- The paper presents an agentic, multi-turn ASR system that iteratively integrates speaker diarization, transcription, and timestamp identification.
- It introduces a speaker-aware cache and a progressive training strategy, achieving lower DERs and cpCERs on challenging benchmarks like AISHELL-4 and AliMeeting.
- The approach mitigates error propagation in complex, overlapping speech scenarios, ensuring reliable speaker tracking and transcription accuracy.
Speaker-Reasoner: Multi-turn Temporal Reasoning for Timestamped Speaker-Attributed ASR
Introduction and Motivation
Automatic Speech Recognition (ASR) for multi-speaker conversations fundamentally requires joint modeling of speaker diarization, transcription, and temporal localization. Traditional cascaded pipelines—separating speaker diarization and ASR—suffer from error propagation, lack of global optimization, and struggle in complex conversational scenarios such as overlapping speech and rapid turn-taking. Recent end-to-end models with Serialized Output Training (SOT) and large multimodal LLMs improve integration but often treat the task as a single-turn sequence generation challenge. This neglects the inherent multi-level temporal reasoning required by real-world conversations, where speakers alternate, overlap, and interact over long contexts.
Speaker-Reasoner introduces an agentic, multi-turn reasoning mechanism tailored for full timestamped speaker-attributed ASR (SA-ASR), advancing beyond single-pass inference. The model iteratively analyzes global audio structure, proposes candidate temporal boundaries, and performs fine-grained segment-level reasoning, thereby scaling interaction turns and temporal reasoning patterns for more robust performance in diverse multi-speaker audio.
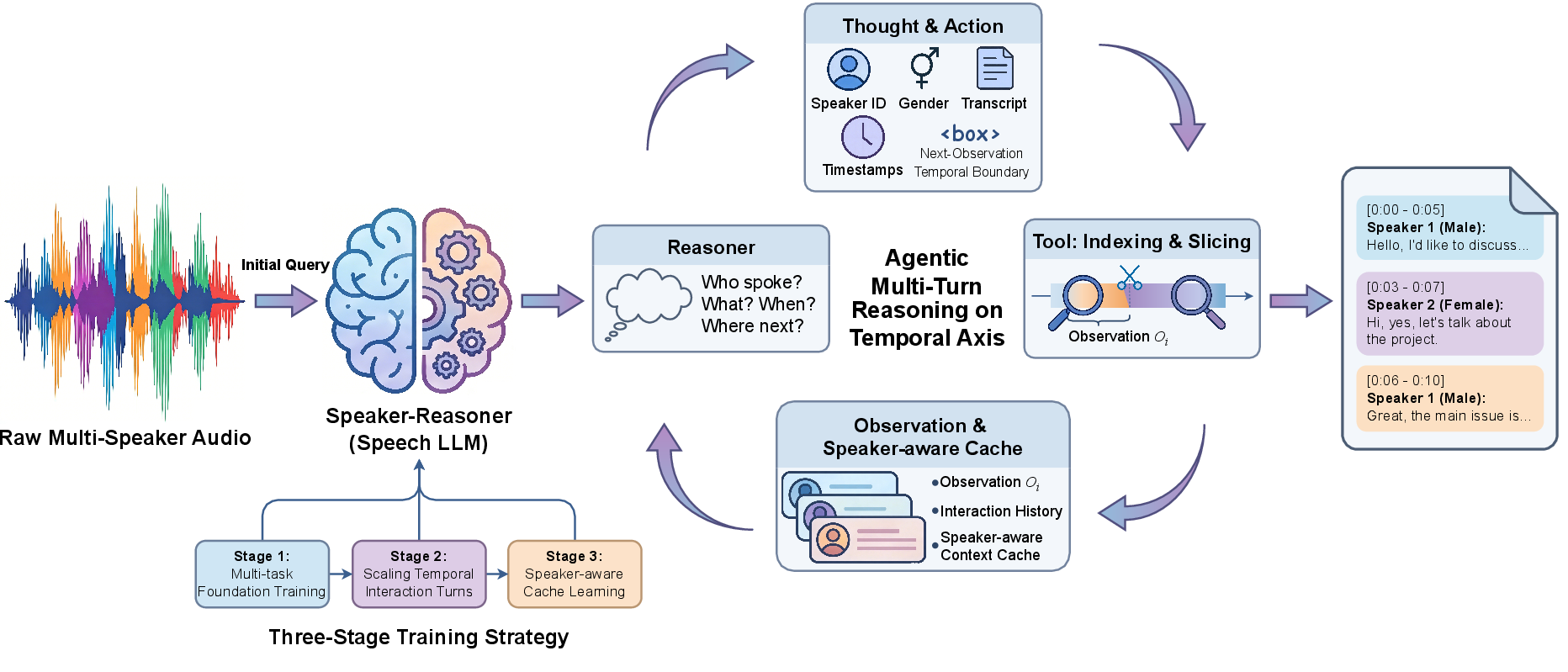
Figure 1: Speaker-Reasoner applies iterative multi-turn temporal reasoning with an agentic protocol, leveraging an indexing/slicing tool and a speaker-aware context cache to generate speaker, gender, timestamps, and transcription from multi-speaker audio.
