- The paper introduces a Dual-Space Sparse Attention (DSSA) module combining MoBA and SSE layers to recover long-context ability with less than 5% performance loss.
- It integrates dual-path quantization with INT8-Spiking and FP8 paths to deliver high efficiency on both neuromorphic and GPU hardware while preserving accuracy.
- The efficient Transformer-to-Hybrid (T2H) pipeline minimizes migration cost and computational overhead, supporting robust scaling for LLM and VLM applications.
SpikingBrain2.0: A Hybrid Brain-Inspired Foundation Model for Efficient Long-Context and Cross-Platform Inference
Introduction and Motivation
SpikingBrain2.0 (SpB2.0) addresses the escalating computational bottlenecks in long-context large model inference and training by unifying brain-inspired sparsity, hybrid attention, and hardware-adaptive quantization. Conventional full-attention (FA) Transformers are fundamentally limited by quadratic complexity and memory scaling, precluding efficient inference or deployment in resource-constrained environments. SpB2.0 builds directly on prior work in spiking foundation models and hybrid attention, but overcomes the efficiency-capability trade-offs that have previously hindered practical adoption in both language-only and multimodal (vision-language) settings (2604.22575).
Architectural Innovations
SpB2.0 introduces a Dual-Space Sparse Attention (DSSA) module, a non-uniform 1:3 inter-layer hybrid that strategically integrates Mixture of Block Attention (MoBA) and Sparse State Expansion (SSE) layers (Figure 1), retaining a single FA layer at the output.
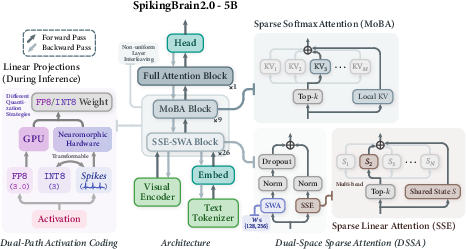
Figure 1: Architecture of SpikingBrain2.0-5B employing a 1:3 inter-layer hybrid (DSSA), dual-path activation coding, and hardware-agnostic quantization strategies for optimal performance across sequence lengths and platforms.
MoBA, as a sparse softmax attention variant, performs input-dependent block selection over the exact, uncompressed KV cache, supporting high-fidelity long-context recall but with less efficient memory scaling. In contrast, SSE, an advanced sparse linear attention mechanism, enables compressed, partitioned state updates with top-k gating, improving both sequence throughput and memory efficiency. Their combination is motivated by extensive sensitivity analysis (Figure 2) that reveals heterogeneous layerwise performance drops upon conversion from FA to LA/SSE; critical layers are therefore retained as MoBA, whereas the remainder are replaced by SSE with optional SWA auxiliary branches.
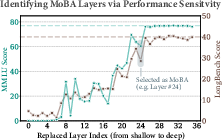
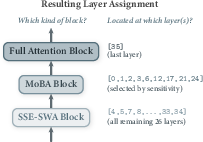
Figure 2: Layerwise sensitivity and resulting DSSA layer assignment in SpB2.0; layers selected for MoBA correspond to those where SSE replacement yields sharp performance drops on core benchmarks.
This architectural choice enables SpB2.0 to sidestep the severe recall and convergence limitations observed in prior LA- or SWA-dominant hybrids. Empirical evidence demonstrates that DSSA recovers nearly all of the source Transformer’s long-context capability, with negligible (<5%) drop on challenging benchmarks, while yielding order-of-magnitude improvements in memory and compute.
Quantization, Dual-Path Coding, and Hardware Adaptation
Beyond algorithmic sparsity, SpB2.0 introduces a dual-path quantization and activation-coding pipeline to maximize cross-platform inference efficiency. The INT8-Spiking path employs event-driven, sparse spike-sequence coding and integer matrix operations—enabling direct deployment on asynchronous neuromorphic architectures and mimicking energy-efficient biological neurons (Figure 3). Simultaneously, the FP8 path supports dense inference acceleration using Hopper Tensor Cores on commodity GPUs.
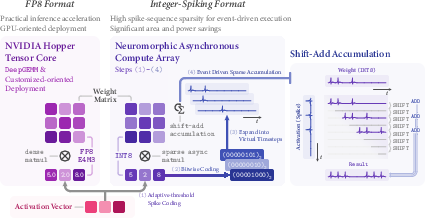
Figure 3: Dual quantization pathways: FP8 for accelerated inference on mainstream NVIDIA GPUs; INT8-Spiking for asynchronous, spike-driven computation on neuromorphic hardware.
Both quantization schemes are designed to strictly preserve accuracy: INT8-Spiking achieves just 0.69% absolute performance drop with 64.3% sparsity in spiking events, and FP8 operates at 0.24% performance drop but with 2.52× time-to-first-token (TTFT) inference speedup at 250k-length prompts. This level of lossless performance preservation under aggressive quantization is a significant contradictory result relative to prior work, where hardware-oriented quantization frequently degraded model quality on nontrivial tasks.
