InfLLM-V2: Dense-Sparse Switchable Attention for Seamless Short-to-Long Adaptation
Abstract: Long-sequence processing is a critical capability for modern LLMs. However, the self-attention mechanism in the standard Transformer architecture faces severe computational and memory bottlenecks when processing long sequences. While trainable sparse attention methods offer a promising solution, existing approaches such as NSA introduce excessive extra parameters and disrupt the conventional \textit{pretrain-on-short, finetune-on-long} workflow, resulting in slow convergence and difficulty in acceleration. To overcome these limitations, we introduce dense-sparse switchable attention framework, termed as InfLLM-V2. InfLLM-V2 is a trainable sparse attention that seamlessly adapts models from short to long sequences. Specifically, InfLLM-V2 reuses dense attention parameters through parameter-free architecture modification, maintaining consistency between short and long sequence processing. Additionally, InfLLM-V2 ensures computational efficiency across all sequence lengths, by using dense attention for short inputs and smoothly transitioning to sparse attention for long sequences. To achieve practical acceleration, we further introduce an efficient implementation of InfLLM-V2 that significantly reduces the computational overhead. Our experiments on long-context understanding and chain-of-thought reasoning demonstrate that InfLLM-V2 is 4$\times$ faster than dense attention while retaining 98.1% and 99.7% of the performance, respectively. Based on the InfLLM-V2 framework, we have trained and open-sourced MiniCPM4.1 (https://huggingface.co/openbmb/MiniCPM4.1-8B), a hybrid reasoning model, providing a reproducible implementation for the research community.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper introduces a faster way for LLMs to handle very long texts without losing accuracy. The new method is called InfLLM‑V2. It lets a model smoothly switch between two styles of “attention” (how the model focuses on different parts of text): a normal, full style for short inputs and a lighter, sparse style for long inputs. The big idea is to keep the model’s original settings and knowledge while adding speed for long sequences—without adding extra parts or parameters that make training harder.
What questions the researchers asked
Here’s what the team wanted to solve, in simple terms:
- Can we make LLMs read and write very long texts much faster, without hurting accuracy?
- Can we do that in a way that fits the usual training process: first train on short texts, then fine‑tune on long texts?
- Can we avoid adding lots of extra parameters and complicated modules that slow training or cause confusion for the model?
- Can we build the system so it’s efficient on real hardware (like GPUs), not just in theory?
How the method works (with simple analogies)
First, a quick overview of “attention”:
- Think of a text as a long conversation. Each word (or “token”) can pay attention to other words to understand what matters.
- “Dense attention” is like everyone listening to everyone else in the room—great for small groups, but too slow and noisy when the room is huge.
- “Sparse attention” is like each person only listening to the most relevant people—much faster for large groups.
InfLLM‑V2 makes it easy to switch between dense and sparse attention:
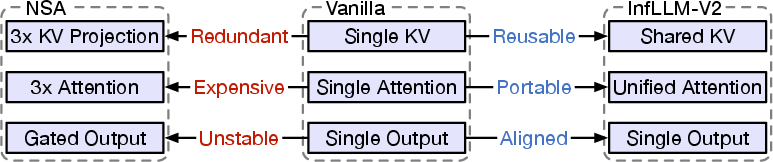
The switchable design (no extra parts)
- Many older methods add new modules and parameters for sparse attention. That’s like bolting on three extra radios to a student just to help them listen better in a bigger classroom—heavy and confusing.
- InfLLM‑V2 reuses the same “ears” (the same key‑value parameters) the model already has. No extra parameters. So the model can use dense attention for short texts and sparse attention for long texts without changing its “brain.”
