Fast GPU Linear Algebra via Compile Time Expression Fusion
Abstract: We describe the Bandicoot GPU linear algebra toolkit, a C++ based library that prioritises ease of use without compromising efficiency. Bandicoot's API is compatible with the popular Armadillo CPU linear algebra library, enabling easy transition for existing CPU-based codebases. Unlike other GPU-focused toolkits, Bandicoot uses template metaprogramming to generate fused GPU kernels directly at compile time, yielding efficient kernels that are often able to saturate memory bandwidth. This removes the need for runtime overhead or JIT infrastructure. Empirical results show that Bandicoot outperforms (sometimes by considerable margins) commonly-used linear algebra toolkits including PyTorch, TensorFlow, and JAX.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces Bandicoot, a new C++ library that makes doing big math on graphics cards (GPUs) both easy and very fast. It’s designed to feel like the popular Armadillo library (which runs on CPUs), so people can switch their existing code to run on GPUs with minimal changes. Bandicoot’s special trick is that it combines (“fuses”) many math steps into one super-efficient GPU program ahead of time, when you build your app, so there’s little extra work or waiting when you actually run it.
What questions does the paper try to answer?
- Can we make a GPU math library that’s as simple to use as Armadillo, but still extremely fast?
- Can we avoid “just-in-time” (JIT) systems that add extra startup delays and complexity during program execution?
- Will this approach beat or match the speed of popular tools like PyTorch, TensorFlow, JAX, and ArrayFire?
- Can it work across different GPU systems (like CUDA and OpenCL) without locking users to one vendor?
How did they do it? (Methods in everyday language)
Think of a math expression like a recipe: “take X, add 3, then transpose it, then multiply...” Most tools cook this recipe step by step, sending the GPU back into the kitchen for each step. That wastes time because the GPU has to keep going back and forth to memory.
Bandicoot does something different:
- It reads the whole recipe at build time (when you compile your program), and merges the steps into one big “fused” recipe. Then it creates a single special GPU program (called a “kernel”) that does everything in one go. This reduces trips to memory and speeds things up.
- It uses advanced C++ features (called “template metaprogramming”) to turn your math code into a structured “expression tree” that the compiler can reason about. From that tree, Bandicoot fills in “skeleton kernels” (simple, generic GPU code templates) with the exact instructions your expression needs.
- Because this happens at compile time, there’s no need for a JIT compiler during runtime. Your program starts quickly and runs the fused math steps directly.
To check performance, the authors:
- Tested many kinds of math expressions (like adding matrices, doing transposes, element-wise operations, and neural network activations such as ReLU, sigmoid, GELU).
- Ran each test multiple times on a powerful NVIDIA RTX 4090 GPU using CUDA.
- Measured average running time (after warm-up) and also measured how close each tool gets to the GPU’s memory “speed limit” (called memory bandwidth). You can think of this like a highway: the best you can do is drive at the speed limit; Bandicoot tries to reach that limit by doing one smooth trip.
What did they find, and why is it important?
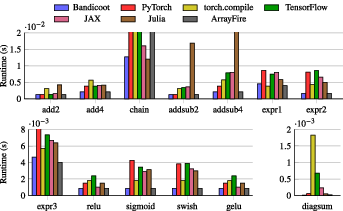
- Bandicoot was usually the fastest, or tied for fastest, across most tested expressions.
- It avoids runtime overhead because it doesn’t use JIT—so after initial GPU setup, it just runs.
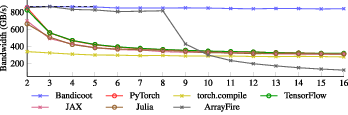
- In tests where many matrices are added together (a memory-heavy task), Bandicoot kept running near the GPU’s maximum memory speed. Other tools slowed down or had to break the work into multiple passes, which hurts performance.
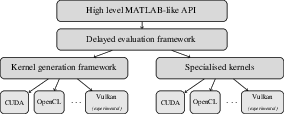
- It works with multiple backends (like CUDA and OpenCL), with more planned (HIP/ROCm, Vulkan, Apple Metal), and it supports many standard math tasks (like SVD, eigen, Cholesky).
