mlx-vis: GPU-Accelerated Dimensionality Reduction and Visualization on Apple Silicon
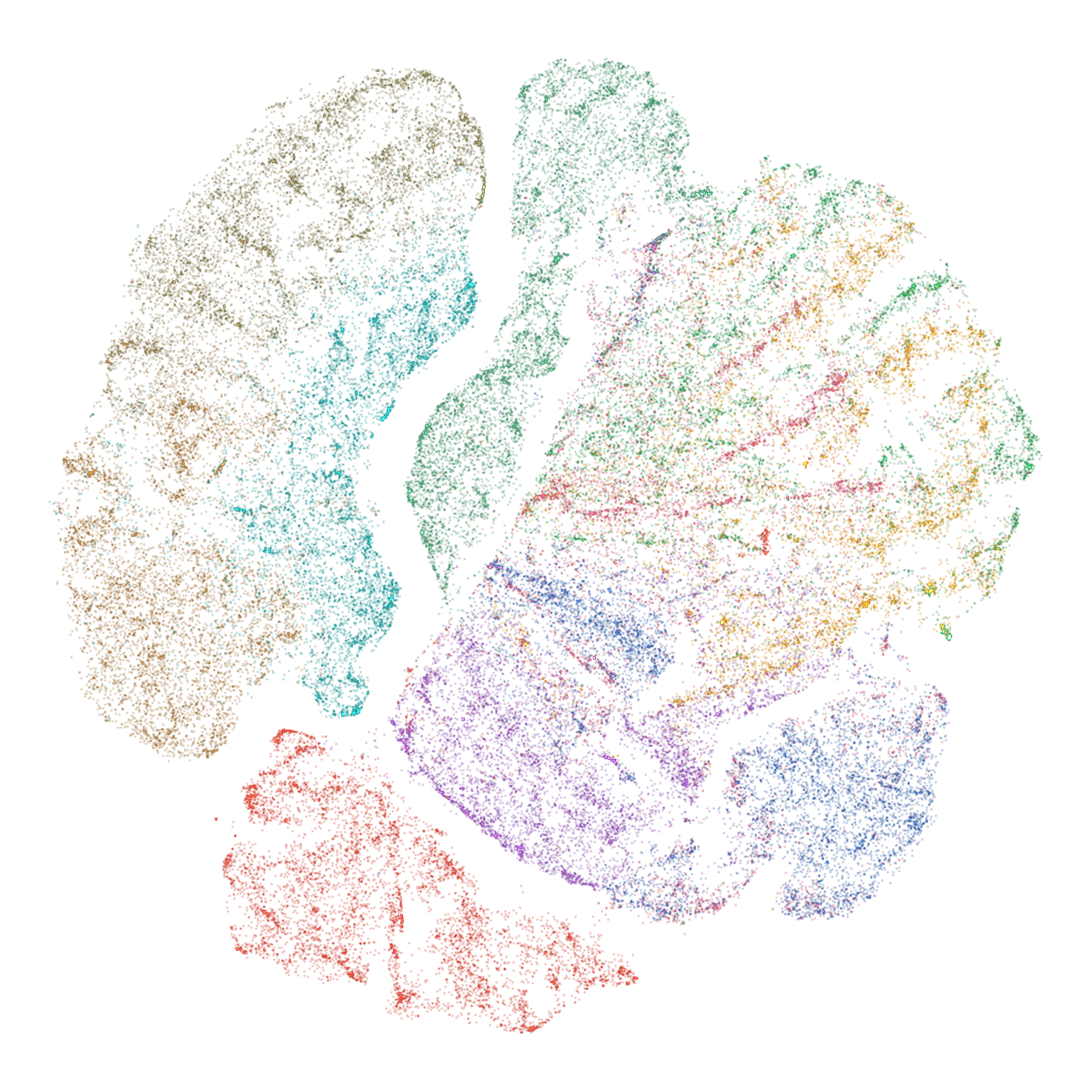
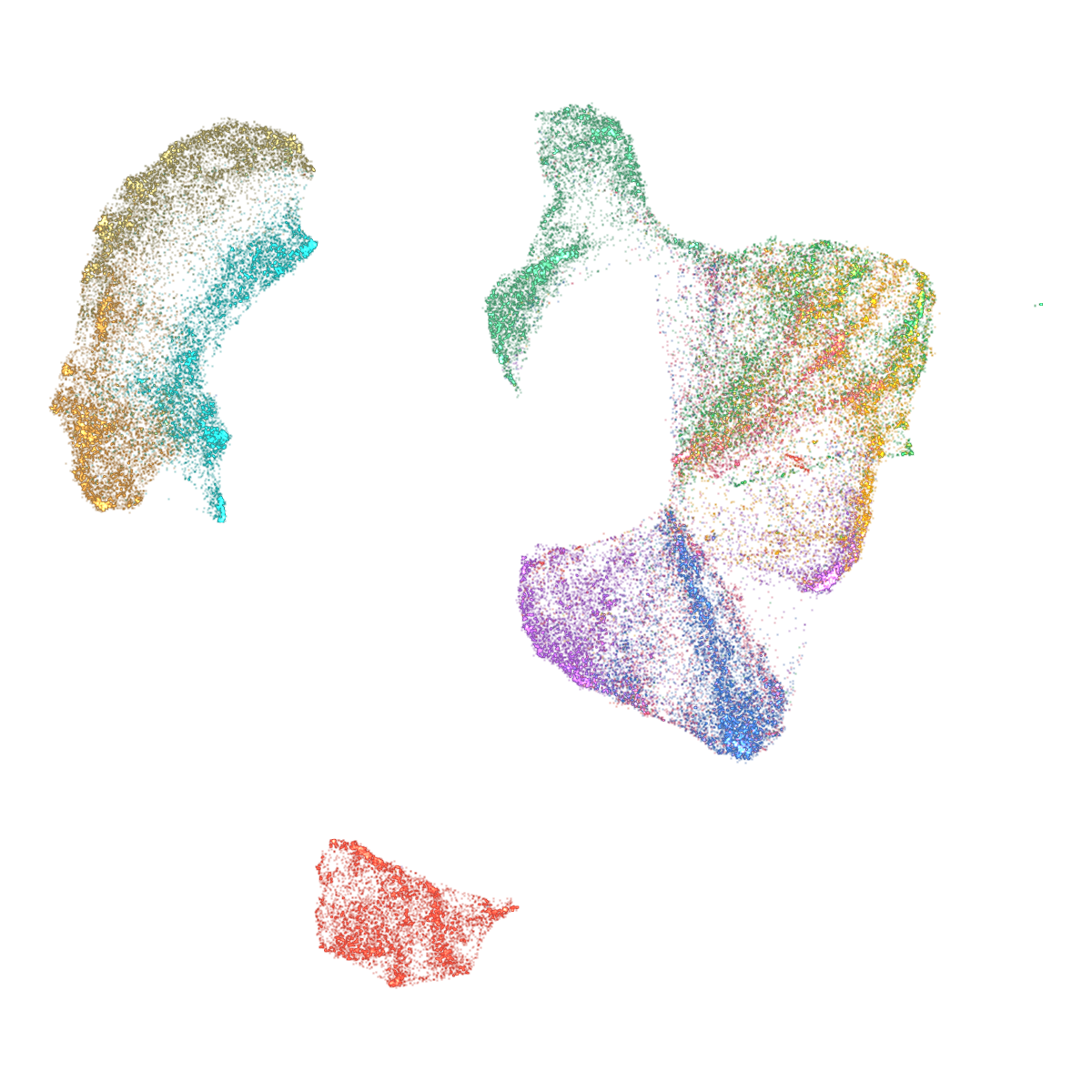
Abstract: mlx-vis is a Python library that implements six dimensionality reduction methods and a k-nearest neighbor graph algorithm entirely in MLX, Apple's array framework for Apple Silicon. The library provides UMAP, t-SNE, PaCMAP, TriMap, DREAMS, CNE, and NNDescent, all executing on Metal GPU through a unified fit_transform interface. Beyond embedding computation, mlx-vis includes a