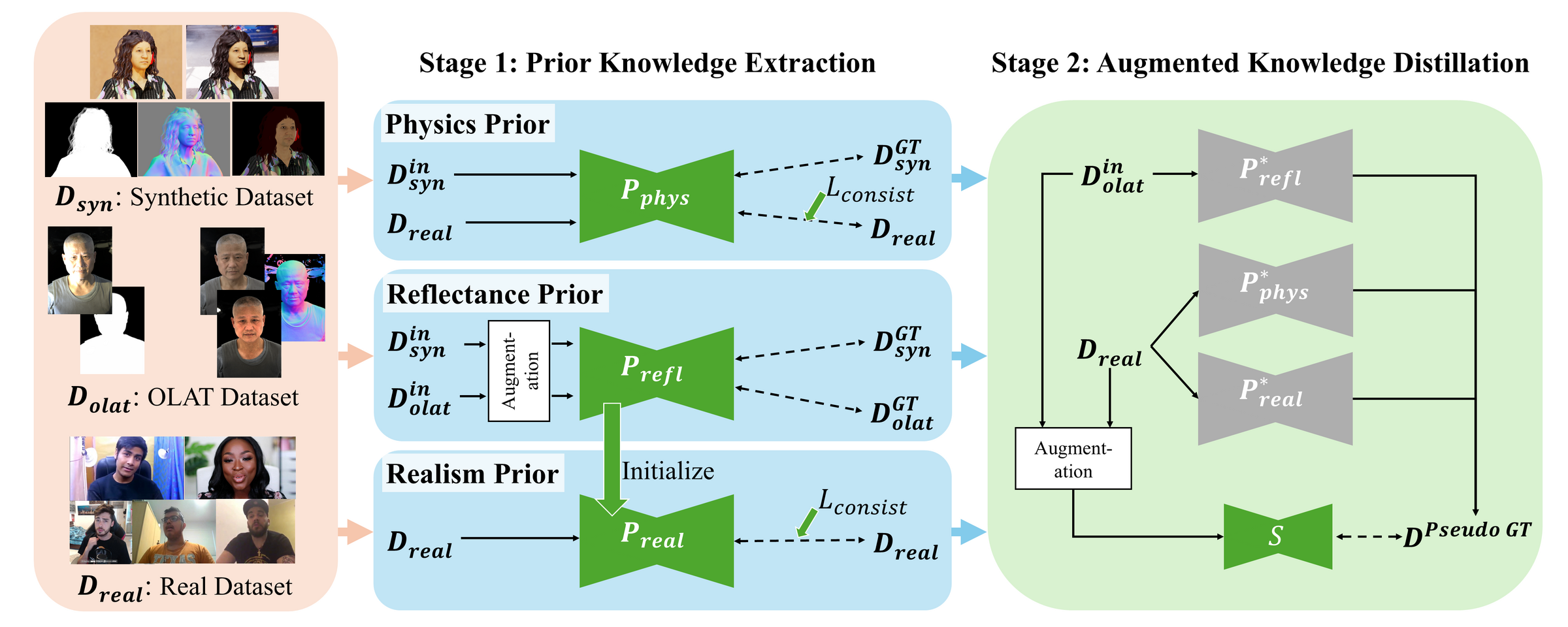
Figure 2: Staged overview of Hybrid Domain Knowledge Fusion: specialized priors trained and adapted on heterogeneous domains, followed by fused knowledge distillation in a compact student.
Augmented Knowledge Distillation
Domain-routed pseudo-ground truths are generated by each prior, supervised to the student network, with asymmetric augmentation (only student input degraded) enforcing robustness beyond teacher capacity. Architectural compression (channel reduction, resolution stratification) and hardware-favorable normalization (BN where applicable) enable a 6×–240× inference speedup versus existing pipelines.
Synthetic Dataset Construction
A large-scale (640k+ samples) synthetic dataset is constructed leveraging NVIDIA Omniverse and Digital Human Technology, with explicit intrinsic supervision (surface normals, albedos, pixel-aligned RGB), demographic diversity (800 avatars), realistic grooming, attire, pose, and illumination (over 2100 HDRIs). Supplementary OLAT datasets (320 subjects) and curated real-world captures (650k sequences, multiple camera profiles) provide heterogeneity and cross-domain coverage.

Figure 3: Synthetic data samples: paired images under different HDRI, diffuse albedo map, and normal map with procedural identity and illumination diversity.
Experimental Results
Visual Quality
On the OLAT benchmark, the proposed method demonstrates lowest MSE (0.037), highest PSNR (14.75), and highest SSIM (0.77), surpassing SwitchLight v3 and diffusion-based methods both structurally and perceptually (see Table 1 in paper). Remarkably, the model maintains competitive LPIPS despite strong structural fidelity.

Figure 4: Qualitative comparison on OLAT test set: method output matches ground truth brightness, directionality, and skin tone, outperforming competitors in visual fidelity.

Figure 5: Portraits captured on varied devices relit under the same HDR environment: method preserves skin tone and identity, mitigates specularity and synthetic artifacts seen in baselines.
Inference Latency
The distilled student model executes at 4.7 ms/frame on an RTX 3080 (212.76 fps), comfortably exceeding real-time requirements even on RTX 2060. Measured speedups relative to prior works range from 6× (NVPR) to 240× (SwitchLight v3 RTX 4090), delivering both scalability and hardware accessibility.
Ablation Studies
Domain adaptation augmentations, albedo consistency, and domain-aware normalization are all essential: their removal introduces artifacts (hallucinated glare, ambient light leak, degraded contrast). Multi-teacher distillation and asymmetric augmentation materially improve robustness and identity preservation.

Figure 6: Ablation of prior model components: physical augmentations prevent glare hallucination, albedo consistency averts ambient leakage, domain normalization upholds textural realism.

Figure 7: Ablation of distillation components: asymmetric augmentation enhances illumination disentanglement; multi-teacher fusion preserves subject identity.
Implications and Future Directions
Hybrid Domain Knowledge Fusion achieves not only SOTA visual quality and real-time latency but also deployment-critical robustness to real-world camera artifacts and environmental diversity. Theoretically, it demonstrates that domain gap can be systematically bridged by modular prior training and knowledge fusion—rather than singular network extrapolation—when coupled with targeted augmentations and normalization. Practically, it enables interactive telepresence, live streaming, and professional media production with temporally-consistent portrait relighting at scale.
Future developments may explore further modularity in fusion, more granular teacher selection (per-pixel domain routing), self-supervised adaptation for unseen sensor profiles, or joint text-conditioned relighting for multimodal editing. The dataset construction approach also sets a precedent for procedurally-biased, large-scale synthetic data in other photometric vision tasks.
Conclusion
This paper presents a comprehensive solution to the practical adoption barriers of portrait relighting—domain gap, device robustness, and computational efficiency—via Hybrid Domain Knowledge Fusion. The paradigm involves explicit domain-specialized model training, cross-domain adaptation, and efficient distillation, resulting in a compact, hardware-efficient model achieving SOTA fidelity and unprecedented latency improvement. This methodology provides a blueprint for robust, real-time neural rendering across heterogeneous real-world environments and devices (2604.23094).