- The paper introduces Dyn-Bench, a novel benchmark assessing MLLMs on object-level and region-level dynamic reasoning in 4D environments.
- It employs ST-TCM and mask-guided grounding to enhance spatio-temporal perception, yielding up to 5% absolute accuracy gains.
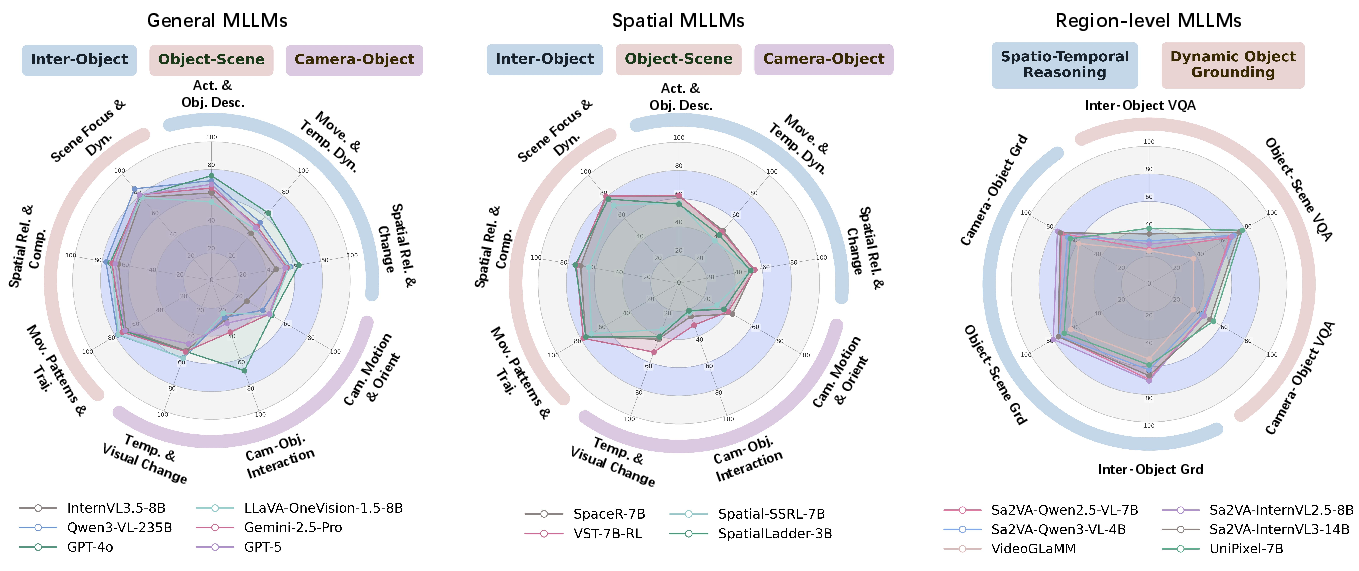
- Comparative evaluations reveal that region-level MLLMs excel in grounding tasks, while general MLLMs perform better in relational reasoning.
Thinking in Dynamics: Spatio-Temporal Reasoning and Grounding in MLLMs with Dyn-Bench
Introduction
"Thinking in Dynamics: How Multimodal LLMs Perceive, Track, and Reason Dynamics in Physical 4D World" (2603.12746) rigorously investigates the spatio-temporal reasoning capabilities of state-of-the-art Multimodal LLMs (MLLMs), with a focus on dynamic 4D environments. The authors introduce Dyn-Bench, a large-scale, hierarchical benchmark specifically designed to probe object-level and region-level motion understanding, temporal consistency, and relational reasoning in both real and synthetic dynamic scenes. This work provides an extensive evaluation of general, spatial, and region-level MLLMs, establishing, via systematic ablations and qualitative analysis, the limitations of current approaches and the efficacy of explicit spatial–temporal grounding techniques.
Dyn-Bench: Benchmark Design and Construction
Dyn-Bench targets the central research question: To what extent can MLLMs perceive, track, and reason about evolving spatio-temporal scenes at an object-centric and relation-centric level?
Benchmark Hierarchy and Metrics
The benchmark is structured into three axes of dynamic scene understanding:
- Dynamic Inter-Object Perception: Assessment of models’ capacity to perceive and reason about motion and spatial interactions between multiple moving objects.
- Dynamic Object–Scene Tracking: Evaluation of tracking object evolution and motion patterns relative to the surrounding scene.
- Dynamic Camera–Object Reasoning: Analysis of object behavior under varying camera dynamics, including viewpoint shifts and ego-motion.
Each dimension incorporates both visual question answering (VQA) and object grounding to jointly evaluate semantic reasoning and precise region localization. The benchmark samples 1,000 curated videos (from eight datasets), comprising 7,000 VQA pairs and 3,000 dynamic object grounding annotations (Figure 1).

Figure 1: Benchmark curation pipeline integrating dynamic video datasets, multimodal completion, and rigorous quality control to generate structured spatio-temporal reasoning and grounding pairs.
Curation and Quality Control
Dyn-Bench leverages a multi-stage pipeline integrating geometric and motion feature extraction, VLM-based quality scoring, and human vetting to ensure high-fidelity dynamic content. Instance masks, camera poses, and 3D depth are meticulously reconstructed. Importantly, region-level attributes are converted into structured textual forms using Spatio-Temporal Textual Cognitive Maps (ST-TCM), enabling both visual and linguistic evaluation modalities.
Evaluating State-of-the-Art MLLMs
Baseline Categories and Protocol
The evaluation encompasses:
- General MLLMs (e.g., GPT-4o, Gemini-2.5 Pro, Qwen3-VL): Broad-coverage LMMs without explicit spatial supervision.