GPU-accelerated circle-splatting renderer that produces scatter plots and smooth animations without matplotlib, composing frames via scatter-add alpha blending on GPU and piping them to hardware H.264 encoding. On Fashion-MNIST with 70,000 points, all methods complete embedding in 2.1-3.8 seconds and render 800-frame animations in 1.4 seconds on an M3 Ultra, with the full pipeline from raw data to rendered video finishing in 3.6-5.2 seconds. The library depends only on MLX and NumPy, is released under the Apache 2.0 license, and is available at https://github.com/hanxiao/mlx-vis.
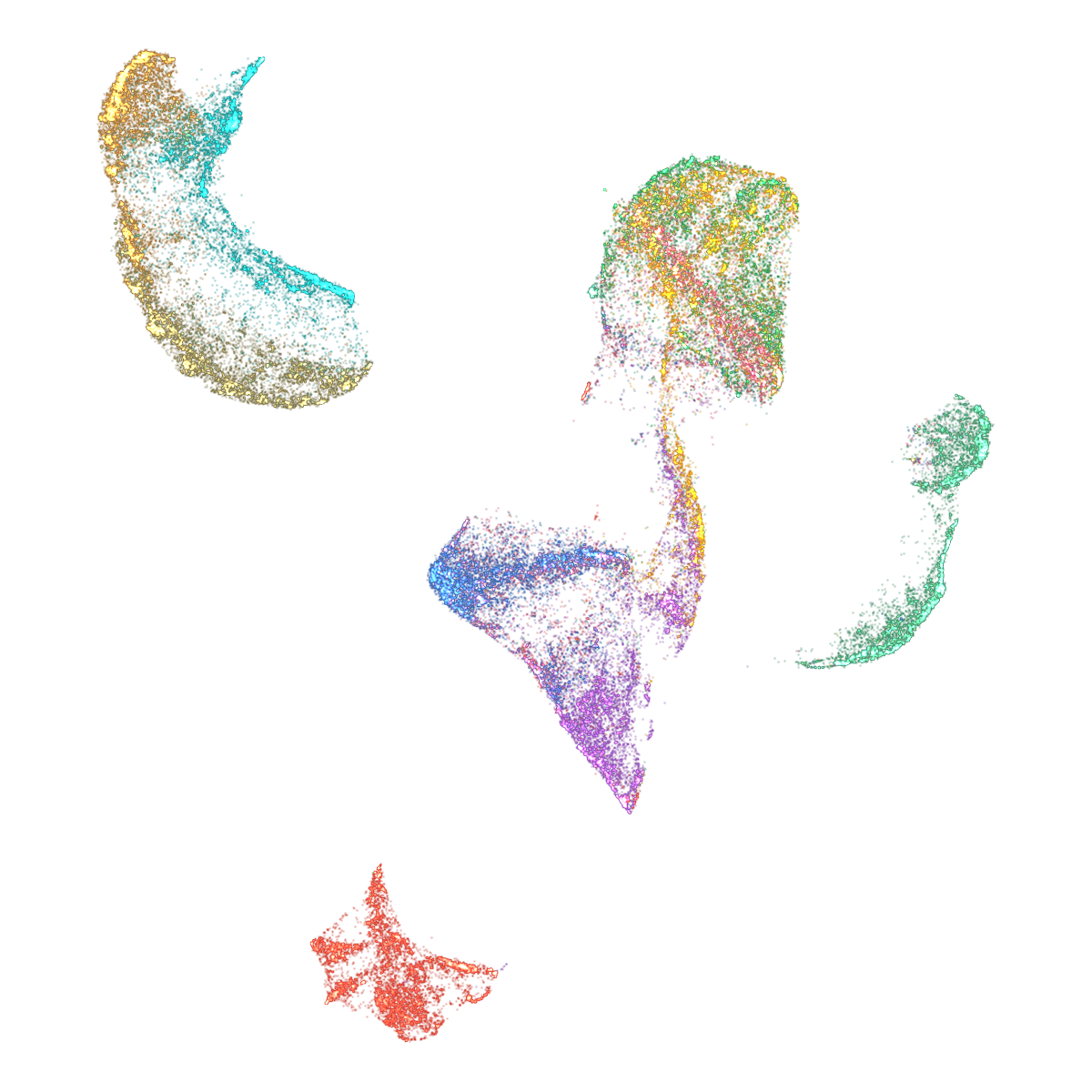

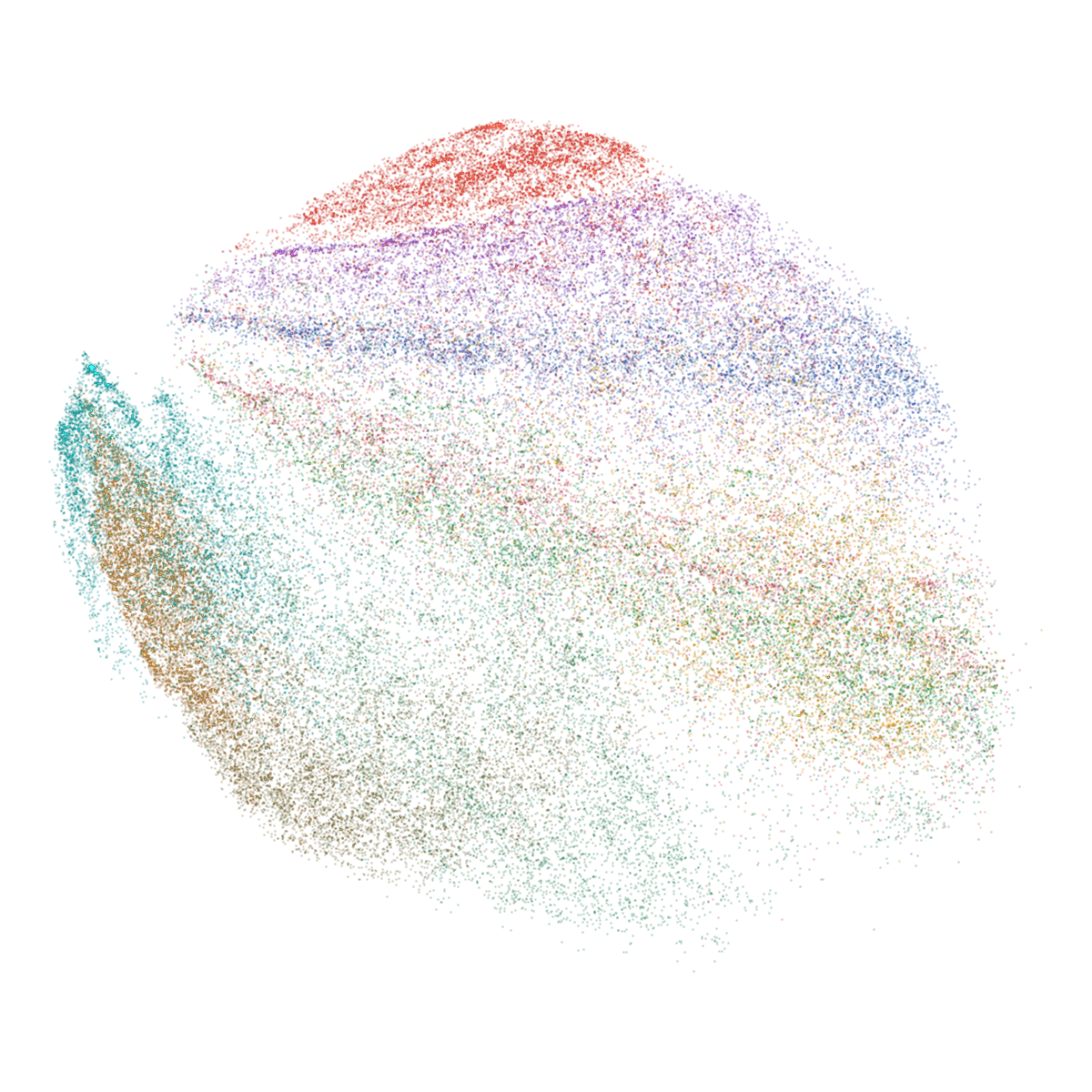

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces mlx-vis, a fast, easy-to-use Python library that turns big, complex datasets into simple 2D pictures you can look at—like making a “map” of your data. It runs entirely on the GPU (the graphics chip) inside modern Apple computers (Apple Silicon), using Apple’s MLX framework. It not only calculates these maps quickly, but also draws smooth animations of how the map forms—in just a few seconds.
