- The paper introduces a diarization-aware ASR system that reformulates multi-speaker transcription as speaker- and segment-conditioned dialogue turns.
- It integrates explicit diarization priors with a language model to achieve accurate speaker attribution and word-level timestamp prediction.
- Empirical evaluations demonstrate robust performance, with the compact model outperforming larger systems under challenging multi-speaker conditions.
Motivation and Problem Statement
Multi-speaker ASR is a structurally complex task combining lexical recognition, speaker attribution, and temporal localization. Direct end-to-end Speech-LLMs have demonstrated promise in modeling these aspects but require substantial model capacity and broad data coverage for strong performance, especially under overlapping speech and rapid turn-taking conditions. Traditional cascaded diarization-ASR pipelines, while modular, propagate errors and neglect speaker-text alignment in the presence of speaker overlaps and long conversational context.
The DM-ASR framework (2604.22467) addresses this by exploiting explicit diarization priors as structured prompts for LLM-based multi-turn dialogue generation. The approach reformulates multi-speaker recognition as a series of speaker- and segment-conditioned transcription tasks. This explicit separation leverages diarization cues for robust attribution and segment delimitation, while harnessing LLM capabilities for content modeling and context tracking.
Model Architecture and Diarization-Aware Prompting
DM-ASR consists of four principal modules: a frame-level speech encoder, a projection module mapping acoustic features into the LLM token embedding space, a LLM decoder, and a discretization mechanism for diarization outputs (speaker mapping and timestamp indexing). The diarization system (e.g., DiariZen or S2SND) provides segment boundaries and speaker assignments, which are mapped to chunk-relative indices and quantized timestamp tokens.
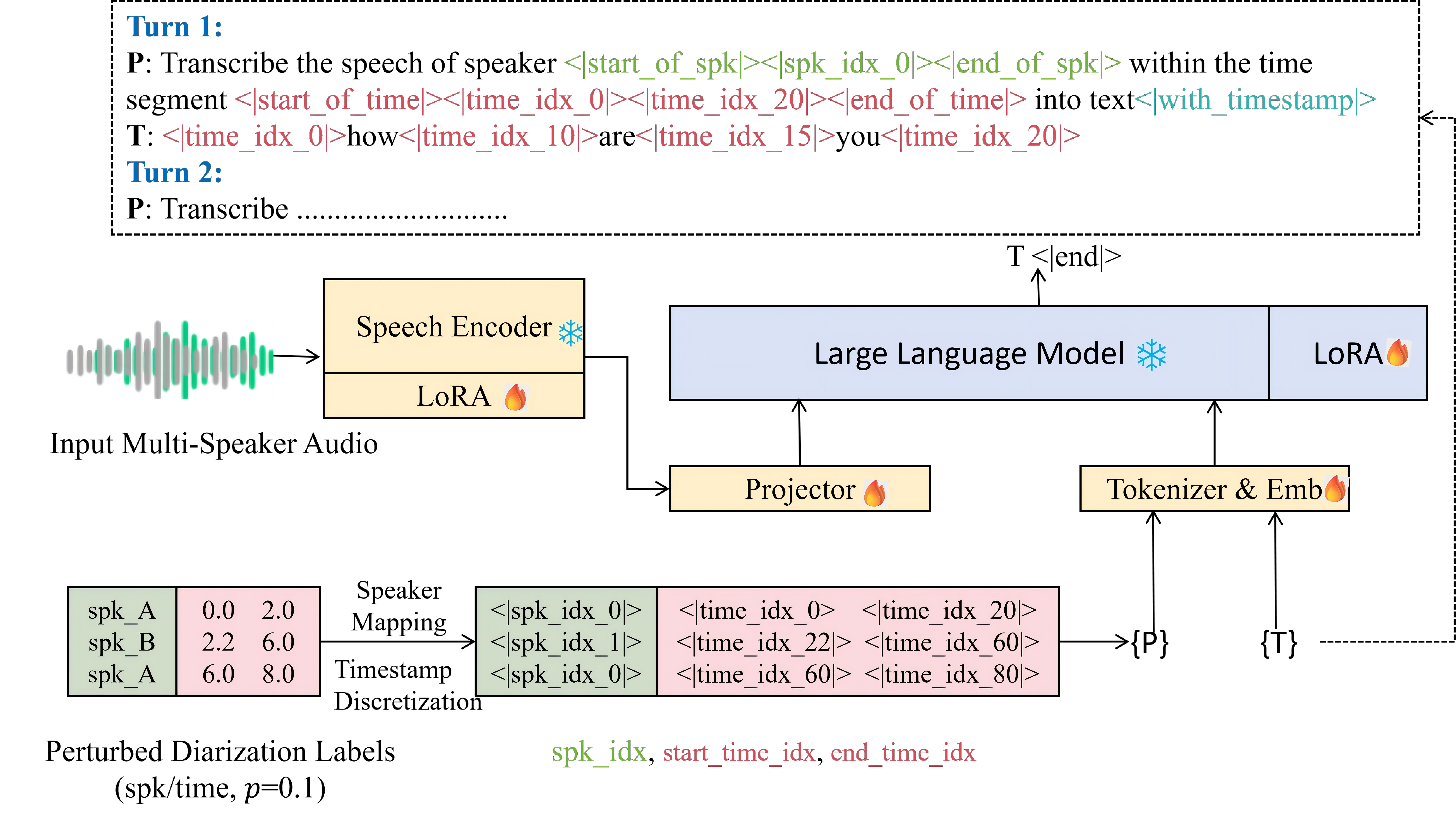
Figure 1: DM-ASR framework detail—random perturbation of diarization outputs enhances robustness to imperfect cues.