This matters because:
- Faster math means quicker results for scientists, engineers, and machine learning practitioners.
- Doing more in one pass reduces energy use and time waiting.
- A simple, Armadillo-like interface means less new code to write and fewer bugs when switching to GPUs.
What’s the impact and what comes next?
Bandicoot shows that you can have an easy-to-use GPU library that’s also extremely fast—without extra runtime systems. That could help:
- Machine learning (training and inference),
- Large simulations (weather, physics, healthcare),
- Any workload that depends on big matrix math.
Because Bandicoot is open source (Apache 2.0), developers can adopt it widely, improve it, and use it in commercial or research projects. The team plans to add more GPU backends, support lower-precision numbers (useful for speed and memory savings in ML), and eventually match all Armadillo features. For anyone already using Armadillo, Bandicoot is close to a drop-in upgrade to GPU speed with minimal code changes.
In short: Bandicoot fuses math steps into a single GPU run, right when you build your program, so your code stays simple and your performance stays high.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of concrete gaps and open questions that remain unresolved in the paper. Each item is phrased to be directly actionable for future researchers.
- Cross-vendor validation: Evaluate correctness and performance on non-NVIDIA hardware and backends (OpenCL, Vulkan, planned HIP/ROCm, Apple Metal), including any preprocessor/macros limitations in those ecosystems.
- Backend-specific portability risks: Systematically test whether the macro-based skeleton approach maps cleanly to backends with different shading languages and compilers (e.g., Metal, Level Zero), and document required adaptations.
- Compile-time cost and scalability: Quantify C++ compile times, peak memory usage during template instantiation, and binary size as expression depth/complexity grows; identify thresholds where compilation becomes impractical.
- Kernel specialization explosion: Assess whether generating distinct kernels per expression structure causes code bloat or excessive build artifacts in large codebases; evaluate strategies for kernel reuse without losing fusion.
- First-run and driver JIT overhead: Measure and report the latency of GPU driver compilation of embedded kernels on first use, caching behavior across runs, and the impact on latency-sensitive workloads.
- Numerical accuracy/determinism: Analyze how fused evaluation order affects floating-point rounding, reproducibility, and compliance with IEEE-754 across devices; provide error bounds relative to BLAS/cuBLAS baselines.
- Precision and accelerator usage: Implement and benchmark FP64, FP16, bfloat16, and TF32 (including mixed-precision accumulation), and quantify utilization of tensor cores vs standard CUDA cores.
- Sparse linear algebra on GPU: Clarify current support for sparse matrices and expression fusion with sparse operands (spMV, spMM), and benchmark against cuSPARSE/oneMKL for irregular access patterns.
- Decompositions and solvers: Provide coverage and performance comparisons for SVD, eigen, QR, LU, and Cholesky on GPU; define when Bandicoot fuses around vendor libraries (e.g., MAGMA/cuSOLVER) versus calls out, and the performance trade-offs.
- Autotuning and launch configuration: Describe and/or implement autotuning for block/thread sizes, tiling, shared memory usage, and occupancy; quantify sensitivity across problem sizes and architectures.
- Fusion limits beyond elementwise ops: Specify which reductions (e.g., sum, norm), scans, gathers/scatters, and conditional/control-flow patterns can be fused; provide benchmarks and fallback behavior when fusion is not feasible.
- Dynamic shapes and runtime polymorphism: Investigate robustness and code-size impact when the same expression executes over many runtime-varying shapes; study kernel caching/reuse keyed by shape/stride metadata.
- Memory management and transfers: Detail strategies for minimizing host–device transfers (pinned/unified memory, zero-copy), overlapping communication with compute (streams), and provide APIs for user control.
- Out-of-core operation: Explore tiling/streaming methods to operate on matrices exceeding device memory, with correctness and performance results.
- Multi-GPU scaling: Define and evaluate mechanisms for partitioning/fusing expressions across multiple GPUs, interconnect utilization (NVLink vs PCIe), and integration with MPI/distributed runtimes.