What questions did the researchers ask?
The paper focuses on two main questions:
- Can we bring several popular “dimensionality reduction” methods together into one simple library that runs fast on Apple GPUs?
- Can we also make the drawing and animation part GPU-fast, so you get a complete pipeline from raw data to video without slowdowns?
“Dimensionality reduction” means taking data with many features (like 784 numbers per image) and shrinking it down to two numbers per item (x and y), so you can plot it on a 2D graph and see patterns—like clusters of similar items.
How did they do it?
They built mlx-vis, which includes six well-known ways to make these 2D maps and one fast way to find nearest neighbors. Everything runs on the GPU using MLX, Apple’s array library that talks directly to the Metal graphics system.
Here’s the idea in everyday terms:
- Finding nearest neighbors: Imagine every data point is a person, and you want to connect each person to their k closest friends. mlx-vis uses an algorithm called NNDescent to do this quickly on the GPU.
- Building the 2D map: Different methods arrange the points in 2D so that friends stay near each other and different groups spread apart. mlx-vis includes:
- UMAP and t-SNE: Try to keep close neighbors together (great for seeing clusters).
- PaCMAP and TriMap: Balance local detail and the big-picture layout.
- DREAMS: Blends ideas so you keep local detail and overall structure.
- CNE: Uses contrastive learning (think “pull similar together, push different apart”).
All of these follow the original research, just written to run on the GPU.
- Drawing fast on the GPU: Instead of using usual Python plotting tools, mlx-vis “stamps” small soft circles for each point directly on the GPU—like dabbing paint dots that blend smoothly. It then streams the frames straight into a video (MP4) using the Mac’s built-in hardware video encoder. This makes animations very fast.
- Unified memory and MLX: On Apple Silicon, the CPU and GPU share the same memory, so data doesn’t have to be copied back and forth. MLX also compiles hot parts of the code so the GPU does more work in fewer steps.
What did they find?
- Speed: On a standard dataset with 70,000 images (Fashion-MNIST), all six methods finish the 2D mapping in about 2.1 to 3.8 seconds on an Apple M3 Ultra. Making an 800-frame animation takes about 1.4 seconds. From start (raw data) to finish (video) takes roughly 3.6 to 5.2 seconds.
- Faster than popular tools: Compared to well-known CPU-based libraries on the same machine, mlx-vis was:
- About 2.6× faster than a popular UMAP package
- About 15.5× faster than a popular t-SNE package
- About 3.1× faster than a PaCMAP package
- About 6.0× faster than a TriMap package
- Quality: The 2D maps look similar to the results from the original tools, because mlx-vis sticks to the same formulas and training schedules—just runs them on the GPU.
- Simplicity: The library depends only on MLX and NumPy, so it’s lightweight and easy to install. You can call a single function (fit_transform) to get your 2D map, and another (animate_gpu) to make a video.
Why does this matter?
- Faster exploration: When you can turn big datasets into 2D maps and animations in seconds, you can explore ideas interactively instead of waiting minutes or hours. That’s great for students, researchers, and anyone working with lots of data.
- All-in-one, GPU-native pipeline: Many existing tools compute on the CPU and draw plots separately. mlx-vis does both on the GPU, taking full advantage of Apple Silicon’s shared memory and hardware video encoding.
- Accessible and open: It’s open-source (Apache 2.0), uses minimal dependencies, and works well on modern Macs. This lowers the barrier to making high-quality visualizations and sharing results.
In short, mlx-vis makes it fast and simple to see patterns in large, complex data on Apple computers—turning “numbers you can’t picture” into “maps you can explore” in just a few seconds.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and open questions that the paper leaves unresolved, organized with short category tags for clarity.
- [Scope/Platform] No support beyond Apple Silicon/Metal/MLX; portability to NVIDIA (CUDA), AMD, or CPU-only backends is unaddressed.
- [Scale] Scalability beyond 70K points is not evaluated; limits, throughput, and memory behavior at 1M–10M+ points (for both embedding and rendering) are unknown.