Special tokens encode speaker indices, timestamps, and delimiters, facilitating explicit structured prompting. Time quantization uses a fixed resolution (e.g., Δt = 0.1 s) for discrete temporal indices.
Multi-turn Dialogue Generation and Word-level Timestamp Conditioning
Multi-speaker recognition is converted into a sequence of dialogue turns, each consisting of a diarization-conditioned prompt (specifying speaker and segment) and a corresponding transcription. The first turn includes audio features plus a prompt; subsequent turns operate purely textually, referencing cached states for context and speaker consistency.
Word-level timestamp prediction is supported via a dedicated control token (<|with_timestamps|>). The output format is an interleaved sequence of word and timestamp tokens, yielding temporally grounded transcription. This alignment not only provides granular timestamps but imposes stronger local lexical-acoustic correspondence, empirically improving transcription quality.

Figure 2: Illustration of DM-ASR's multi-turn dialogue structure and prompt-response format.
Robustness to Imperfect Diarization and Perturbed-label Training
To overcome over-reliance on diarization accuracy, DM-ASR integrates randomized perturbation of diarization outputs (p=0.1) during training. This induces label mismatches in speaker or segment boundaries, forcing the model to rely on both acoustic context and inter-turn consistency for correction. Teacher forcing concatenates all turns in a chunk for cross-entropy loss calculation, anchoring supervision to the reference transcription regardless of prompt accuracy.
Empirical Evaluation and Numerical Results
DM-ASR was evaluated on both Mandarin and English benchmarks (AliMeeting, AISHELL-4, AMI, ICSI, Fisher) under variable model sizes, training data scales, and front-end diarization quality. The evaluation measured DER, cpCER/ cpWER, and tcpCER/ tcpWER.
Key numerical highlights:
- DM-ASR (S2SND, 1.7B, CN+EN 2900h) achieves DER = 10.09%, cpCER = 21.40%, tcpCER = 21.79% on Mandarin tasks, with competitive or superior performance to larger multimodal foundation models (e.g., Gemini-2.5-Pro, Qwen2.5-Omni-7B) despite reduced parameter count and data scale.
- Word-level timestamp supervision improves both temporal grounding and text accuracy (cpCER/tcpCER reduction observed).
- DM-ASR demonstrates robust speaker refinement and timestamp correction under perturbed training and imperfect diarization, with narrowed performance gaps across evaluation setups as data/model scale increases.
