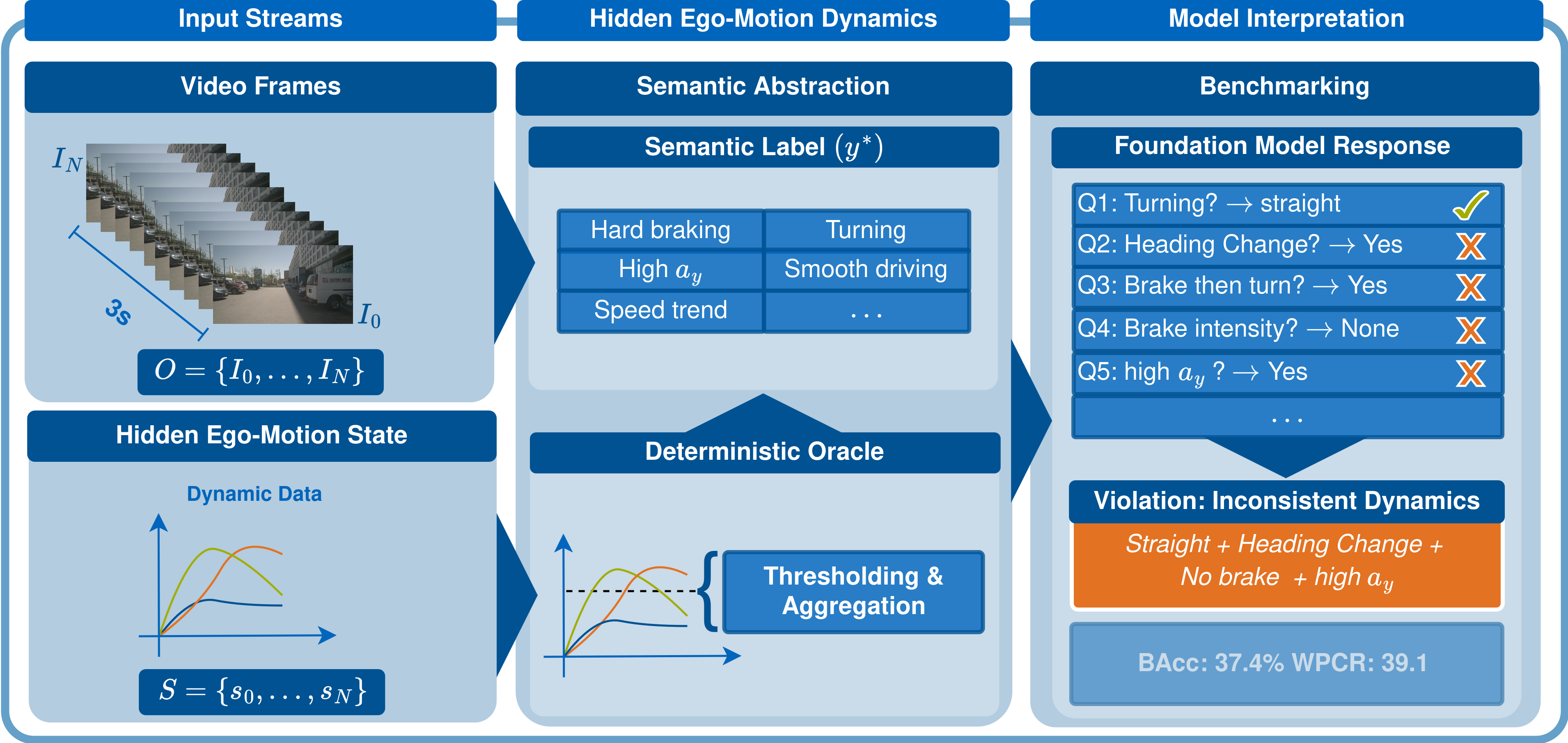
- The paper introduces EgoDyn-Bench, a diagnostic VideoQA benchmark to assess physically consistent ego-motion reasoning using deterministic kinematic oracles.
- The paper demonstrates that vision-only input underperforms compared to models supplemented with explicit trajectory encoding, exposing a perception bottleneck.
- The paper provides a robust evaluation framework with novel metrics like WPCR and temporal accuracy to guide future model improvements.