- [Memory] Peak and per-stage memory footprint (NNDescent graph, FFT grids, optimizer state, render buffers) are not reported; behavior on low-memory machines (e.g., 8–16 GB) is unexplored.
- [Datasets] Benchmarks use only Fashion-MNIST; performance and quality on diverse modalities (e.g., single-cell RNA-seq, text embeddings, images with higher d, sparse/tabular data) are missing.
- [Quality Metrics] No quantitative embedding-quality evaluation (e.g., trustworthiness/continuity, KNN preservation/recall, MRRE, neighborhood hit rate, global structure metrics) to substantiate “comparable quality.”
- [NNDescent Accuracy] NNDescent recall/precision vs exact KNN is not measured; the impact of the early-termination threshold δ=0.001 and k on downstream embedding quality/time is unknown.
- [Distance Metrics] Current NNDescent distance uses a matrix-multiplication identity specific to Euclidean distance; support, performance, and quality for other metrics (cosine, correlation, mahalanobis, Jaccard, precomputed) are not addressed.
- [Sparse Data] No support or evaluation for sparse high-dimensional inputs (e.g., CSR/COO); feasibility of sparse kernels in MLX and effects on speed/quality are open.
- [t-SNE FFT Details] FIt-SNE-like FFT parameters (grid size, interpolation order, kernel bandwidth) and their accuracy–speed trade-offs versus Barnes–Hut/exact forces are not reported.
- [UMAP Kernel Fitting] The Gauss–Newton replacement for SciPy curve fitting in UMAP is not validated for equivalence, stability, or sensitivity; effects on embedding quality and convergence are unclear.
- [Method Fidelity] DREAMS and CNE have no reference baselines; correctness beyond visual inspection (e.g., on synthetic ground-truth manifolds) is not demonstrated.
- [Hyperparameters] Exact hyperparameter choices (perplexity, k, learning rates, negative sampling, early exaggeration, PaCMAP/TriMap schedules) are not fully specified; no sensitivity or robustness analysis across settings/datasets.
- [Determinism] Reproducibility controls (random seeds, deterministic kernels) are not discussed; GPU atomics (in renderer) and NNDescent randomness may introduce nondeterminism.
- [Numerical Precision] Dtypes (fp32/fp16/bfloat16), mixed precision, and their effects on quality, speed, and stability are not characterized; no guidance on precision choices per method.
- [Convergence] Convergence criteria and diagnostics (loss curves, step size schedules, stopping rules) are not exposed or evaluated; default iteration counts may be suboptimal across datasets.
- [Out-of-sample] No transform()/inverse_transform() for out-of-sample embedding (e.g., UMAP’s supervised/transform mode); streaming/online updates and partial_fit are not supported.
- [Preprocessing] PCA preprocessing details (variance target vs fixed components, whitening, scaling/normalization) and their effects on downstream methods are unspecified.
- [Integration] Lack of scikit-learn-compatible API patterns (Pipeline/Estimator interface), model serialization/checkpointing, and parameter validation may limit adoption and reproducibility.
- [Baselines] Comparisons exclude GPU baselines on other platforms (e.g., RAPIDS cuML UMAP/t-SNE); cross-vendor performance/quality positioning remains unknown.
- [Unified Memory Benefit] The claimed benefit of unified memory is not quantified via ablations (e.g., profiling dispatch overhead, data movement, kernel fusion efficacy).
- [Renderer Scale/Quality] Rendering complexity and contention under atomic scatter-add as n, radius R, and resolution grow are not characterized; quality aspects (aliasing, density saturation, color management, HDR) are unexplored.
- [Interactivity] Despite animation speed, interactive features (pan/zoom, selection, tooltips, LOD strategies) and latency budgets are not implemented or evaluated.
- [Video Encoding] Only H.264 via VideoToolbox is used; support and performance/quality for HEVC/ProRes/AV1, color spaces, and reproducible encoding settings are not assessed.
- [Energy/Thermals] Power consumption, thermals, and throttling under sustained GPU load (notably on laptops) are unmeasured; efficiency vs CPU baselines is unknown.
- [Robustness] Behavior on edge cases (duplicated points, extreme class imbalance, NaNs/Infs, degenerate manifolds) and error handling are not documented.
- [Algorithmic Variants] Extensions to excluded families (PHATE/diffusion maps, MDS/eigendecomposition-heavy methods, StarMAP) and feasibility of implementing required linear algebra in MLX remain open.
- [Multi-GPU/Chip] Utilization of multiple GPU tiles/NPUs on M3 Ultra, and potential multi-process or distributed strategies, are not discussed.
- [Ablations] No ablation studies on @mx.compile placements, lazy-eval barriers, or kernel fusion to pinpoint where speedups originate and how to generalize them.
- [Validation Suite] There is no automated correctness/quality regression suite comparing against canonical implementations across datasets and metrics.
These gaps suggest concrete avenues for future work: broaden hardware and method coverage, add quantitative quality and resource profiling, improve determinism and API completeness (including out-of-sample transforms), support diverse metrics and sparse data, and rigorously evaluate scalability, rendering performance, and interactivity.
Practical Applications
Immediate Applications
Below are concrete ways practitioners can use the library today, tied to sectors and typical workflows, along with key dependencies and assumptions.