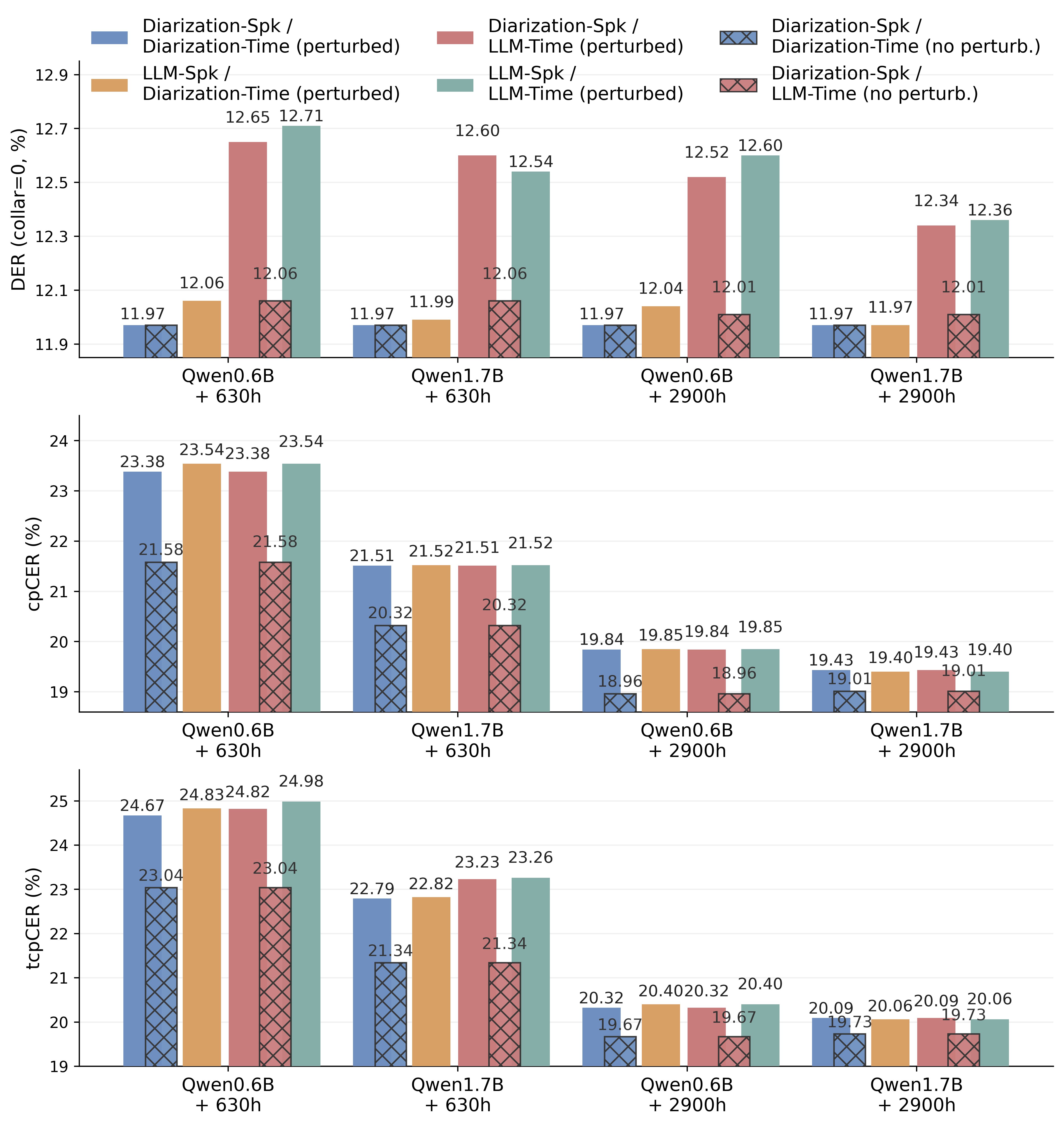
Figure 3: DER, cpCER, and tcpCER comparison across evaluation setups on AISHELL-4, including perturbed and non-perturbed training.
Contradictory claim: The paper asserts that even with a compact model and limited training data, DM-ASR outperforms large-scale unified Speech-LLMs and multimodal models, provided diarization priors are available.
Theoretical and Practical Implications
Theoretically, DM-ASR validates the utility of explicit structural prompting in dialogue-style ASR, augmenting traditional modularity with LLM contextual capacity. The separation of diarization-based structure from content modeling mitigates the scaling demands for robust multi-speaker transcription. Practically, this enables deployment with smaller models and less extensive corpora, reducing resource overhead for meeting and conversational transcription.
The paper also demonstrates the necessity of explicit temporal grounding (word-level timestamps), a capability still weakly integrated in most prior Speech-LLMs. The perturbation-driven robustness mechanism provides a pathway for correcting upstream diarization errors, making the framework suitable for noisy or under-resourced front-end conditions.
Future Directions
The paper posits that further scaling of model and data will likely allow full LLM-predicted speaker and timestamp outputs to match or surpass diarization-driven approaches. Integrating self-consistent segment generation, improved multimodal alignment, and enhanced chunk-wise and cross-chunk context modeling are prospective areas for advancement. Joint optimization of diarization and transcription modules, and end-to-end fine-tuning with larger backbone LLMs, could further enhance performance and generalizability.
Conclusion
DM-ASR introduces a diarization-aware, multi-turn dialogue generation paradigm for multi-speaker ASR, achieving robust speaker attribution, accurate temporal grounding, and high lexical accuracy with moderate model and data scale. Strong empirical results demonstrate that explicit diarization priors are indispensable for small-size ASR models, while perturbation-based training provides robustness for future scaling. The approach has practical deployment advantages and implies that structural prompting can bridge the gap between modular pipelines and large unified LLMs in conversational speech recognition.
Reference: DM-ASR: Diarization-aware Multi-speaker ASR with LLMs (2604.22467).