- Small/batched/tall-skinny regimes: Extend benchmarks beyond 10k×10k squares to small/medium sizes, tall-skinny/fat matrices, and batched microkernels typical in DL and scientific workloads.
- End-to-end benchmarks: Include total application time (data movement, warmup, graph construction), not just steady-state kernel time; compare against PyTorch/TensorFlow/JAX in modes that enable their best fusions (e.g., torch.compile, XLA, graph mode).
- Benchmark reproducibility: Release scripts, exact versions, build flags, and environment details; correct or clarify the matrix size/storage claim (10k×10k float32 is ~0.4 GB, not ~384 GB) to avoid confusion.
- Energy efficiency: Measure power and report GFLOPS/W or GB/s/W to assess practical efficiency vs competitors under equivalent conditions.
- Debugging and observability: Provide tooling to inspect generated kernels, map runtime errors back to source expressions, and profile hotspots; document recommended workflows for performance diagnosis.
- API coverage map: Publish a precise matrix of Armadillo operations currently unsupported on GPU, with migration alternatives and prioritization timelines.
- Interoperability and language bindings: Assess and document zero-copy interop with external buffers/layouts (row-major, strided, subviews), and plan Python/R/Julia bindings to broaden adoption.
- Autodiff integration: Explore automatic differentiation for fused GPU expressions (forward/reverse mode), including gradient kernel fusion and compatibility with ML ecosystems.
- Deterministic modes: Provide options for deterministic reductions and well-defined operation ordering to satisfy reproducibility requirements in scientific and ML workflows.
- Safety and limits of macro codegen: Stress-test macro depth/identifier limits, name collision risks, and preprocessor edge cases; codify guardrails and static checks in the build system.
- Heuristics for fusion vs library calls: Identify cases where fusing is counterproductive (e.g., cache reuse across multiple passes, specialized GEMM kernels) and design heuristics to choose the optimal strategy automatically.
Practical Applications
Immediate Applications
The paper introduces Bandicoot, a C++ GPU linear algebra toolkit that fuses expressions into single, specialized GPU kernels at compile time (no JIT), with an API matching Armadillo. This enables low-overhead, high-throughput GPU acceleration with minimal code changes. The following use cases are deployable now:
- Drop-in GPU acceleration for Armadillo-based C++ codebases
- Sectors: scientific computing (astrophysics, CFD, weather), engineering, healthcare, finance, telecommunications
- Workflow: replace
#include <armadillo>with Bandicoot headers and usecoot::*types (e.g.,coot::fmat), prefer matrix-level operations, compile with CUDA or OpenCL backend; benefit from automatic compile-time kernel fusion for compound expressions - Potential tools/products: “Bandicoot-enabled” builds of existing C++ applications; GPU-accelerated numerical services
- Assumptions/dependencies: GPU availability with supported backend (CUDA or OpenCL); not all Armadillo ops are implemented yet; best performance requires vectorized/matrix-level code (avoid scalar element access across CPU–GPU)
- Custom high-performance ML and numerical kernels without JIT overhead
- Sectors: machine learning (inference and custom training loops), MLOps, streaming analytics
- Workflow: implement pre/post-processing, custom activations (e.g., ReLU, GELU, Swish), and non-standard operators as vectorized expressions; deploy as C++ microservices with predictable startup and low runtime overhead
- Potential tools/products: low-latency inference services; GPU-accelerated feature engineering modules
- Assumptions/dependencies: ML training still needs higher-level tooling if required (Bandicoot is not a DL framework); ensure kernels fit device memory; integration code must manage data transfer to/from GPU efficiently
- Real-time and embedded systems with deterministic latency and low overhead
- Sectors: robotics, aerospace, automotive (ADAS), industrial automation
- Workflow: leverage compile-time fused kernels to avoid runtime JIT; use asynchronous GPU dispatch to overlap computation with host tasks; improve reliability in air-gapped or safety-critical deployments where dynamic compilation is undesirable
- Potential tools/products: onboard perception/control modules; guidance and optimization loops relying on fast linear algebra
- Assumptions/dependencies: GPU presence (e.g., NVIDIA embedded with CUDA or vendor GPUs with OpenCL); memory bandwidth and capacity constraints must be respected; C++ toolchain configuration for target