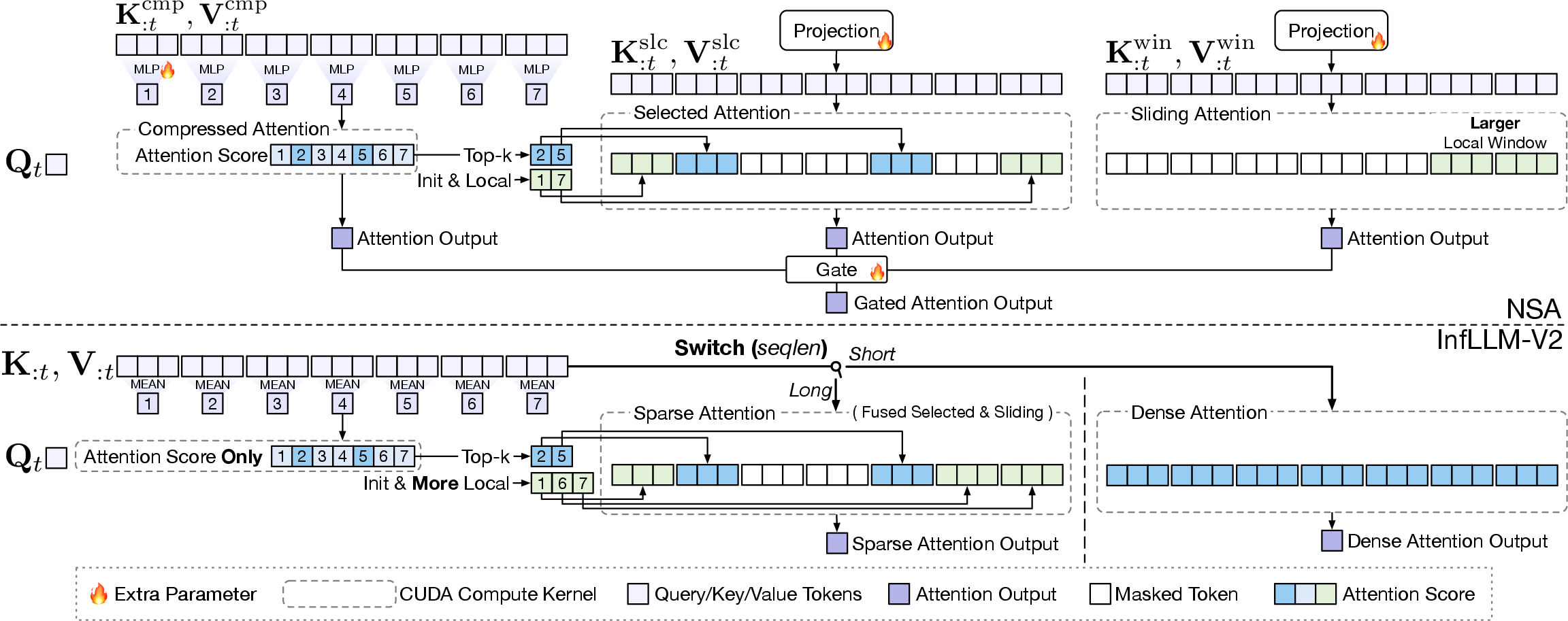
Picking what to focus on (smart sparse attention)
- The model divides the text into chunks called “blocks” (think of pages or paragraphs).
- It first makes a quick summary of each block (using simple averaging and max pooling, like taking a quick skim).
- Based on these summaries, it picks a small set of important blocks to focus on:
- Some always-important starting blocks (like an introduction).
- Nearby blocks (local context).
- The top‑K most relevant blocks anywhere else.
- This combines two useful patterns:
- Local “sliding window” attention (listen closely to your neighbors).
- Selected attention (listen to the few most relevant distant blocks).
- The “compressed attention” is used only for deciding which blocks to select. It does not produce a final output itself—this makes training simpler and more similar to the normal dense attention the model learned first.
Making it fast on real GPUs
- GPUs have fast on‑chip memory (SRAM) and slower big memory (HBM). Moving huge matrices to HBM can be a slowdown.
- InfLLM‑V2 keeps as much calculation as possible in fast memory, and cleverly fuses steps together so there’s less data shuffling.
- A trick called “LSE Approximation” estimates a normalization term using coarser summaries first, reducing extra passes and saving time.
- Result: the “block selection” step (choosing what to pay attention to) no longer dominates the runtime, unlocking the full speed of sparse attention.