EgoDyn-Bench: A Diagnostic Benchmark for Ego-Motion Understanding in Vision-Centric Foundation Models
Introduction and Motivation
The transition from explicit, model-based representations of ego-motion in classical autonomous driving systems to vision-centric paradigms leveraging Vision-LLMs (VLMs) and Multimodal LLMs (MLLMs) raises critical issues regarding the physical consistency of high-level reasoning. While recent work has produced advances in semantic and planning tasks, there is a lack of standardized assessment of whether these models can extract physically correct ego-motion concepts directly from video data. This paper addresses the gap by introducing EgoDyn-Bench, the first diagnostic benchmark to explicitly evaluate ego-motion understanding—operationalized as physically grounded semantic reasoning within real-world and simulated driving sequences—across contemporary vision-centric foundation models.
Benchmark Design and Methodological Contributions
EgoDyn-Bench operationalizes ego-motion understanding as a semantic video question-answering (VideoQA) task. Given a sequence of visual observations and a natural language query related to vehicle dynamics, models are tasked to produce semantic responses aligned with physically derived ground truth. The key methodological features and provisions are:
Evaluation Metrics
EgoDyn-Bench introduces several evaluation metrics tailored for the diagnostic setting:
- Balanced Accuracy (BAcc) and Macro-F1: For semantic correctness, explicitly mitigating class-imbalance bias.
- Temporal Accuracy: For event ordering and comparative queries regarding dynamic changes.
- Weighted Physics Consistency Rate (WPCR): A Boolean logic-based metric evaluating whether model answers jointly satisfy physically valid kinematic constraints within each sequence (e.g., "if the model claims the vehicle turned, it must not state 'straight' in concurrent queries"). PCov reports constraint activation coverage.
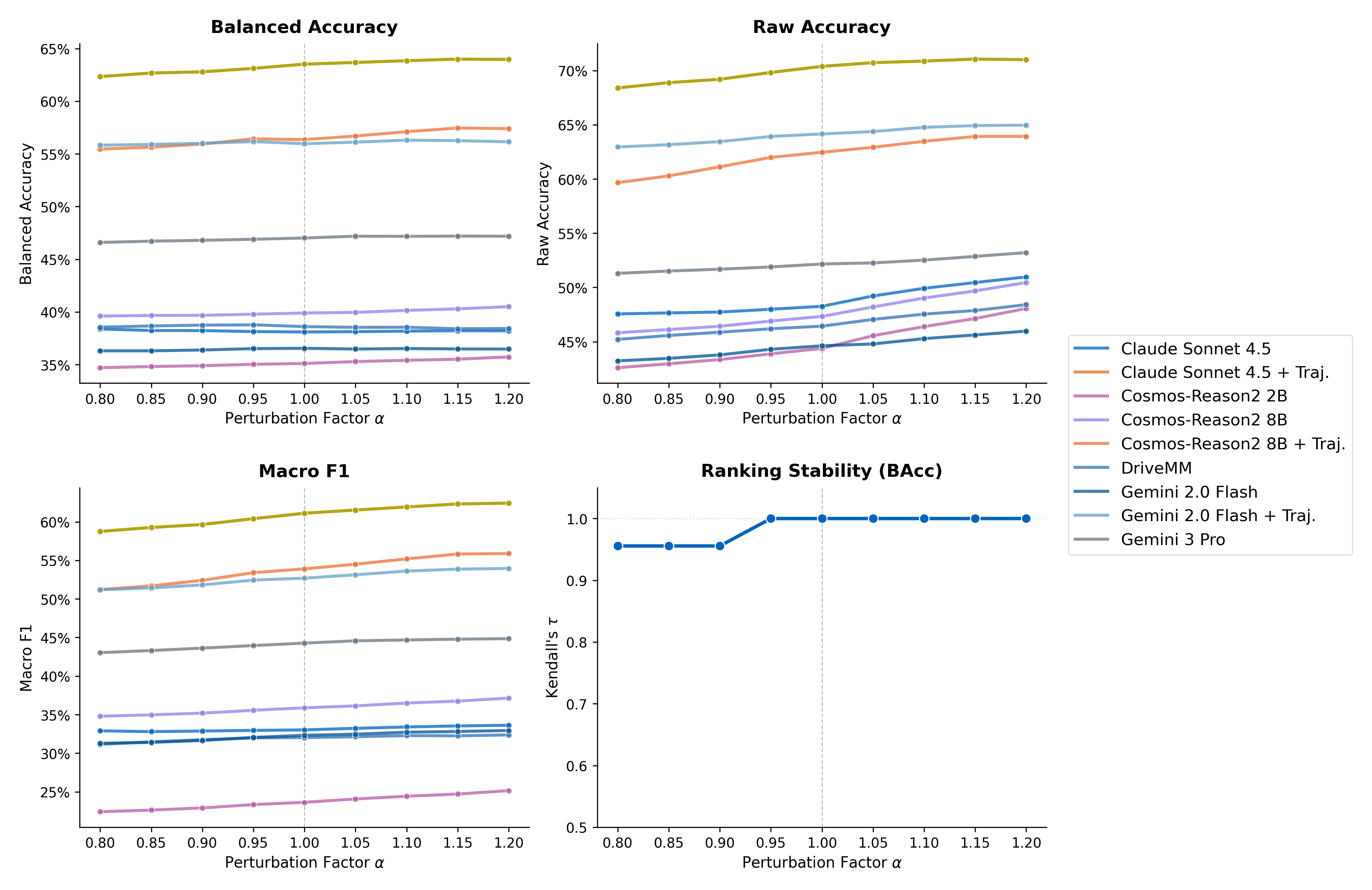
Figure 3: Model ranking stability under threshold perturbation; high Kendall τ demonstrates robustness of the “Perception Bottleneck” diagnosis.
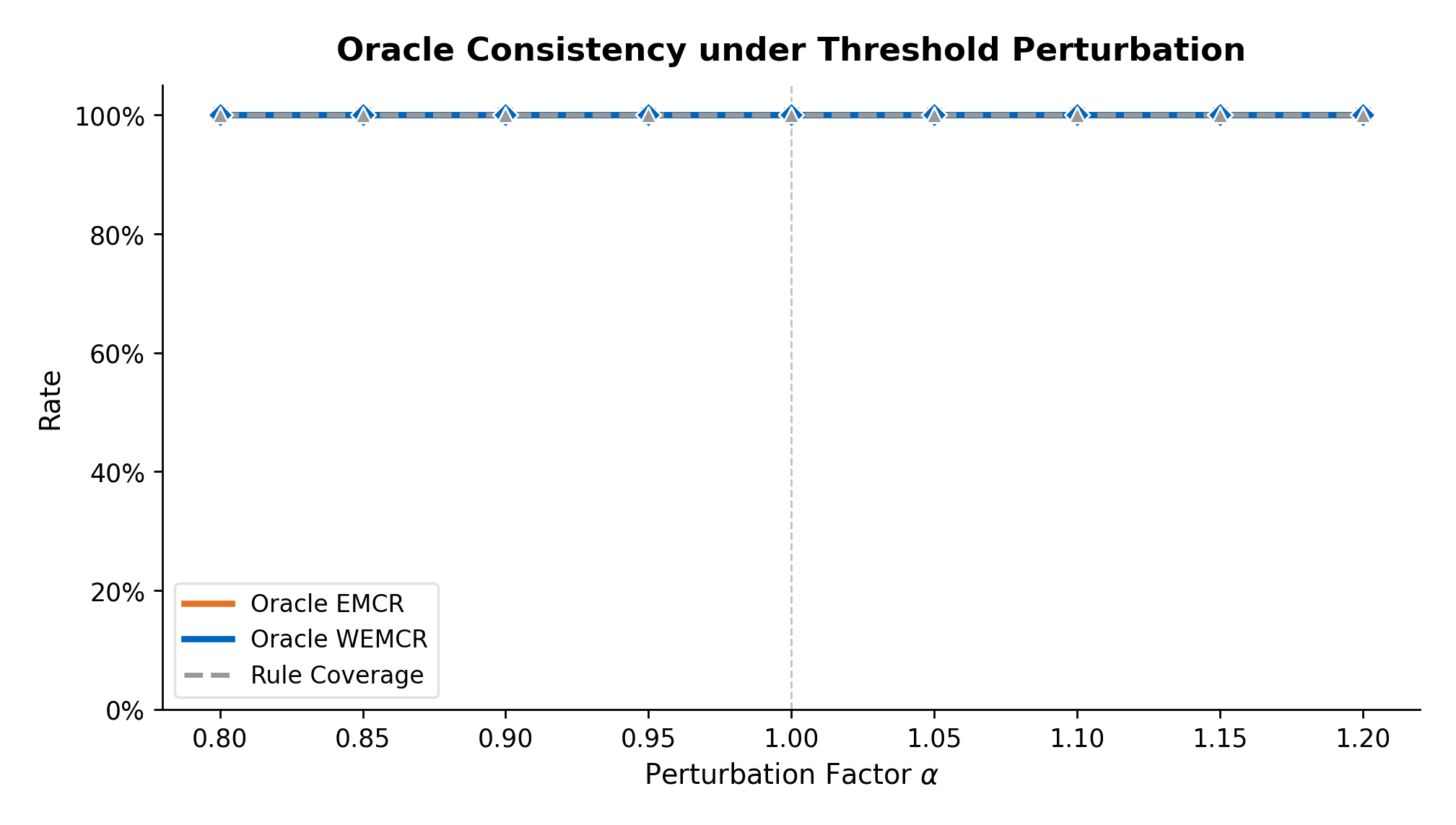
Figure 2: WPCR stability with threshold variation; Boolean implication-based physical consistency is invariant to threshold choice.
