- The paper introduces co-optimization techniques for RISC-V processors that recover up to 2.41× speedup by tackling memory, control, and operand-delivery bottlenecks.
- It establishes an ideal multi-lane chaining model to benchmark deviations in pipeline overlap and exposes key microarchitectural inefficiencies.
- The implemented optimizations yield significant throughput gains in streaming and high-arithmetic kernels, offering practical insights for ML/AI vector processor design.
Microarchitectural Co-Optimization for Sustained Throughput of RISC-V Multi-Lane Chaining Vector Processors
Introduction
This paper presents a microarchitectural investigation into efficiency bottlenecks and improvement opportunities for RISC-V Vector Extension (RVV) processors, targeting the open-source Ara platform. While the combination of multi-lane parallelism and chaining is theoretically capable of achieving high sustained throughput, the realized performance on actual hardware is often substantially less than the architectural upper bound. This work provides a detailed microarchitectural attribution for sustained throughput losses in Ara, introduces a set of co-optimized architectural enhancements, and quantifies the achievable performance recovery relative to an idealized execution reference.
Ideal Multi-Lane Chaining Model
An ideal multi-lane chaining model is established as the microarchitectural gold standard, assuming fixed processor lane count, functional unit configuration, raw memory bandwidth, and perfect memory supply and dependency management. The execution of dependent vector instruction chains is segmented into prologue, steady-state, and tail-drain phases, with steady-state overlap expected to dominate total runtime, assuming conflict-free operand delivery and immediate dependence release. The shaded steady-state region demonstrates the concurrent execution of multiple dependent instructions across vector lanes.
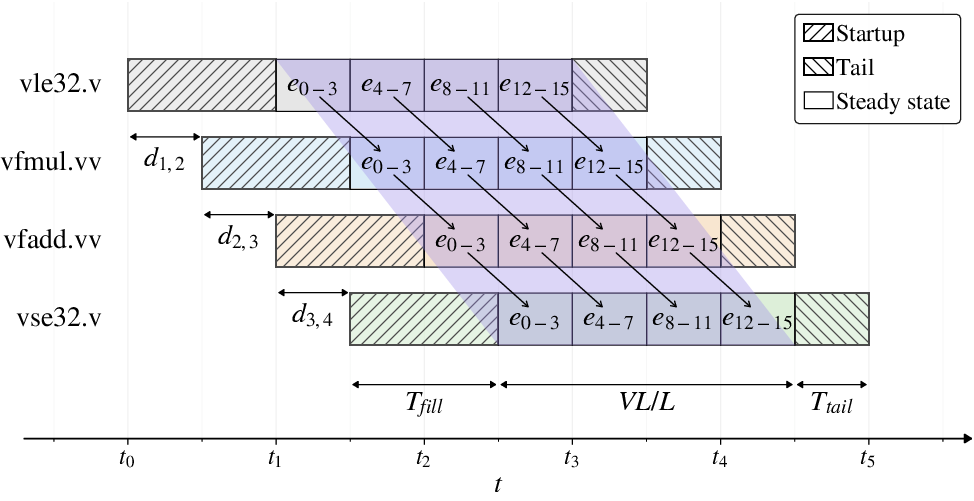
Figure 1: Execution timeline and total-execution-time decomposition for a dependent vector instruction chain under ideal multi-lane chaining, illustrating peak-throughput overlap.
This model provides a direct metric for analyzing the root causes of throughput loss by exposing deviations from ideal lane utilization, overlap, and pipeline fill/drain behavior.
Bottleneck Analysis in Ara
Sustained throughput loss in Ara is attributed to three principal classes of microarchitectural inefficiency:
- Memory-Side Inefficiency: Discontinuities in data supply arising from tightly coupled, demand-driven load delivery and inefficient transaction handling. Front-end coupling among address expansion, transaction generation, and issuance introduces pipeline stalls and bus backpressure, compounding memory-side exposure and breaking steady-state overlap.
- Control-Side Constraints: Conservative dependence management prolongs the lifespan of WAR/false dependencies, restricting timely issue of reliant instructions. Occupancy in the dependence tracking logic is released only upon full instruction completion rather than immediate operand queue readiness, unnecessarily extending blocking windows and compressing achievable overlap.