What they found and why it matters
Here are the main results:
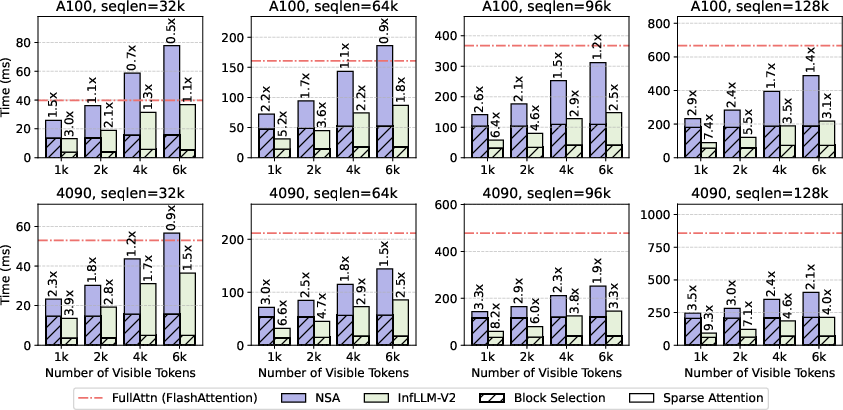
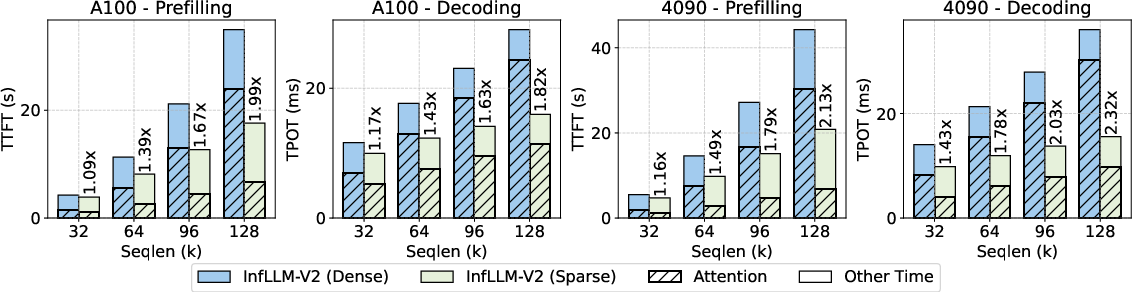
- Speed: On long inputs, InfLLM‑V2 is about 4× faster than normal dense attention. In end‑to‑end tests, it achieved around 2× speedups for both “prefill” (reading the input) and “decoding” (writing the output).
- Accuracy: It keeps almost all the performance—98.1% on long‑context understanding and 99.7% on long chain‑of‑thought reasoning—compared to full attention.
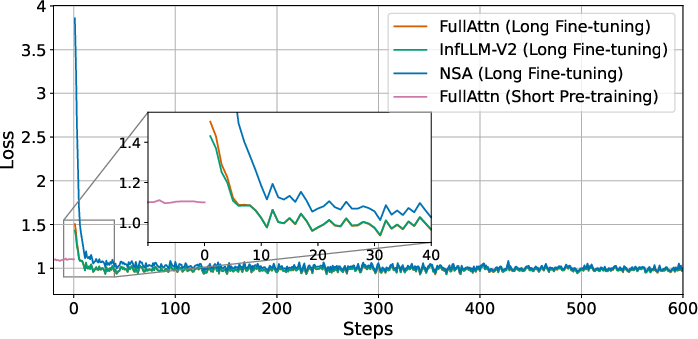
- Stability: Because InfLLM‑V2 uses the same parameters as the original dense attention, fine‑tuning from short to long sequences is smooth. It avoids the training instability seen in some older sparse methods that add lots of extra parameters.
- Flexibility: It can switch back to dense attention for short inputs without losing performance. That means it’s efficient across all sequence lengths.
- Practicality: The team open‑sourced a model called MiniCPM4.1 (8B parameters), showing this approach can be reproduced and used by others.
Why this matters: Many real tasks need long memory and long outputs—like deep research, code understanding, long chats, or detailed reasoning. Faster attention means lower costs and shorter waiting times, without sacrificing quality.
What this could mean for the future
InfLLM‑V2 shows a practical path to efficient long‑sequence LLMs:
- It fits the standard training pipeline: train on short, fine‑tune on long—without architectural mismatches.
- It brings real speedups on common GPUs by reducing memory bottlenecks.
- It keeps performance high while making models more usable for long documents and long reasoning.
In short, InfLLM‑V2 helps LLMs handle very long texts quickly and accurately, making them more powerful and more affordable to run in real‑world applications.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, formulated to guide actionable future research.