- Cost and efficiency optimization in cloud/on-prem analytics
- Sectors: cloud computing, SaaS analytics, HPC centers
- Workflow: exploit memory-bandwidth–saturating fused kernels to reduce GPU-hours; avoid JIT warm-up penalties to cut cold-start latency; ship single static binaries with embedded kernels for simpler containerization
- Potential tools/products: containerized analytics services; batch ETL jobs with GPU-accelerated linear algebra transforms
- Assumptions/dependencies: engineering teams comfortable with C++; data movement between CPU and GPU minimized; OpenCL driver quality may vary by vendor
- Risk analytics and Monte Carlo pipelines
- Sectors: finance, insurance
- Workflow: port large-scale covariance, scenario aggregation, and factor model computations to fused Bandicoot expressions; benefit from high throughput in element-wise and reduction-heavy workloads
- Potential tools/products: GPU-accelerated portfolio risk engines; scenario simulation services
- Assumptions/dependencies: numerical stability with chosen precision; careful batching to fit GPU memory; validate results against CPU baselines
- Medical imaging and computational biology workloads
- Sectors: healthcare, life sciences
- Workflow: accelerate reconstruction, registration, or dimensionality-reduction steps (e.g., SVD/eigendecompositions when supported); use fused expressions for pre/post-processing chains
- Potential tools/products: GPU-accelerated imaging toolkits; genomics preprocessing libraries
- Assumptions/dependencies: confirm required decompositions/factorizations are implemented; where missing, integrate with external libraries (e.g., MAGMA) until Bandicoot support lands; comply with domain-specific validation
- Vendor-agnostic GPU deployment via OpenCL
- Sectors: enterprise IT, HPC, multi-vendor fleets
- Workflow: build with OpenCL backend to target non-NVIDIA GPUs; reduce vendor lock-in for large deployments
- Potential tools/products: cross-vendor GPU build configurations; hybrid cloud portability
- Assumptions/dependencies: OpenCL driver maturity and performance; performance may lag best-in-class vendor runtimes
- Education and training in GPU programming and high-performance linear algebra
- Sectors: higher education, professional training
- Workflow: teach GPU fundamentals and template metaprogramming via a MATLAB-like C++ API; demonstrate expression fusion and memory-bound optimization in practice
- Potential tools/products: course modules and lab exercises; benchmarking suites
- Assumptions/dependencies: access to GPUs and suitable compilers; students familiar with C++ basics
- Security- and compliance-sensitive deployments (no runtime code generation)
- Sectors: defense, finance, healthcare, government IT
- Workflow: deploy AOT-compiled kernels to simplify code audit and reduce attack surface versus JIT systems; operate reliably in restricted or offline environments
- Potential tools/products: auditable numerical services for regulated environments
- Assumptions/dependencies: GPU driver still performs final machine-code compilation for the embedded kernel source; ensure deployment policies accept this driver-level step
- Academic benchmarking and compiler research
- Sectors: academia (HPC, compilers, PL)
- Workflow: use Bandicoot as a reference to study compile-time AST transformations, kernel fusion limits, and memory bandwidth saturation on real hardware
- Potential tools/products: performance studies, teaching materials, and reproducible benchmarks
- Assumptions/dependencies: access to comparable GPU stacks (CUDA, OpenCL) for fair comparisons
Long-Term Applications
These opportunities depend on ongoing development (new backends, broader operation coverage, precision support) or further ecosystem integration:
- Cross-vendor and cross-platform ubiquity (HIP/ROCm, Apple Metal, mature Vulkan)
- Sectors: enterprise IT, mobile/desktop apps, HPC
- Workflow: “write once, run anywhere” GPU linear algebra with consistent performance across NVIDIA, AMD, Intel, and Apple devices
- Potential tools/products: portable scientific applications; enterprise-standard GPU math layers
- Assumptions/dependencies: completion and optimization of non-CUDA backends; performance parity and thorough testing across vendors
- Low-precision and mixed-precision compute for efficiency
- Sectors: ML inference, energy-efficient computing, edge AI
- Workflow: native FP16/BF16/INT8 fused kernels for faster, lower-power inference; quantization-aware operator chains