SpB2.0 demonstrates an efficient, scalable “Transformer-to-Hybrid” (T2H) conversion pipeline for both LLM and VLM models, enabling architectural migration through lightweight knowledge distillation, staged long-context continual pretraining, and multi-stage supervised fine-tuning (Figure 4).
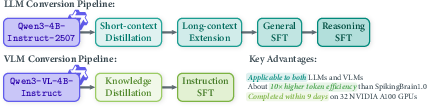
Figure 4: Dedicated T2H conversion pipelines for LLMs and VLMs; efficient migration ensures recovery of core capabilities under aggressive architectural shifts with minimal computational overhead.
The LLM pipeline proceeds via: (1) short-context distillation (3B tokens), (2) staged length expansion up to 512k (11B tokens), (3) general and reasoning-oriented SFT (~1M samples total), and (4) optional on-policy distillation (OPD). The total migration cost for SpB2.0-5B is under 7k A100 GPU hours, representing a fractional compute burden compared to typical full retraining. The VLM pipeline applies knowledge distillation from the original base Qwen3-VL followed by multimodal SFT and OCR-specific enhancements.
Key findings include: SFT-alone conversion is insufficient for capability recovery, CPT warm-up and progressive length expansion are essential for robust long-context generalization, and data quality during conversion critically impacts downstream performance.
Empirical Results and Numerical Findings
SpB2.0-5B, after 14B tokens of continued training, achieves >95% average performance recovery compared to the Qwen3-4B base on core LLM benchmarks including MMLU, ARC-C, GSM8K, HumanEval, and BBH. On long-context evaluations (RULER-32k, LongBench-32k), SpB2.0 matches or surpasses prior large-scale linear or hybrid models, while outperforming the previous SpikingBrain1.0-7B.
The instruction-tuned SpB2.0-5B and reasoning-enhanced (Thinking, OPD) variants achieve competitive or superior performance to DeepSeek-R1 and Qwen3-Thinking on reasoning-heavy datasets and maintain MMLU generalization.
SpB2.0-VL-5B attains parity or superiority over 2–3× larger baselines (Qwen2.5-VL-3B, LLaVA-OneVision-7B) on multimodal QA (AI2D, ChartQA, DocVQA), OCR (OCRBench), and general MMStar/MMBench evaluations, demonstrating the preservation of strong visual reasoning across drastic architectural transformations.
Inference Efficiency and Scaling
- TTFT Speedups: Under HuggingFace sequence parallelism, SpB2.0-5B realizes a 10.13× TTFT speedup at 4M context length relative to baseline Transformer.
- vLLM Metrics: Under vLLM tensor parallelism, SpB2.0 achieves up to 4.5× TTFT, 1.12× TPOT, and 4.3× end-to-end latency speedups at 512k; can serve >10M-token requests on 8×A100s, while FA-Transformers OOM at 4M.
- Throughput and Concurrency: 3.17× higher request concurrency and 1.57× higher prompt/generation throughput.
Quantization Hardware Results
- INT8-Spiking: Hardware simulation yields 70.6% area reduction and 46–48% power reduction at comparable clock speeds over standard INT8 inference.
- FP8: Delivers 2.52× practical inference speedup with only 0.24% accuracy depreciation.
Implications and Future Directions
SpB2.0 concretely demonstrates that rigorous integration of brain-inspired mechanisms—sparse attention, event-driven coding, and quantization-robust training—enables foundation models to surmount the classic context-length/efficiency barrier inherent to vanilla Transformers. The DSSA hybrid successfully aligns biological plausibility with industrial scalability, avoiding the performance collapse characteristic of pure LA/SWA models or naively quantized architectures.
The efficient T2H conversion pipeline establishes an empirically validated paradigm for rapid, data-efficient migration from conventional Transformers to advanced hardware-aware hybrids, with both theoretical and practical relevance for LLM/VLM deployment on heterogeneous computing substrates, including neuromorphic edge hardware.
Future developments are expected in several directions:
- Automated hybrid layer selection optimizing the DSSA configuration per downstream workload and hardware constraints.
- Enlarged-scale (10–100B+) brain-inspired architectures trained via OPD or direct RL, exploiting neuromorphic acceleration.
- More generalizable quantized and event-driven activation schemes bridging low-power AI computing with high-precision cognitive modeling.
Conclusion
SpikingBrain2.0 provides an effective and empirically validated pathway for foundation model scaling under long-context and resource constraints, unifying algorithmic efficiency, hardware adaptation, and practical trainability. The DSSA architecture, dual-path quantization, and the T2H training protocol together position SpB2.0 as a reference platform for the next generation of efficient, biologically inspired large models capable of cross-platform deployment without substantial compromise in accuracy or generalization.