- Missing theoretical guarantees for the sparse approximation: no error bounds or stability analysis for the two-pass softmax with LSE Approximation, the block-level compression (mean/max pooling), or the union of Selected and Sliding Attention; unclear worst-case impact on attention bias and output variance.
- Decoding-phase mechanics are under-specified: the paper claims acceleration for decoding but does not detail incremental block selection logic, cache updates, or error accumulation over long generations; needs an explicit algorithmic description and kernel performance profile for decoding.
- Switching policy is not formalized: “dense-sparse switchable” behavior lacks a principled thresholding strategy (e.g., length, entropy, or budget-based triggers); overheads and hysteresis effects of switching are not measured.
- Sparse hyperparameter sensitivity is largely unexplored: no ablations on block size B, window size w, number of local/init/top-k blocks, selected-block count |I|, or group size G; accuracy–efficiency trade-offs and safe operating regions are unclear.
- Group-level block selection may limit expressivity: enforcing shared block selection within GQA head groups could suppress head diversity; needs ablations where selection per head (or per subgroup) is allowed, and analysis of any quality gains vs. cost.
- Parameter-free compression may be suboptimal: replacing NSA’s trainable compression with mean/max pooling simplifies the design but might cap performance; evaluate small-footprint trainable pooling/routers (e.g., low-rank, per-block lightweight modules) without disrupting short-to-long alignment.
- Performance at very long contexts remains untested: quality is reported at 32k (RULER) while kernel timings go to 128k; no accuracy or perplexity results for ≥64k, ≥128k, or million-token regimes; investigate how fixed visible tokens (e.g., 6k) scale with longer inputs.
- Failure-mode analysis is missing: categories with notable drops vs. full attention (e.g., RULER MK2/MK3, CWE) are not investigated; need diagnostic tooling to identify patterns missed by block selection and to guide adaptive selection rules.
- Limited architectural generality: only 8B GQA is evaluated; robustness across model scales (30B, 70B+), attention types (MHA/MQA), encoder–decoder architectures, and MoE models is unknown.
- Hardware portability is unclear: kernels are tested on NVIDIA A100/4090; performance, numerical stability, and memory behavior on H100, consumer GPUs with limited SRAM, AMD ROCm, TPU, and specialized accelerators remain unreported.
- Memory footprint benefits are not quantified: speedups are given, but end-to-end GPU memory savings (KV cache size, peak activation memory) for prefill and decoding are not measured; assess capacity gains and out-of-memory thresholds.
- Interaction with KV eviction/compression is untested: potential synergies with H2O, SnapKV, LocRet, etc. could further reduce memory and improve throughput; quantify combined effects and conflicts in selection/eviction policies.
- Benchmark coverage is narrow for long-output tasks: long reasoning evaluation uses typical CoT tasks; no stress tests on ultra-long generation (e.g., book-level outputs), multi-step tool use, or agent trajectories with persistent memory.
- Training efficiency and compute budget are not reported: sparse long-context finetuning used 5B tokens, but wall-clock time, GPU hours, and speedup vs. dense finetuning are missing; sample-efficiency benefits and convergence rates need quantification.
- End-to-end speedups do not match kernel-level gains: abstract claims “4× faster,” while E2E results show ~2.1× prefill and ~2.3× decode speedup under W4A16 quantization; clarify measurement setup, bottlenecks (e.g., FFN), and conditions under which 4× is achieved.
- Quantization impact on quality is not evaluated: speed numbers use W4A16, but task accuracy and perplexity under quantization are not reported; study numerical sensitivity and calibration for sparse kernels.
- NSA comparison may be confounded: NSA results rely on a third-party Triton implementation (not official), and only short-to-long adaptation is tested; fair-from-scratch training baselines and implementation parity are needed.
- Missing comparisons to other trainable sparse methods: SeerAttention and MoBA are cited but not empirically compared (even for prefill-only scenarios); provide apples-to-apples evaluations under matched sparsity and sequence lengths.
- Sparse selection stability over time is unknown: the top-k block set may fluctuate across steps (especially during decoding), potentially introducing instability; measure temporal consistency and its effect on generation coherence.
- Lack of principled selection objectives: current selection is heuristic (mean/max pooling + top-k); explore learning objectives (e.g., maximizing mutual information, minimizing attention approximation error) without large parameter overhead.