- Operand-Delivery Pathologies: Intra-lane vector register file (VRF) access conflicts and long result-propagation paths cause operand supply serialization. The absence of aggressive forwarding, combined with limited operand-queue sourcing flexibility, exacerbates propagation delays and reduces effective lane concurrency.
Microarchitectural Co-Optimization Techniques
Three coordinated microarchitectural optimizations are implemented:
- Decoupled Memory Front-End with Next-VL Prefetch: Address-expansion and transaction-control logic are restructured using descriptor-driven mechanisms, enabling fully decoupled pipeline stages and facilitating one-transaction-per-cycle issuance for vector memory streams. Next-vl prefetching leverages access regularity for preemptive data movement, isolating demand and prefetch requests via AXI IDs to sustain critical data paths and stabilize backend supply.
- Early Read-Dependence Release / Dynamic Local Issue: Read-dependence occupancy in the main sequencer is released immediately upon operand queue entry, rather than at instruction retirement. Lane-local issue logic now accounts for occupancies that can be released within the current cycle, preventing overconservative blocking and reducing pipeline bubbles.
- Forwarding-Enhanced Operand Delivery: Direct forwarding paths from multiple functional units (load, ALU, FP, mask, slide) to the operand queue, combined with a dual-source queue structure, enable immediate consumption and queuing of forwarded results, bypassing VRF re-read and reducing access contention.
Sustained Throughput Improvement
Across a collection of representative vector kernels (streaming, BLAS2/3, reduction, mixed), the optimized Ara-Opt implementation achieves a geometric-mean speedup of 1.33× over baseline Ara. Notably, scal, axpy, ger, and gemm kernels exhibit speedups of 2.41×, 1.60×, 1.52×, and 1.42×, respectively.
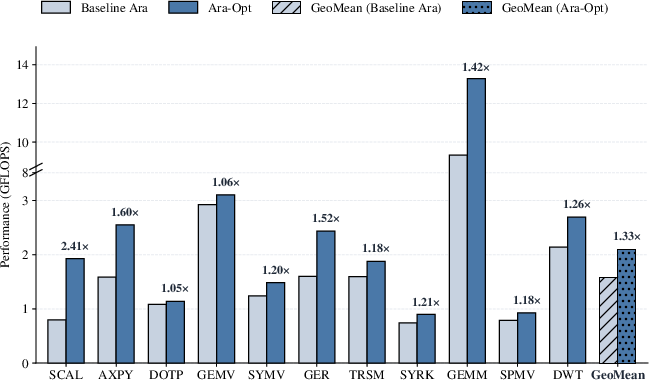
Figure 2: Achieved performance for baseline Ara and Ara-Opt across evaluated workloads, with annotated speedup factors and workload-specific problem sizes.
Using a roofline model, the proximity of Ara-Opt's realized throughput to the architectural ideal is quantitatively evaluated. Regular streaming kernels (scal, axpy, ger) move from 0.40-0.60 normalized baseline to 0.91-0.96 with Ara-Opt, marking gap-closed ratios up to 93.7%. For high-arithmetic-intensity workloads like gemm, similar trends are observed with a 59.3% gap-closed ratio.
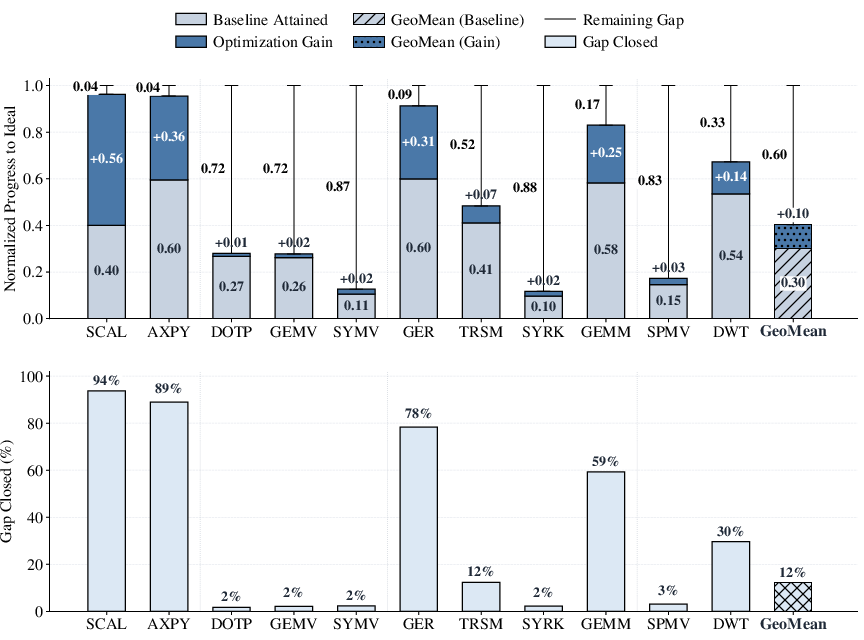
Figure 3: Normalized progress toward roofline-based ideal performance—gap-closed ratios empirically demonstrate recovery from prior inefficiencies in Ara.