Architecture and Inference Protocol
Speaker-Reasoner is built on an instruction-tuned speech LLM framework initialized from Qwen3-Omni. Its architecture consists of:
Inference is framed as an iterative process along the temporal axis. The model begins by globally analyzing audio to identify speakers and their attributes, then incrementally processes temporally-indexed observations. At each turn, it predicts speaker identity, gender, timestamps, and transcribed text for local segments, using both prior interaction history and an explicit speaker-aware context cache.
A key innovation is the speaker-aware cache, which maintains and adapts speaker-specific acoustic exemplars across the entire recording. During inference, cache entries are dynamically selected based on a joint criterion of segment duration and recency; this enables robust speaker consistency and identity tracking, even as audio exceeds the context window.
The multi-turn protocol terminates when a complete, chronologically-ordered, speaker-attributed transcript is constructed.
Progressive Training Strategy
Speaker-Reasoner is trained via a staged curriculum:
- Multi-task Foundation: Teacher-forced autoregressive prediction of the full structured output (including speaker, gender, timestamps, and transcription).
- Temporal Interaction Optimization: Supervises the model on partial audio slices with explicit boundary token objectives, exposing it to temporal reasoning and segment transitions.
- Speaker-aware Cache Conditioning: Introduces cache entries during training, drawn from historical segments, to enforce speaker identity continuity and robustness to context-slice boundaries.
This curriculum equips the model for both accurate transcription and robust joint speaker tracking over long, multi-party recordings.
Experimental Results
Evaluations are conducted on AliMeeting and AISHELL-4—benchmark datasets for Mandarin meeting transcription featuring substantial real-world conversational complexity.
Strong numerical results include:
- On AISHELL4-Eval, Speaker-Reasoner Multi-turn w/ SAC achieves Diarization Error Rate (DER) of 5.26% and concatenated minimum-permutation Character Error Rate (cpCER) of 14.73%, outperforming competitive baselines such as Gemini-2.5-Pro and VibeVoice-ASR.
- On Alimeeting-Far, DER is 7.34% and cpCER 20.43%, demonstrating consistent robustness in challenging far-field and high-overlap conditions.
- The model achieves a notably negative Δcp (-0.14%) on Alimeeting-Far—a rare phenomenon—indicating cpCER is lower than standard CER due to compensation by optimal permutation alignment, reflecting highly precise speaker tracking.
The performance gain is not solely a function of parameter count; even Speaker-Reasoner 7B outperforms specialized high-data baselines. Ablation studies further show that the transition from standard SOT to agentic multi-turn reasoning provides significant error reductions, and the addition of speaker-aware cache ensures scalability to recordings exceeding the base context window.
When evaluated on unsegmented, long-form AISHELL-4-Eval recordings, Speaker-Reasoner exhibits reasonable DER (21.60%) and cpCER (36.20%), roughly on par with Gemini-2.5-Pro, validating the efficacy of the speaker-aware cache for context extension.
Global speaker attribute inference is also superior: gender accuracy and speaker count accuracy reach 96.80% and 69.03% respectively, outperforming major competitors and showcasing iterative global-to-local reasoning's advantage in comprehending whole-conversation structure.
Implications and Future Directions
Speaker-Reasoner's agentic, multi-turn temporal reasoning demonstrates clear advantages for timestamped speaker-attributed ASR, particularly in overlapping, interactive, and long-form speech scenarios. The explicit modeling of progressive temporal structure—mirroring advances in visual LLM reasoning—enables detailed control over segment boundary inference, speaker tracking, and attribute prediction, thereby mitigating the error propagation and context limitations inherent to prior methods.
Practically, this approach improves the reliability of automated meeting transcription, diarization for conversational AI agents, and multi-speaker audio summarization. Theoretically, it motivates further exploration of agentic LLM architectures for sequence modeling tasks, particularly those requiring hierarchical or global-local reasoning.
Potential future research includes:
- Extension to multilingual, noisy, or low-resource speech domains
- Integration of visual/multimodal context for richer meeting understanding
- Deployment within streaming or real-time inference pipelines via optimized agentic protocols
Conclusion
Speaker-Reasoner advances the state of timestamped speaker-attributed ASR by scaling both interaction turns and temporal reasoning depth via agentic, tool-based, and cache-augmented inference. Its empirical results establish new performance standards on challenging multi-speaker benchmarks, indicating that iterative, global-to-local reasoning paradigms may be essential for next-generation end-to-end conversational speech understanding.