- No analysis of distributional shift claims: “seamless” adaptation is asserted, but metrics beyond training loss (e.g., KL divergence of attention distributions pre/post adaptation, calibration curves, or head activation patterns) are not provided.
- Integration with FFN acceleration is left for future work: since FFN dominates inference cost, quantify how combined techniques (e.g., low-rank FFN, block-sparse MLPs) affect total speedups and accuracy.
- Max-pooling and top-k fusion into kernels is deferred: the paper notes these fusions could further cut I/O but are not implemented; define kernel designs, expected gains, and correctness tests.
- Applicability beyond text is untested: behavior on multimodal inputs (vision, audio) and structured contexts (tables, code ASTs) may differ due to pooling biases; evaluate domain-specific compression strategies.
- Practical deployment considerations are absent: batching effects, heterogeneous sequence lengths, caching across requests, and latency distributions in real systems need to be characterized for production use.
- Reproducibility and release scope are unclear: the paper references MiniCPM4.1, but does not specify whether optimized kernels, training scripts, and configs for all experiments (including long-context finetuning) are available; provide full artifacts.
Practical Applications
Immediate Applications
Below are specific, deployable use cases that leverage InfLLM‑V2’s dense–sparse switchable attention, parameter-free short‑to‑long adaptation, and efficient block selection kernels.
- Sector: Software/IT; Use case: Repository-scale code assistants and issue triage
- What: Repo-level Q&A, root-cause analysis over long logs, test failure triage, and long code review with 32k+ context.
- Why InfLLM-V2: 2–4× faster long-context attention with minimal quality loss; preserves short-context throughput by switching back to dense.
- Tools/workflows: Integrate the released MiniCPM4.1-8B; serve with InfLLM‑V2 kernels; W4A16 quantization; auto mode-switch by sequence length.
- Assumptions/dependencies: NVIDIA GPUs (A100/4090-class), GQA group size compatibility, Triton/CUDA kernels adopted in serving stack; domain finetuning may be needed for code quality.
- Sector: Customer support/Enterprise chat; Use case: Long-term memory chatbots over knowledge bases
- What: Assistants that read entire knowledge portals, policy handbooks, and multi-year FAQs while keeping latency/cost manageable.
- Why: Speedup on long inputs keeps TTFT low; sparse mode maintains quality with 6k visible tokens per query.
- Tools/workflows: RAG + InfLLM‑V2 sparse prefill; dense decode for short outputs; caching hot blocks across sessions.
- Assumptions/dependencies: Accurate retrieval/indexing; proper block-selection hyperparameters; privacy/compliance controls.
- Sector: Legal/Compliance/Finance; Use case: Contract analysis, 10‑K/10‑Q analysis, policy binder review
- What: Cross-document reasoning and redlining suggestions across 100+ page filings and policy binders.
- Why: InfLLM‑V2 preserves near‑dense accuracy on RULER/LongBench with 2–4× speedups.
- Tools/workflows: Batch prefill for large documents; page/block metadata to bias top‑k selection; human-in-the-loop review.
- Assumptions/dependencies: Domain adaptation to legal/finance language; audit trails for decisions; guardrails to mitigate hallucinations.
- Sector: Research/Academia; Use case: Multi-source literature review and deep research agents
- What: Aggregate, read, and reason across many papers, appendices, and citations in one pass; generate long chain-of-thought.
- Why: Comparable long-output performance to full attention on math/code reasoning; switchable modes reduce cost during exploration.
- Tools/workflows: Paper ingestion pipelines; context chunking aligned to block size; persistent research memory.
- Assumptions/dependencies: Citation-grounding tools; license-compliant corpora; reproducible seeds for benchmarked evaluations.
- Sector: Education; Use case: Course-scale tutoring over textbooks, lectures, and notes
- What: Tutor that can reference whole textbooks/syllabi and produce step-by-step solutions.
- Why: Long-CoT parity with dense attention and faster inference improves user experience on lengthy tasks.
- Tools/workflows: Curriculum to block-aligned segments; dense mode for short Q&A; sparse mode for long reading/solutions.
- Assumptions/dependencies: Pedagogical fine-tuning; safeguards against bias and incorrect pedagogy; student data privacy.