- Accelerated exploratory data analysis on Macs — software/data science
- Use case: Quickly create 2D embeddings (UMAP, t-SNE, PaCMAP, TriMap, DREAMS, CNE) of high‑dimensional tabular/image/text embeddings for clustering, continuity, and outlier assessment.
- Workflow/product: Replace umap-learn/openTSNE/pacmap/trimap calls with
mlx_vis.<Method>.fit_transform(X); render withscatter_gpuoranimate_gputo produce publication-ready figures/videos in seconds. - Dependencies/assumptions: Apple Silicon (M-series), macOS with Metal; MLX and NumPy installed; data fits in unified memory; performance numbers reflect an M3 Ultra.
- Embedding debugging and model evaluation — software/ML engineering
- Use case: Inspect and compare embedding spaces from language/image encoders (e.g., LLM token embeddings, CLIP features) across training checkpoints or model variants.
- Workflow/product: Add an epoch callback during encoder training to snapshot embeddings and generate 800‑frame MP4s showing cluster formation; integrate into notebooks or CI reports.
- Dependencies/assumptions: Epoch snapshotting requires access to intermediate embeddings; assumes local Mac development environment.
- Drift monitoring and reporting in MLOps — software/ops
- Use case: Detect shifts in production embedding distributions by visual comparison over time.
- Workflow/product: A lightweight “Embedding Report” step in CI/CD that runs mlx‑vis on sampled production vs. reference embeddings, saving side-by-side MP4s for weekly drift dashboards.
- Dependencies/assumptions: Access to sampled embeddings; reproducible preprocessing; Apple Silicon runners (e.g., Mac minis) for CI.
- Single‑cell and bioinformatics EDA on Mac workstations — healthcare/life sciences
- Use case: Fast UMAP/t‑SNE visualization of scRNA‑seq (or other omics) embeddings for batch effect checks, trajectory exploration, and cell type annotation.
- Workflow/product: Substitute
umap-learncalls in local Scanpy-style notebooks with mlx‑vis UMAP/t‑SNE; export animations to communicate trajectory stabilization and parameter sensitivity. - Dependencies/assumptions: Data preprocessed to manageable size per session; Apple Silicon hardware; method parity is algorithmic but domain-specific metrics should be validated.
- Customer/user segmentation and marketing analytics — retail/media/finance
- Use case: Rapidly explore customer embeddings (behavioral/features) to identify clusters and outliers for campaigns or personalization.
- Workflow/product: Data analyst runs mlx‑vis in a Mac-based notebook; exports plots/animations for stakeholder decks in under a minute.
- Dependencies/assumptions: Secure local data access; embeddings precomputed or computed locally; team hardware is Apple Silicon.
- Cybersecurity and log triage — security/IT operations
- Use case: Visual cluster/outlier scanning of high-dimensional event/log embeddings to speed incident triage.
- Workflow/product: SOC analyst notebooks generate quick embeddings and animations per day’s logs; share MP4s for shift handover.
- Dependencies/assumptions: Data sampling to fit memory; local secured Macs; qualitative visualization complements, not replaces, detectors.
- Computer vision feature-space inspection — robotics/vision
- Use case: Validate feature separability for image/patch embeddings or multi-sensor embeddings during model development.
- Workflow/product: Integrate mlx‑vis into training scripts to produce per-epoch short videos for rapid qualitative feedback.
- Dependencies/assumptions: Intermediate embeddings available; Apple Silicon dev machines.
- Classroom demos and teaching materials — education
- Use case: Live demonstrations of how different DR methods and hyperparameters affect structure (local/global) and convergence.
- Workflow/product: In-class notebook uses
epoch_callbackandanimate_gputo show optimization dynamics; students replicate on their MacBooks. - Dependencies/assumptions: Students/instructors use Apple Silicon; MLX installed; small/medium datasets.
- Rapid figure/animation generation for publications and media — academia/communications
- Use case: Produce high-quality scatter plots and smooth animations without matplotlib, using GPU-native rendering and hardware H.264.
- Workflow/product: A “figure factory” script that loads embeddings, uses
scatter_gpu/animate_gpu, and outputs PNG/MP4 assets for papers or talks. - Dependencies/assumptions: ffmpeg available; style customization currently within mlx‑vis renderer’s options.
- Local, privacy-preserving analytics — cross-sector
- Use case: Keep sensitive datasets on-device while still enabling rich EDA due to fast runtimes.
- Workflow/product: Analysts explore embeddings locally on secured Macs; videos shared internally without moving raw data off device.
- Dependencies/assumptions: Organizational policy allows local Mac processing; device disk encryption and access controls in place.
Long-Term Applications
The following opportunities build on the paper’s methods and architecture but require additional research, engineering, or platform expansion.
- Real-time/streaming DR for interactive dashboards — software/analytics
- Vision: Incremental UMAP/t‑SNE variants and streaming k‑NN enable live embeddings of data feeds (e.g., telemetry, social, fraud alerts) with GPU rendering.
- Needed: Incremental/online DR algorithms in MLX; buffering, windowing, and latency controls; UI link (e.g., WebGPU or native macOS app).