Empirical Results: Diagnosing the Perception Bottleneck
Through an extensive audit spanning closed- and open-source VLMs (including GPT-5.1, Gemini, Qwen-VL, InternVL, Cosmos-Reason, RoboTron-Drive, DriveMM, and more) as well as multiple classical and learned visual odometry/flow-based baselines, EgoDyn-Bench establishes several critical empirical findings:
- Across all VLMs and MLLMs, video-only input yields significant performance deficits in semantic ego-motion QA and physical consistency, with balanced accuracies often falling well below 50%. Notably, even the best large models lag behind classical geometric baselines (e.g., KLT-based visual odometry or learned models like TartanVO and RAFT flow).
- Scaling model size or incorporating in-domain fine-tuning yields marginal improvements, indicating a fundamental architectural limitation in capturing kinematic state transitions or integrating low-level motion cues from visual input alone.
Explicit Trajectory Encodings Recover Physical Reasoning
Robustness and Generalizability
- Sensitivity analysis with respect to semantic thresholding demonstrates that the relative ordering of models is robust (τ>0.9) to large parameter sweeps, showing that the architectural deficit diagnosed—the "Perception Bottleneck"—is not an artifact of benchmark calibration.
Interactive Infrastructure
- The benchmark is supplemented with a web-based human-in-the-loop clip viewer, providing synchronized video, kinematic plots, and QA metadata for model auditing, traceability, and further analysis.
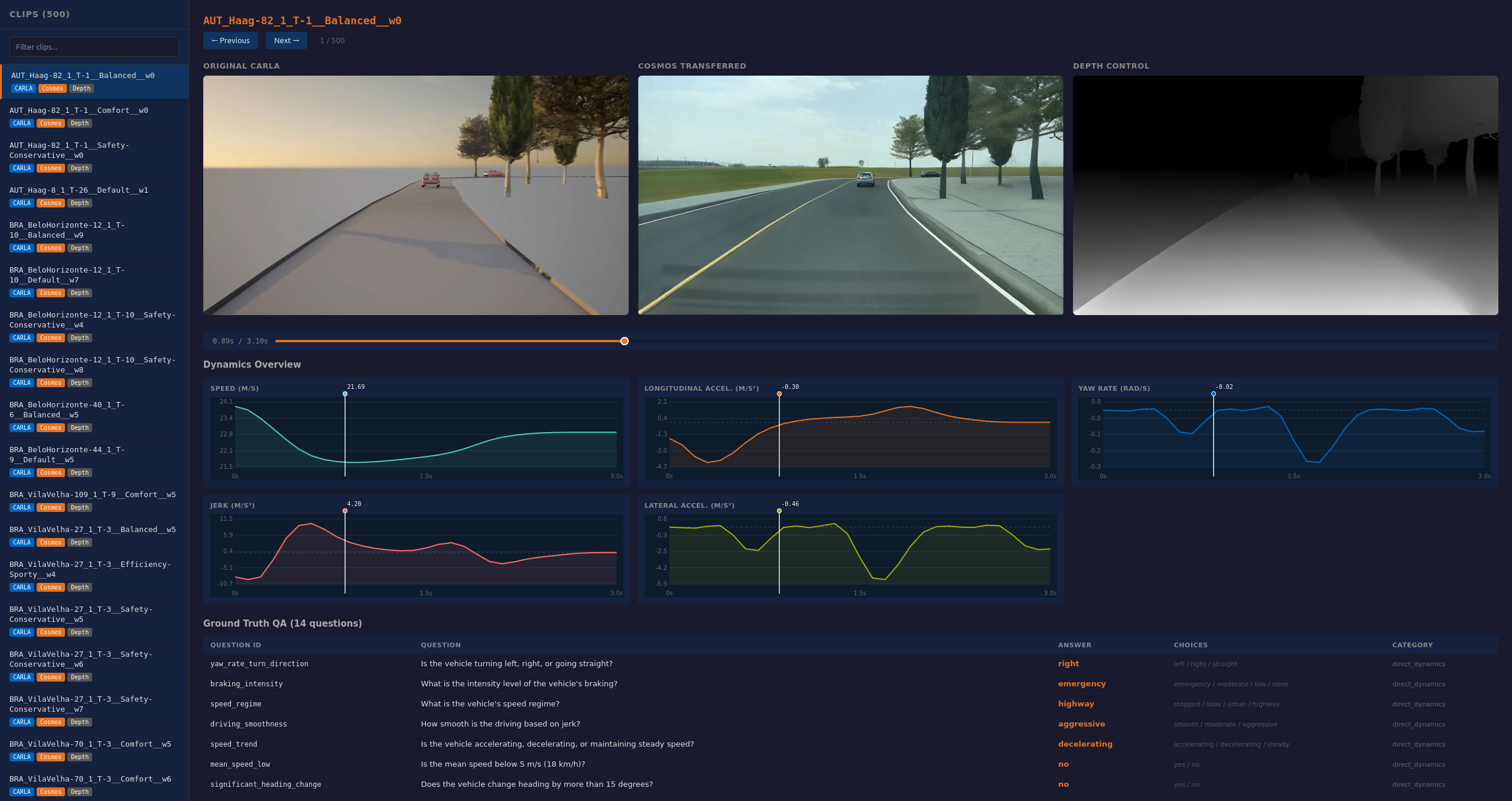
Figure 5: An interactive dashboard for synchronized inspection of video, kinematic signals, and QA pairs, supporting human verification of label and model prediction alignment.
Broader Implications and Outlook
The results expose a structural decoupling in current foundation model architectures: physically-valid ego-motion logic is represented almost exclusively within the language modality, not derived from or further anchored by vision. This architectural asymmetry results in downstream embodied AI systems that are susceptible to trivial errors, limited generalization, and potentially catastrophic physical reasoning failure, even as their high-level semantic and planning performance (on prior benchmarks) may appear strong.