- Sector: Healthcare (non-diagnostic support); Use case: Longitudinal EHR summarization and clinical documentation assistance
- What: Summarize multi-year patient histories and long notes for care coordination and administrative tasks.
- Why: Long-input acceleration reduces turnaround time and compute; dense fallback for short notes retains precision.
- Tools/workflows: De-identified data pipelines; on-prem inference; audit logging of attended blocks for traceability.
- Assumptions/dependencies: Regulatory constraints (HIPAA/GDPR); domain adaptation; not for autonomous diagnosis.
- Sector: Data/Annotation Ops; Use case: Multi-document labeling and dataset curation at lower cost
- What: LLM-assisted labeling over long cases (support tickets, legal cases, literature) with near‑dense quality.
- Why: Cost-effective long-context inference enables higher throughput and broader context windows.
- Tools/workflows: Active learning loops; per-project block-selection tuning; human verification dashboards.
- Assumptions/dependencies: Quality control pipelines; budgeted GPU capacity; consistent tokenization across corpora.
- Sector: Cloud/Serving Platforms; Use case: Mixed short/long traffic optimization
- What: SLA-aware serving that switches dense for short requests and sparse for long requests per-layer/prompt.
- Why: Maintains short-prompt throughput while cutting cost for long prompts; supports both prefill and decode.
- Tools/workflows: Integration with inference servers (e.g., Triton/TensorRT-LLM or custom PyTorch/Triton); autoscaling by visible-token budget.
- Assumptions/dependencies: Kernel integration; scheduler aware of sequence length and visible-token counts; monitoring for accuracy drift.
- Sector: Personal productivity (daily life); Use case: Whole-mailbox and multi-year note assistant
- What: Search, summarize, and reason across entire email archives and personal notes without cloud roundtrips.
- Why: 4090-class efficiency enables prosumer/SMB local inference; switch to dense for short replies.
- Tools/workflows: Local vector store + InfLLM‑V2; configurable visible-token budgets; offline mode for privacy.
- Assumptions/dependencies: Desktop GPU availability; careful privacy handling; user consent for data access.
- Sector: MLOps/Model Dev; Use case: Short-to-long adaptation with zero extra parameters
- What: Upgrade existing dense checkpoints to long-context with stable convergence and minimal re-architecting.
- Why: Reuse KV projections; parameter-free architectural change; training curve close to full attention.
- Tools/workflows: Adopt the paper’s long-finetune recipe (block sizes, top‑k schedule, 5B-token long curriculum); unit tests vs dense baselines.
- Assumptions/dependencies: GQA with group size alignment (e.g., G=16); training data covering target lengths; evaluation on LongBench/LongPPL to validate.
Long-Term Applications
These scenarios require further research, scaling, or ecosystem support (e.g., broader hardware/software compatibility, extended modalities).
- Sector: On-device/mobile AI; Use case: Long-context assistants on laptops and edge accelerators
- What: Private assistants operating over full local document collections with acceptable latency.
- Why: InfLLM‑V2 reduces memory/computation per token; next steps include FFN acceleration and mobile kernels.
- Dependencies: Efficient kernels for non-NVIDIA hardware (Apple/AMD/NPU), memory-optimized KV-cache management, thermal limits.
- Sector: Robotics/Autonomy; Use case: Long-horizon planning with continuous memory
- What: Maintain long histories of observations and plans for household or warehouse robots.
- Why: Sparse attention can gate relevant history, scaling effective context.
- Dependencies: Real-time constraints, multi-modal tokenization (vision/sensor), safety certification.
- Sector: Multimodal AI (video/audio/text); Use case: Hour-long video understanding and multi-episode summarization
- What: Process long timelines (meetings, lectures, surveillance) with sparse attention across frames and transcripts.
- Why: Block-based sparsity aligns with temporal chunking; maintain quality with compressed scoring.
- Dependencies: Modal encoders producing block-aligned embeddings; careful pooling/compression for non-text signals.
- Sector: Training efficiency at scale; Use case: Pretrain-with-sparsity or curriculum from short to ultra-long (100k+)
- What: Incorporate trainable sparsity earlier in training to cut cost and extend windows.
- Why: Parameter-free design encourages alignment of dense and sparse regimes.