- Potential tools/products: energy-efficient inference runtimes; edge-deployable numerical kernels
- Assumptions/dependencies: numerical stability and error control; hardware support for low-precision math; additional kernels and validation
- Full Armadillo-operation coverage (factorizations, decompositions, sparse ops)
- Sectors: scientific computing, engineering simulation
- Workflow: complete GPU-based replacement for CPU Armadillo workflows, including robust SVD/eigen/Cholesky and hybrid sparse matrices
- Potential tools/products: turn-key GPU ports of existing scientific codes; generalized solver stacks
- Assumptions/dependencies: porting of advanced routines (some via MAGMA) and extensive correctness/performance testing; API parity maintenance
- High-level language bindings with AOT performance (Python, R, Julia)
- Sectors: data science, academia, enterprise analytics
- Workflow: build Python/R/Julia extensions that wrap precompiled Bandicoot kernels, avoiding runtime JIT while offering idiomatic APIs
- Potential tools/products: pyBandicoot via pybind11; RcppBandicoot; Julia packages
- Assumptions/dependencies: stable C++ API, packaging for manylinux/macOS/Windows, ecosystem adoption
- Integration into existing libraries and ecosystems (e.g., mlpack, ensmallen, RcppArmadillo-like)
- Sectors: ML, optimization, statistics
- Workflow: make these libraries GPU-aware by swapping Armadillo backends for Bandicoot types or providing optional GPU builds
- Potential tools/products: GPU-accelerated versions of mlpack/ensmallen; Armadillo-compatible GPU backends for R
- Assumptions/dependencies: maintainers’ bandwidth and interest; ensuring sufficient operation coverage and stable ABI
- Static analyzers and IDE tooling to maximize fusion opportunities
- Sectors: developer tools, HPC engineering
- Workflow: code advisors that flag non-fusible patterns (e.g., excessive scalar indexing) and suggest vectorized rewrites to enable single-pass kernels
- Potential tools/products: compiler plugins; IDE extensions for performance hints
- Assumptions/dependencies: deeper analysis of AST transformations; integration with CMake/Clang tooling
- Domain-specific libraries on top of Bandicoot (signal processing, graph analytics, time series)
- Sectors: telecom, cybersecurity, quantitative finance
- Workflow: express domain algorithms as linear-algebraic pipelines to exploit compile-time fused kernels
- Potential tools/products: GPU-accelerated DSP libraries; graph-LA toolkits (e.g., Laplacian-based methods)
- Assumptions/dependencies: algorithm engineering for matrix-centric formulations; community-maintained packages
- Edge and consumer deployments via Metal/Vulkan
- Sectors: AR/VR, mobile apps, desktop creative tools
- Workflow: leverage portable backends to accelerate numerical features on laptops/mobile devices without CUDA
- Potential tools/products: on-device analytics and creative filters with low startup overhead
- Assumptions/dependencies: mature, well-optimized Metal/Vulkan backends; power/thermal limits on mobile hardware
- Policy and procurement to reduce vendor lock-in in public-sector/HPC acquisitions
- Sectors: government, research infrastructure
- Workflow: use permissive, multi-backend libraries as baseline requirements for funded software; promote portability and longevity
- Potential tools/products: procurement guidelines; reference architectures
- Assumptions/dependencies: sustained community support and demonstrable cross-vendor performance
- Platform-level serverless and orchestration integration for predictable cold starts
- Sectors: cloud providers, enterprise IT
- Workflow: integrate ahead-of-time compiled GPU math services into serverless runtimes to guarantee low cold-start latency and predictable scaling
- Potential tools/products: serverless GPU functions; autoscaling policies tailored to AOT GPU workloads
- Assumptions/dependencies: cloud platform support for GPU serverless; standardization of packaging and driver behaviors
- Automatic DSL-to-Bandicoot compilers for specialized workflows
- Sectors: EDA, scientific pipelines, financial modeling
- Workflow: high-level DSLs transpiled to C++/Bandicoot to generate specialized fused kernels at build time
- Potential tools/products: domain DSLs with AOT performance
- Assumptions/dependencies: DSL design and compiler infrastructure; stability of Bandicoot’s expression AST model
Notes on general feasibility across applications:
- Performance and fusion benefits are maximized when expressions are written at matrix level with minimal CPU–GPU element-wise traffic.