- Scaling to millions of points and multi-GPU/distributed — big data/biotech
- Vision: Out-of-core NNDescent, tiling, and hierarchical multi-resolution embeddings for very large datasets (e.g., multi-million single-cell profiles).
- Needed: Memory-aware batching, approximate/global refinement schemes, multi-GPU Metal or distributed compute; renderer tiling; empirical quality studies at scale.
- Cross-platform GPU backends — broader industry adoption
- Vision: CUDA/ROCm/WebGPU/Vulkan backends so Linux/Windows users achieve similar performance; browser-side visualization via WebGPU.
- Needed: Backend abstraction of MLX-specific kernels or portability layers; fidelity and performance parity benchmarks.
- General-purpose GPU plotting library built on circle-splatting — software/visualization
- Vision: Extend the GPU-native renderer into a broader macOS plotting toolkit (dense scatter, heatmaps, point clouds) and integrate with notebooks/IDEs.
- Needed: Broader API, styling/theming, text/legend rendering on GPU, interactivity (pan/zoom/pick), export formats.
- Vector database and embedding store tooling — software/data platforms
- Vision: A “Embedding Inspector” plugin for vector DBs (e.g., used in RAG systems) that periodically snapshots and visualizes collection structure and drift.
- Needed: Connectors to popular stores, sampling strategies, secure on-prem Mac services or cross-platform GPU backend.
- Clinical and hospital analytics — healthcare
- Vision: Near-real-time embedding of patient features (labs, vitals, imaging-derived encodings) for cohorting and anomaly flagging at the point of care.
- Needed: Validation under regulatory frameworks, robust interpretability, strict privacy controls, reliability engineering for clinical uptime.
- On-device mobile/iPad analytics apps — enterprise/mobile
- Vision: Port MLX/renderer to iOS/iPadOS for field teams to explore embeddings offline with Metal acceleration.
- Needed: iOS packaging, touch-first UI, energy profiling, on-device data handling policies.
- AR/VR “manifold tours” and immersive analytics — media/UX/research
- Vision: 3D+ temporal embedding experiences for exploratory analysis and presentations.
- Needed: 3D DR extensions, real-time GPU kernels for navigation, integration with ARKit/RealityKit.
- Energy-aware, green analytics policies — policy/IT procurement
- Vision: Shorter runtimes and on-device processing may reduce energy use and cloud egress; organizations could encourage Apple Silicon analytics nodes for secure, efficient EDA.
- Needed: Rigorous energy and cost benchmarking across hardware; guidance documents and best practices.
- DR-as-a-service on Apple Silicon fleets — cloud/on-prem
- Vision: Internal microservices that accept high-dimensional arrays and return embeddings/MP4s at low latency using racks of Mac minis/Mac Studios.
- Needed: Serverization, concurrency management, autoscaling, observability, and SLAs; queueing and GPU scheduling.
- Methodological expansion and evaluation — academia
- Vision: Add diffusion-based methods (e.g., PHATE), 3D embeddings, and new contrastive/hybrid objectives with GPU-native primitives; standardized benchmarks leveraging the unified API.
- Needed: New GPU kernels (e.g., fast MDS/diffusion ops), faithful implementations, quality metrics across domains.
Notes on feasibility dependencies across long-term items:
- Hardware: Current implementation is tied to Apple Silicon and Metal via MLX; broader deployment depends on backend portability.
- Algorithms: Streaming, very-large-scale, and 3D use cases require algorithmic advances, not just engineering.
- Compliance: Healthcare and sensitive domains require validation, governance, and audit trails beyond the library’s scope.
Glossary
- approximate -nearest neighbor search: Fast heuristic method to build neighbor relations without exact distances for all pairs. "Approximate -nearest neighbor search is the first stage of every method."
- Apple Silicon: Apple’s ARM-based system-on-chip architecture with unified CPU–GPU memory. "MLX, Apple's array framework for Apple Silicon."
- atomic scatter-add: A GPU operation that atomically adds values to scattered indices to avoid race conditions. "an atomic scatter-add on GPU."
- circle-splatting renderer: A point rendering technique that draws each sample as a small disk (“splat”) to produce dense scatter plots. "the library implements a circle-splatting renderer in MLX"
- CNE: A contrastive-learning-based neighbor embedding method unifying t-SNE and UMAP perspectives. "CNE unifies neighbor embedding under contrastive learning."
- contrastive learning: Representation-learning framework that pulls similar points together and pushes dissimilar ones apart. "CNE unifies neighbor embedding under contrastive learning."
- contrastive loss: A loss function used in contrastive learning to enforce similarities and dissimilarities. "CNE extracts each contrastive loss into a compiled static method for operator fusion."
- Datashader: A large-scale data visualization library for rasterizing big point clouds. "Unlike general-purpose tools such as Datashader, this renderer is purpose-built for embedding animation."