- Dependencies: Recipes for stable sparse pretraining, curriculum design, distributed training kernels and memory managers.
- Sector: Energy/Policy; Use case: Green AI inference standards for long-context workloads
- What: Establish procurement and reporting guidelines favoring dense–sparse switching to cut energy per token.
- Why: Demonstrated 2–4× attention speedups imply material energy savings at scale.
- Dependencies: Third-party energy benchmarks, standardized reporting (tokens/J), policy adoption by cloud providers.
- Sector: Privacy/Regulated industries; Use case: On-prem long-context copilots (legal, healthcare, finance)
- What: Keep data on private clusters while supporting very long documents and logs.
- Why: Efficiency enables smaller GPU fleets per workload.
- Dependencies: Compliance audits, reproducibility of sparse selection, explainability of attended blocks.
- Sector: Foundation model infrastructure; Use case: Standard APIs for dense–sparse switch and block-selection telemetry
- What: Observability into which blocks were attended; dynamic policies per tenant/task.
- Why: Improves debuggability and governance of sparse inference at scale.
- Dependencies: Ecosystem support in serving frameworks; interoperable telemetry formats.
- Sector: End-to-end system acceleration; Use case: 4–10× total speedups via FFN + attention co-acceleration
- What: Combine InfLLM‑V2 with FFN sparsity/low-rank, paged KV, and cache-eviction methods.
- Why: Current gains are attention-dominant; FFN remains a bottleneck for higher speedups.
- Dependencies: Compatible FFN kernels, stability under quantization, scheduling across heterogeneous sparsity methods.
Notes on general assumptions across applications:
- Performance bounds were validated on specific GPUs (A100/4090), batch=1, with visible tokens around 6k; results may vary for different batch sizes, hardware, or longer contexts.
- GQA configuration and group size (e.g., G=16) are important to match the kernel’s efficiency characteristics.
- LSE approximation and compression hyperparameters trade compute vs. fidelity and may require tuning per domain.
- Sparse attention does not accelerate FFNs; holistic E2E speedups depend on additional system optimizations.
- For sensitive domains (healthcare, legal, finance), human oversight, auditing, and domain-specific evaluation are essential before production deployment.
Glossary
- Attention score matrix: The matrix of attention weights computed between queries and keys in an attention layer; its sparsity enables efficiency gains on long sequences. Example: "the attention score matrix exhibits strong sparsity."
- Block granularity: Operating at the level of contiguous token blocks rather than individual tokens for efficiency and scalability. Example: "perform relevance computation and context selection at the block granularity"
- Block selection: Choosing a subset of relevant blocks to attend to before running sparse attention to reduce computation. Example: "The block selection step before sparse attention inherently undermines the efficiency gains of the sparse attention itself."
- Block-sparse attention: An attention pattern where tokens attend to selected blocks, reducing complexity compared to dense attention. Example: "adopts the widely-used block-sparse attention~\citep{sparsetransformer} structure"
- Chain-of-thought (CoT): Generating step-by-step reasoning in model outputs to improve problem solving. Example: "long-context understanding and chain-of-thought reasoning"
- Compressed Attention: A module that computes attention using compressed key-value representations to reduce cost. Example: "Compressed Attention employs a compressed representation of the KV tensors to reduce the computational complexity."
- Context window: The maximum sequence length the model can process at once (input or memory range). Example: "Short with YaRN~\citep{yarn} to extend the context window size."
- CUDA kernels: GPU-executed routines optimized for specific operations (e.g., attention) to accelerate computation. Example: "developing corresponding CUDA kernels to accelerate model computation."
- Decoding: The token-by-token generation phase of inference following the initial context processing. Example: "effectively accelerating both prefilling and decoding processes."
- Dense attention: Standard full attention where each token can attend to all tokens in the context. Example: "by using dense attention for short inputs"
- Dense-sparse switchable attention: A design allowing seamless switching between dense and sparse attention based on sequence length. Example: "dense-sparse switchable attention framework"
- FlashAttention: An optimized attention algorithm that reduces memory I/O by computing attention in SRAM-friendly tiles. Example: "Drawing inspiration from FlashAttention~\citep{flashattention}"
- FlashAttention-2: A faster, improved implementation of FlashAttention with better parallelism and partitioning. Example: "We select FlashAttention-2~\citep{flashattention} implementation for full attention."