The benefit's sensitivity to problem size is kernel-dependent: scal maintains stable improvement with increased vector length, while high-intensity matrix workloads exhibit diminishing returns as absolute performance approaches the upper bound.
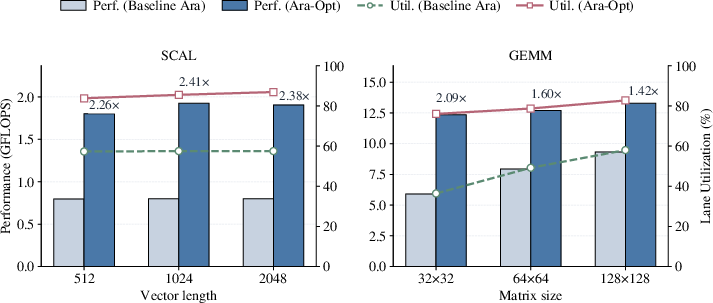
Figure 4: Problem-size sensitivity for scal and gemm—relative speedups and lane utilization as a function of vector/matrix length.
Runtime statistics indicate that for regular and high-throughput workloads, microarchitectural enhancements substantially decrease the memory-only exposure ratio (e.g., from 39.9% to 13.9% in scal), increase lane compute utilization, and reduce VRF conflict ratios (from 14.0% to 5.0% in gemm). For reduction-dominated kernels such as dotp and gemv, improvements are modest due to inherent serial dependency constraints near the reduction tail, which are not fully addressable by current optimizations.
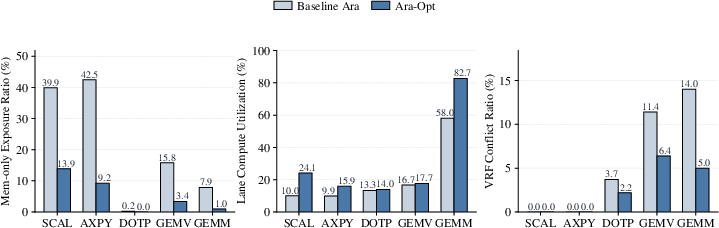
Figure 5: Runtime-statistics-based attribution—memory exposure, lane utilization, and VRF conflict metrics reveal the principal origins of performance recovery and remaining challenges for reduction-bound cases.
Implications and Future Directions
Ara-Opt demonstrates that, under fixed resource and bandwidth constraints, substantial portions of sustained-throughput deficit can be attributed to specific microarchitectural inefficiencies rather than resource ceilings. The interventions outlined—decoupled memory front-ends, timely dependency release, and operand delivery optimizations—collectively recover a substantial fraction of the gap to the ideal performance envelope for regular and high-intensity vector workloads. From a theoretical perspective, this reinforces the necessity of cross-path, execution-model-driven architecture optimization beyond naive resource scaling.
Practically, these optimizations are directly applicable to RVV-based compute engines in ML/AI platforms, where both throughput scaling and resource determinism are critical. Future architectural research should target reduction-dominated and complex memory-access workloads, where persistent serialization and irregular access patterns continue to inhibit throughput, motivating advances in reduction trees, specialized accumulators, or result-propagation paths.
Conclusion
This work provides a comprehensive microarchitectural attribution and recovery of sustained throughput loss in RVV multi-lane chaining processors. By co-optimizing the memory-side transaction pipeline, dependency management, and operand delivery, Ara-Opt achieves significant speedup—up to 2.41× for key streaming kernels and a geometric-mean gap-closed ratio of 12.2%—without increasing hardware resources or external bandwidth. These results delineate the boundary between recoverable microarchitectural inefficiency and fundamental algorithmic serialization, setting a new benchmark for efficient vector architecture design under practical constraints.