- The paper introduces a novel framework that leverages generative priors and a large OLAT dataset to achieve 3D-consistent relighting from a single image.
- The methodology integrates EG3D inversion with a reflectance network to synthesize accurate OLAT images, preserving high-frequency details and identity.
- Quantitative evaluations demonstrate state-of-the-art SSIM, LPIPS, and PSNR metrics, outperforming previous methods in relighting fidelity and novel view synthesis.
3DPR: Single Image 3D Portrait Relighting with Generative Priors
Introduction and Motivation
The 3DPR framework addresses the highly underconstrained problem of rendering photorealistic, relit, and 3D-consistent views of human heads from a single monocular portrait image. Traditional graphics pipelines rely on explicit decomposition of geometry, material, and lighting, but these approaches are limited by model assumptions and parameterization constraints. Recent data-driven methods have improved generalization and photorealism, but most either require multi-view input, subject-specific training, or suffer from poor generalization to in-the-wild images. 3DPR overcomes these limitations by leveraging generative priors from EG3D and a novel, large-scale OLAT dataset (FaceOLAT), enabling physically accurate relighting and novel view synthesis from a single image.
FaceOLAT Dataset: Scale, Diversity, and Utility
3DPR is enabled by FaceOLAT, a large-scale, multi-view, high-resolution OLAT dataset comprising 139 subjects, each captured from 40 viewpoints under 331 point light sources at 4K resolution. The dataset includes diverse demographics, multiple facial expressions, and comprehensive coverage of hair and skin reflectance.

Figure 1: Overview of the FaceOLAT dataset, showing multi-view, high-resolution OLAT captures across diverse subjects and lighting conditions.
FaceOLAT's scale and diversity surpass all prior public datasets, supporting robust learning of high-frequency reflectance priors and generalization to unseen identities. The data acquisition pipeline incorporates optical flow-based alignment (RAFT), background matting (BGMv2, RMBGv2), and multi-view calibration (Agisoft Metashape), ensuring high-fidelity ground truth for supervised learning.
Methodology: Generative Priors and OLAT-Based Reflectance Modeling
EG3D Latent Embedding and Triplane Features
Given a monocular input image, 3DPR first embeds the portrait into the latent space of EG3D via encoder-based GAN inversion (GOAE). This produces tri-planar features Fg encoding geometry and appearance, which are rendered volumetrically from arbitrary viewpoints.
Reflectance Network and OLAT Synthesis
The core innovation is the reflectance network, which concatenates Fg with a target light direction and passes the result through a ResNet-based OLAT encoder to produce reflectance-aware triplane features Fo. These are decoded (MLP) with view direction to synthesize low-res OLAT images and high-frequency reflectance features. To prevent overfitting and ensure identity preservation, a feature fusion module combines high-frequency identity features from EG3D with reflectance features before super-resolution.
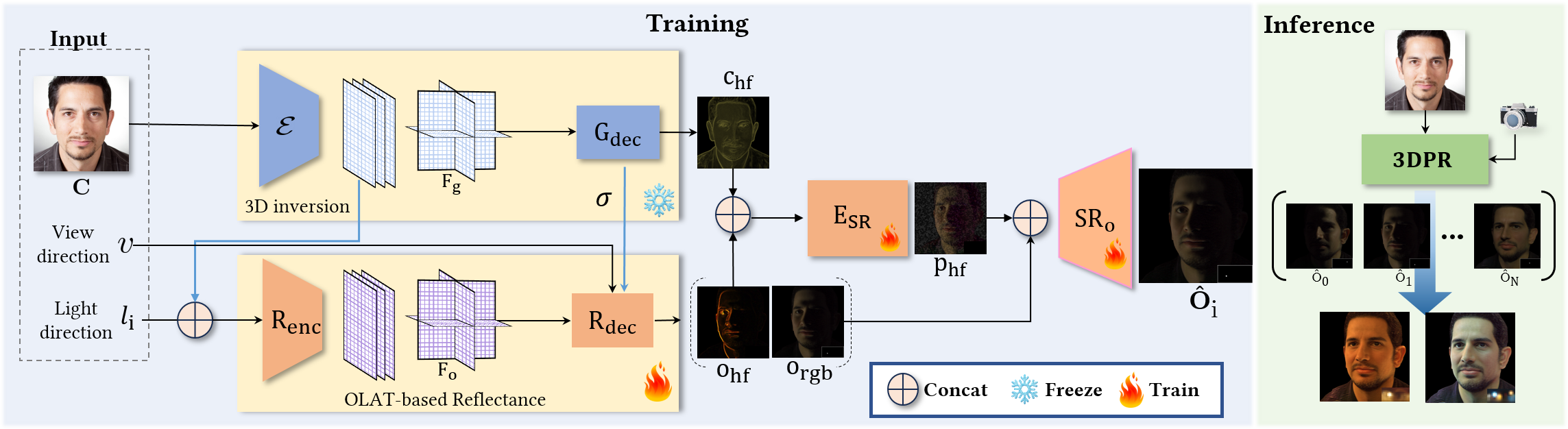
Figure 2: 3DPR pipeline: input image is embedded in EG3D latent space, reflectance features are synthesized for arbitrary light/view directions, and OLATs are linearly combined for relighting.
Physically Accurate Relighting via OLAT Additivity
At inference, 3DPR synthesizes OLAT images for any viewpoint and light direction, then linearly combines them according to a target HDRI environment map, leveraging the additivity of light transport for physically accurate relighting.
Loss Functions and Training Protocol
Supervision is provided by L1 reconstruction loss and ID-MRF loss (patch-wise nearest-neighbor in VGG19 feature space), which together recover high-frequency details and local structure. Adversarial losses are avoided due to limited subject diversity. The total loss is L=O+0.3⋅MRF.
Training is performed on 4×H100 GPUs, batch size 8, Adam optimizer, with a warm-up phase for the reflectance modules followed by joint training. The pipeline is fully parallelizable, supporting scalable OLAT synthesis.
Results: Quantitative and Qualitative Evaluation
Simultaneous View Synthesis and Relighting
3DPR achieves state-of-the-art performance in both relighting accuracy and 3D-consistent novel view synthesis, outperforming baselines such as PhotoApp, VoRF, NeRFFaceLighting, and Lite2Relight on both WeyrichOLAT and FaceOLAT datasets.