- Gating module: A learned mechanism that weights and combines outputs from multiple attention components. Example: "combines them using a gating module."
- Grouped-Query Attention (GQA): An attention variant where multiple query heads share a smaller number of key-value heads to balance performance and efficiency. Example: "grouped-query attention (GQA)~\citep{gqa} has emerged as a popular method"
- GPU HBM: High Bandwidth Memory on GPUs used for large-capacity but slower storage compared to on-chip memory. Example: "store the first-stage attention scores into the slow GPU HBM."
- GPU SRAM: Fast on-chip GPU memory used to minimize I/O and accelerate compute-intensive kernels. Example: "remain within the fast GPU SRAM"
- Head dimension: The size of each attention head’s feature vector in multi-head attention. Example: "with the head dimension ."
- Key-value (KV) caches: Stored key and value tensors from past tokens used during decoding to avoid recomputation. Example: "KV caches with low attention probabilities"
- Key-value (KV) eviction: Removing less important KV entries from caches to reduce memory and speed up inference. Example: "KV eviction and compression methods"
- Key-value (KV) projection matrices: Learnable linear maps that produce keys and values from hidden states. Example: "three sets of KV projection matrices"
- Log-sum-exp (LSE): A numerically stable operation used to compute softmax normalization. Example: "initialize online-softmax related statistic log-sum-exp ."
- LSE Approximation: A technique to approximate the log-sum-exp term to reduce computation and memory I/O. Example: "we propose LSE Approximation"
- Max-pooling: Aggregation operation that selects the maximum value in a region, preserving salient features. Example: "we apply a max-pooling operation"
- Mean-pooling: Aggregation operation that averages values over a region to produce a compressed representation. Example: "applying a mean-pooling operation over sequential blocks"
- Multi-Layer Perceptron (MLP): A feedforward neural network used as auxiliary modules (e.g., gating or compression). Example: "via an MLP and a sigmoid activation."
- Natively trainable sparse attention (NSA): A sparse attention design trained end-to-end with specialized modules and parameters. Example: "NSA~\citep{nsa} is an enhancement of GQA designed for efficiency on long sequences."
- Online-softmax: A streaming softmax computation technique used in tiled attention kernels to avoid materializing full score matrices. Example: "performing the online-softmax~\citep{flashattention} along the sequence dimension"
- Prefilling: The phase of processing the full input context before generation begins. Example: "InfLLM-V2 can achieve prefilling speedup."
- Router: A learned component that selects relevant context blocks or tokens for sparse attention. Example: "train a router that selects relevant contexts for query blocks."
- Selected Attention: A module that computes attention only over blocks chosen as important by prior scoring. Example: "Selected Attention leverages the attention scores from compressed attention to compute only the blocks with high attention scores."
- Sliding Attention: A module focusing attention on local neighborhoods within a sequence. Example: "Sliding Attention is used to focus on local contextual information within the sequence."
- Sliding window attention: An attention pattern restricting tokens to attend to a fixed-size local window. Example: "sliding window attention restricts each token to interact only with neighboring tokens~\citep{longformer}."
- Sparse attention: Attention where tokens attend to a subset of the context to reduce computational and memory cost. Example: "trainable sparse attention methods"
- Time-per-output-token (TPOT): A latency metric for how long it takes to produce each generated token during decoding. Example: "TPOT means time-per-output-token."
- Time-to-first-token (TTFT): A latency metric for the delay until the model outputs the first token after input. Example: "TTFT means time-to-first-token"
- Top-k selection: Choosing the k highest-scoring blocks or tokens to attend to under sparsity constraints. Example: "The top-k selection is then applied to $\mathbf{S}^{\text{cmp}$ over the set of remaining blocks"
- Triton implementation: A GPU kernel implementation written in Triton for efficient attention operations. Example: "we adopt an open-source Triton implementation of NSA for experiments"
- W4A16 quantization: A quantization scheme using 4-bit weights and 16-bit activations to accelerate inference. Example: "with a and W4A16 quantization~\citep{marlin}"
- YaRN: A method for extending the context length of LLMs without retraining from scratch. Example: "Short with YaRN~\citep{yarn} to extend the context window size."
Collections
Sign up for free to add this paper to one or more collections.