- Spatial MLLMs (e.g., VST-7B-RL, SpaceR-7B): Models with geometry-aware modules but limited region-level grounding.
- Region-level MLLMs (e.g., UniPixel-7B, Sa2VA-based models): Architectures with explicit region–language alignment and dense mask integration.
Tasks are assessed in a zero-shot fashion with primary metrics including accuracy (ACC) for multi-choice VQA and $\mathcal{J %%%%0%%%% F}$ for segmentation-based object grounding.
Quantitative Results and Error Analysis
Model performance varies by category and task (Figure 2):
Common error modes include:
- Failure to maintain temporal event continuity, causing segmentation drift and inconsistent object identity (“temporal fragmentation”).
- Inadequate utilization of explicit motion or relational cues, resulting in shallow “frame-level” inferences rather than aggregative temporal perception.
- Insufficient spatial understanding for scenes with large ego-motion or object occlusion.
Enhancing Spatio-Temporal Reasoning: ST-TCM and Visual Guidance
Spatio-Temporal Textual Cognitive Map (ST-TCM)
ST-TCM unifies spatial (geometry), temporal (event ordering), and motion features into a symbolic–textual representation. Ablative studies demonstrate that enriching input with structured motion and spatial cues yields large gains up to 5% absolute accuracy for both general and region-level MLLMs. Notably, the articulation of motion and geometry is more impactful than temporal semantics alone.
Visual Mask-Guided Grounding
Providing models with mask-guided input (either overlaid masks or fused mask-caption features) substantially boosts dynamic object reasoning, especially in inter-object and ego-centric viewpoint tasks. Mask-guided fusion achieves a 3.3 point average improvement over baseline video input. Examples illustrate improved robustness in tracking persistently moving entities and localizing temporally-varying object extents (Figure 3).
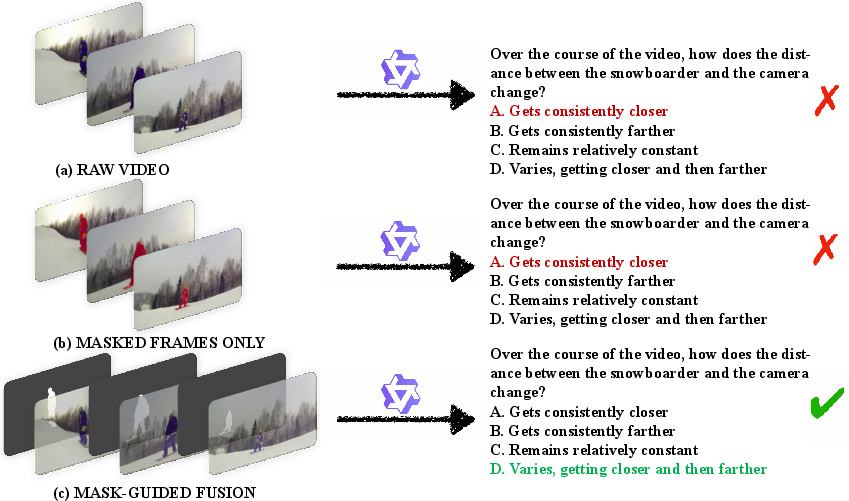
Figure 3: Mask-guided input vs. raw video input: integrating mask priors focuses model attention, strengthening spatio-temporal consistency.
Qualitative Analysis
Self-explanation studies reveal that MLLMs often default to surface-level cues unless guided; ST-TCM effectively compels deeper, physically coherent descriptions (Figure 4). Failure cases highlight linguistic fluency without physical grounding and reveal persistent challenges in scenarios with rapid motion, occlusion, or ambiguous reference frames.
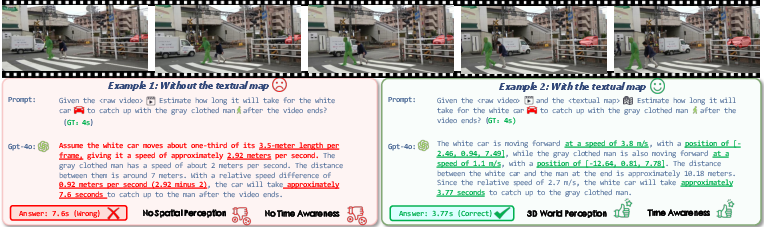
Figure 4: Example self-explanations show models’ strengths in language, but highlight limitations in modeling dynamic world state without explicit spatio-temporal structure.
Implications and Future Directions
The results indicate that current MLLMs—even at the largest parameter scales—exhibit disentangled spatial, motion, and linguistic representations, lacking the emergent coherence required for robust 4D dynamic understanding. Premature generalization from static or sparsely-annotated datasets underestimates the complexity of motion reasoning, relational event ordering, and region-level continuity.
The practical implication is that for applications in robotics, embodied AI, surveillance, or dynamic environment modeling, structured cognitive priors such as ST-TCM and region-level mask annotation remain essential. The benchmark exposes fundamental obstacles in cross-modal alignment and motion tracking that must be addressed for physically plausible 4D reasoning.
Anticipated future efforts should aim for joint architectures coupling region-level grounding modules, motion-affinity mechanisms, and structured textual abstraction layers, driving MLLMs toward coherent world modeling over continuous space and time.
Conclusion
This paper introduces Dyn-Bench, a comprehensive and challenging assessment suite for spatio-temporal and dynamic object-centric reasoning in MLLMs. Through systematic evaluation and analysis, it demonstrates the current limitations of even the most advanced MLLMs in physical 4D world modeling. Crucially, the study establishes the value of explicit region-level grounding and structured symbolic textual integration (ST-TCM) in bridging the gap between superficial temporal reasoning and genuine dynamic understanding, setting a concrete trajectory for the next generation of physically grounded multimodal intelligence.