Figure 3: Simultaneous view synthesis and relighting: 3DPR produces sharp specular highlights, self-shadows, and subsurface scattering under novel viewpoints and illumination.
Quantitative metrics (SSIM, LPIPS, RMSE, DISTS, PSNR, ID) show consistent improvements over all baselines. For example, on FaceOLAT, 3DPR achieves SSIM 0.83, LPIPS 0.1996, RMSE 0.1801, PSNR 21.02, and ID 0.943, outperforming Lite2Relight and NeRFFaceLighting.

Figure 4: Baseline comparisons: 3DPR preserves identity and relighting fidelity better than PhotoApp, VoRF, NFL, and L2R.
Robustness to Sparse and Colored Lighting
3DPR maintains relighting fidelity under sparse and colored lighting conditions, where baselines degrade due to out-of-distribution effects and poor disentanglement. The explicit OLAT-based reflectance modeling enables accurate reproduction of shadows, specularities, and subsurface scattering.

Figure 5: OLAT-based relighting: 3DPR is robust to sparse/colored lighting, preserving identity and high-frequency effects, unlike NFL and L2R.
OLAT Synthesis Quality
3DPR's OLAT renderings closely match ground truth, generalizing to in-the-wild subjects and capturing intricate details such as hard shadows and specular highlights.

Figure 6: OLAT evaluation: 3DPR predictions exhibit high accuracy and capture complex light-skin interactions across subjects.
Ablation Studies
Ablations demonstrate the necessity of the SR encoder for generalization, the superiority of ID-MRF loss over LPIPS, and the importance of sufficient triplane feature dimensionality for encoding high-frequency reflectance. Increasing the number of training subjects improves generalization, but even with few subjects, the EG3D prior enables reasonable performance.

Figure 7: Ablation on SR encoder: incorporating high-frequency identity features is critical for generalization and artifact suppression.
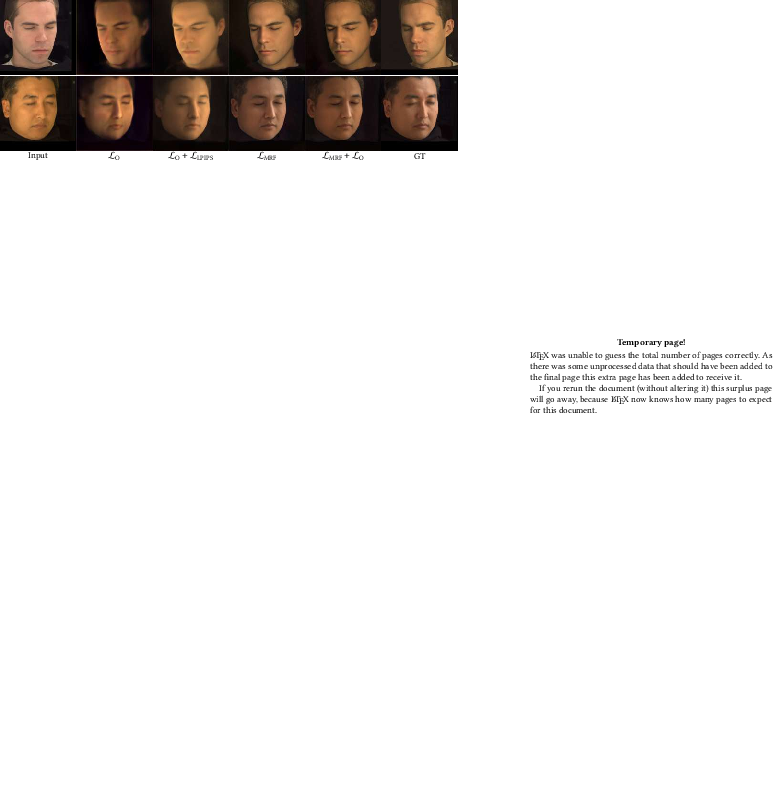
Figure 8: Ablation on loss functions: ID-MRF loss leads to significant improvements in relighting quality.
Limitations
3DPR's relighting quality degrades on the back of the head due to EG3D's limited coverage, and it does not model headgear or accessories. Hair modeling exhibits local inconsistencies under novel views, and view-dependent effects are relatively subdued. Addressing these limitations will require more comprehensive priors and improved supervision for view dependence and non-facial materials.
Implications and Future Directions
3DPR demonstrates that combining large-scale OLAT datasets with strong 3D generative priors enables physically accurate, generalizable, and efficient portrait relighting from monocular input. The explicit OLAT-based reflectance modeling provides fine-grained control over illumination, supporting applications in AR/VR, digital humans, and cinematic rendering. Future work should extend priors to full-head and non-facial materials, improve hair and accessory modeling, and explore integration with diffusion-based relighting for further generalization.
Conclusion
3DPR establishes a new standard for single-image 3D portrait relighting, achieving state-of-the-art fidelity, identity preservation, and 3D consistency. The release of FaceOLAT and the codebase will facilitate further research in generative relighting, reflectance modeling, and photorealistic rendering. The framework's modularity and scalability make it suitable for deployment in real-time and production environments, and its design principles are extensible to other object categories and modalities.