- GPU memory capacity and bandwidth remain primary constraints; batching/tiling strategies may be required.
- Build toolchains must target the chosen backend (e.g., NVCC for CUDA) and include appropriate drivers; initial driver-level compilation of embedded kernels still occurs at load time.
- Current backend maturity: CUDA and OpenCL are usable now; Vulkan is experimental; HIP/ROCm and Metal are in development.
Glossary
- Abstract Syntax Tree (AST): A tree-structured representation of the syntactic structure of an expression used for analysis and optimization. "In essence, the C++ type of an expression is the Abstract Syntax Tree (AST)~\cite{Harper_2016} of that expression, and the use of template specialisations allows the compiler to optimise that AST."
- Apple Metal: Apple’s low-level GPU programming framework for macOS/iOS platforms. "Bandicoot supports multiple GPU backends, including CUDA and OpenCL, with further backends like Vulkan, HIP/ROCm, and Apple Metal under active development."
- ArrayFire: A C++ GPU computing library that provides high-level array operations and a JIT engine. "This is unique, as even other C++ GPU linear algebra toolkits like ArrayFire~\cite{Malcolm_2012} do not contain a template metaprogramming framework for expression optimisation."
- C-like macros: Preprocessor macros with C-style syntax used to generate or specialize code at compile time. "The approach relies on the use of {\it skeleton kernels} and C-like macros, which are supported in some form by every GPU vendor's low-level toolkits."
- Cholesky: A matrix factorization of a positive-definite matrix into a product of a lower triangular matrix and its transpose. "As the library is not focused simply on numerical linear algebra for machine learning, support is provided for various decompositions and factorisations, such as SVD, eigen, Cholesky, etc."
- cuBLAS: NVIDIA’s GPU-accelerated Basic Linear Algebra Subprograms (BLAS) library. "At the low level, vendor-specific toolkits such as CUDA or cuBLAS can be used, with each vendor typically supplying its own device-family-specific offering (e.g. HIP/ROCm, OneAPI, etc)."
- CUDA: NVIDIA’s parallel computing platform and programming model for GPUs. "Our test setup used an NVIDIA RTX 4090 GPU, with the CUDA backend used for each toolkit."
- embarrassingly parallel: Computations that can be easily separated into parallel tasks with minimal or no dependence between them. "For instance, embarrassingly parallel linear algebra operations like the element-wise Schur product can be performed trivially, with one thread assigned to compute each element of ."
- fused GPU kernels: Single GPU kernels that combine multiple operations to reduce memory traffic and overhead. "Unlike other GPU-focused toolkits, Bandicoot uses template metaprogramming to generate fused GPU kernels directly at {\it compile time}, yielding efficient kernels that are often able to saturate memory bandwidth."
- GPU backends: Pluggable low-level GPU execution targets supported by a library (e.g., CUDA, OpenCL). "Bandicoot supports multiple GPU backends, including CUDA and OpenCL, with further backends like Vulkan, HIP/ROCm, and Apple Metal under active development."
- GPU synchronisation: Coordination points that ensure previous GPU operations have completed before proceeding. "GPU synchronisation is only performed when necessary (e.g. within the {\small \tt X.print()} function), or when explicitly specified via the {\small \tt coot_synchronise()} function."
- HIP/ROCm: AMD’s GPU programming environment (HIP language) and platform (ROCm) analogous to CUDA. "Bandicoot supports multiple GPU backends, including CUDA and OpenCL, with further backends like Vulkan, HIP/ROCm, and Apple Metal under active development."
- JAX: A Python library for high-performance numerical computing and automatic differentiation with JIT compilation. "Furthermore, sometimes add-ons like {\small \tt torch.compile}~\cite{Ansel_2024} or JAX~\cite{Frostig_2018} are required to analyse linear algebra expressions and select or generate optimised GPU kernels via a just-in-time (JIT) compilation approach."