For the research community, EgoDyn-Bench presents a necessary diagnostic axis for the development and validation of physical AI:
- Model Design: Diagnostics suggest that pre-training and fine-tuning paradigms for vision-centric models require explicit architectural or training-signal alignment between image sequences and dynamic kinematics, not just additional scale or language-driven instruction following.
- Evaluation and Benchmarking: Existing benchmarks that focus on downstream planning or high-level QA are inadequate to guarantee safety or robust physical consistency in embodied, closed-loop scenarios.
- Future Research Directions: There is a clear need for new pretext/auxiliary tasks, contrastive-learning frameworks, or cross-modal embedding structures that force deeper coupling of visual and physical reasoning streams, as well as further exploration into structured input representations (e.g., trajectory timeseries) and how these can be integrated during training to form robust, scalable motion priors.
Conclusion
EgoDyn-Bench establishes, with rigorous empirical support, that vision-centric foundation models for autonomous driving fundamentally fail to ground ego-motion understanding in visual perception. Existing architectures default to language priors and require explicit kinematic input for physically-consistent reasoning. Addressing the decoupling of vision and physical reasoning is the outstanding challenge for the field. The benchmark, dataset, codebase, and analysis tools provided are essential infrastructure for developing the next generation of physically aligned, embodied AI systems.
For in-depth experimental design, calibration rules, and additional ablations, consult the supplementary material as detailed in the paper ["EgoDyn-Bench: Evaluating Ego-Motion Understanding in Vision-Centric Foundation Models for Autonomous Driving" (2604.22851)].