- just-in-time (JIT) compilation: Runtime compilation of code to generate specialized machine code just before execution. "Furthermore, sometimes add-ons like {\small \tt torch.compile}~\cite{Ansel_2024} or JAX~\cite{Frostig_2018} are required to analyse linear algebra expressions and select or generate optimised GPU kernels via a just-in-time (JIT) compilation approach."
- MAGMA: A high-performance linear algebra library targeting heterogeneous architectures (CPU+GPU). "Although not all Armadillo operations are yet implemented in Bandicoot, work is ongoing for that, including porting factorisations from MAGMA~\cite{Abdelfattah_2024}."
- memory bandwidth: The rate at which data can be read from or written to memory; a key performance limiter for memory-bound kernels. "Bandicoot's API is compatible with the popular Armadillo CPU linear algebra library, enabling easy transition for existing CPU-based codebases. Unlike other GPU-focused toolkits, Bandicoot uses template metaprogramming to generate fused GPU kernels directly at {\it compile time}, yielding efficient kernels that are often able to saturate memory bandwidth."
- memory-bound: A characteristic of computations whose performance is limited primarily by memory access speed rather than compute. "This is a memory-bound operation, and thus we can easily compute the peak possible bandwidth."
- OneAPI: Intel’s cross-architecture programming model for CPUs, GPUs, and other accelerators. "At the low level, vendor-specific toolkits such as CUDA or cuBLAS can be used, with each vendor typically supplying its own device-family-specific offering (e.g. HIP/ROCm, OneAPI, etc)."
- OpenCL: An open standard for cross-platform parallel programming of diverse processors including GPUs. "Bandicoot supports multiple GPU backends, including CUDA and OpenCL, with further backends like Vulkan, HIP/ROCm, and Apple Metal under active development."
- Schur product: Element-wise multiplication of two matrices of the same dimensions. "For instance, embarrassingly parallel linear algebra operations like the element-wise Schur product can be performed trivially, with one thread assigned to compute each element of ."
- single-instruction-multiple-threads (SIMT): A GPU execution model where many threads execute the same instruction on different data simultaneously. "GPUs are built on the idea of {\em single-instruction-multiple-threads} (SIMT) and thus are particularly well-suited for linear algebra tasks, where identical or similar computations are often performed over many matrix elements."
- skeleton kernels: Template kernel “recipes” with placeholders, filled in at compile time to produce specialized GPU kernels. "Each {skeleton kernel} is a deliberately straightforward recipe for a kernel that uses placeholders to represent its inputs and outputs."
- SVD: Singular Value Decomposition, a matrix factorization into singular vectors and singular values. "As the library is not focused simply on numerical linear algebra for machine learning, support is provided for various decompositions and factorisations, such as SVD, eigen, Cholesky, etc."
- template metaprogramming: A C++ technique that computes or generates code at compile time using templates. "Unlike other GPU-focused toolkits, Bandicoot uses template metaprogramming to generate fused GPU kernels directly at {\it compile time}, yielding efficient kernels that are often able to saturate memory bandwidth."
- template specialisation: Providing custom implementations for specific template parameter combinations to optimize or alter behavior. "This is accomplished by automatically collecting (at compile time) the structure of a linear algebra expression as an elaborate custom type, and then using techniques such as template specialisation~\cite{Vandevoorde_2017} to generate efficient code to evaluate the expression."
- Vulkan: A low-overhead, cross-platform 3D graphics and compute API. "Internal architecture and design of Bandicoot. High-level user code is converted to efficient, fused GPU kernels at program compilation time, not at runtime. Vulkan backend support is currently experimental; more backends (e.g. HIP/ROCm) are~planned."
- vendor-specific toolkits: GPU programming stacks tied to a specific hardware vendor’s ecosystem. "At the low level, vendor-specific toolkits such as CUDA or cuBLAS can be used, with each vendor typically supplying its own device-family-specific offering (e.g. HIP/ROCm, OneAPI, etc)."
Collections
Sign up for free to add this paper to one or more collections.