- diffusion potentials: Quantities derived from diffusion processes to capture manifold or trajectory structures. "PHATE, which captures trajectory structure through diffusion potentials,"
- double-buffering: Using two buffers to overlap rendering and I/O for higher throughput. "A double-buffering scheme overlaps GPU rendering with I/O,"
- DREAMS: A dimensionality reduction method that hybridizes t-SNE with PCA-based regularization. "DREAMS hybridizes t-SNE with PCA regularization,"
- epoch_callback: API hook called each iteration/epoch to expose intermediate embeddings (e.g., for animation). "An epoch_callback parameter accepts a function that receives the current embedding as a NumPy array at each iteration,"
- ffmpeg: A multimedia framework used here to encode generated frames into video. "Frames are piped to ffmpeg with h264_videotoolbox hardware encoding."
- FIt-SNE: A fast interpolation-based acceleration of t-SNE’s repulsive forces using FFTs. "t-SNE provides an FFT-accelerated repulsive force variant following FIt-SNE"
- framebuffer: A GPU memory buffer that accumulates rendered pixel values before final compositing. "are accumulated into a framebuffer via mx.array.at[idx].add(vals),"
- fused GPU kernel: A single compiled kernel that combines multiple operations to reduce overhead and memory traffic. "JIT-compiles a pure function into a fused GPU kernel."
- Gauss-Newton optimization: A second-order method for nonlinear least squares used to fit UMAP’s output kernel parameters. "UMAP fits its output kernel parameters via Gauss-Newton optimization rather than scipy curve fitting;"
- h264_videotoolbox: Apple’s hardware-accelerated H.264 encoding backend used by ffmpeg. "Frames are piped to ffmpeg with h264_videotoolbox hardware encoding."
- H.264 encoding: A widely used video compression standard employed for fast MP4 generation. "piping them to hardware H.264 encoding."
- hold frames: An animation optimization where identical frames are reused to avoid redundant rendering. "hold frames reuse a single rendered buffer;"
- JIT compilation: Just-in-time compilation that compiles code paths at runtime for performance. "JIT compilation via @mx.compile,"
- -nearest neighbor graph algorithm: Constructs a graph connecting each point to its closest neighbors. "a -nearest neighbor graph algorithm"
- lazy evaluation: Deferring computation until results are needed to enable graph optimizations. "Lazy evaluation."
- matrix exponentiation: Computing a matrix power or matrix exponential (costly in diffusion-based DR methods). "Diffusion-based methods like PHATE require matrix exponentiation and MDS,"
- MDS: Multidimensional scaling, a classical technique for embedding by preserving pairwise distances. "Diffusion-based methods like PHATE require matrix exponentiation and MDS,"
- Metal: Apple’s low-level GPU API analogous to CUDA, used as the backend for MLX. "Metal, Apple's low-level GPU API analogous to CUDA,"
- MLX: Apple’s NumPy-like array framework that targets Metal GPUs with lazy execution and JIT. "MLX, Apple's array framework for Apple Silicon."
- mx.argpartition: MLX API for partial ordering to select top- elements efficiently. "Top- selection uses mx.argpartition to avoid full sorting,"
- mx.async_eval(): MLX API to initiate asynchronous execution, enabling overlap of computation with I/O. "mx.async_eval() overlaps GPU rendering of frame with I/O of frame ;"
- neighbor embedding: A family of DR methods that preserve local neighborhood relationships in the low-dimensional space. "preserve local neighborhoods through neighbor embedding,"
- NNDescent: An approximate nearest neighbor graph construction algorithm based on neighbor-of-neighbor exploration. "mlx-vis implements NNDescent~\citep{dong2011nndescent} entirely in MLX."
- PaCMAP: A dimensionality reduction method that balances local and global structure via staged objectives. "PaCMAP~\citep{wang2021pacmap} and TriMap~\citep{amid2019trimap} use triplet-based objectives to balance local and global structure,"
- PCA regularization: Using principal components to guide or constrain an embedding to preserve global structure. "DREAMS hybridizes t-SNE with PCA regularization,"
- PHATE: A diffusion-based dimensionality reduction method emphasizing trajectories and transitions. "PHATE~\citep{moon2019phate}, which captures trajectory structure through diffusion potentials,"
- premultiplied color: Representing color channels already multiplied by alpha to enable correct blending. "premultiplied color contributions are accumulated into a framebuffer"
- repulsive force: In t-SNE-like methods, the term pushing dissimilar points apart to prevent crowding. "an FFT-accelerated repulsive force variant"
- scatter-add alpha blending: Blending technique accumulating per-pixel contributions via scatter-add operations. "composing frames via scatter-add alpha blending on GPU"
- SGD (stochastic gradient descent): Iterative optimization method updating parameters using random mini-batches. "applies this to UMAP's SGD step,"
- StarMAP: A DR method that modifies UMAP with PCA centroid attraction to improve global faithfulness. "StarMAP~\citep{watanabe2025starmap}, which adds PCA centroid attraction to UMAP."
- t-SNE: A neighbor-embedding DR method focusing on preserving local structure with attractive/repulsive forces. "t-SNE provides an FFT-accelerated repulsive force variant following FIt-SNE"
- top- selection: Selecting the best elements without fully sorting the entire array. "Top- selection uses mx.argpartition to avoid full sorting,"
- TriMap: A triplet-based DR method designed for large-scale embeddings. "PaCMAP~\citep{wang2021pacmap} and TriMap~\citep{amid2019trimap} use triplet-based objectives to balance local and global structure,"
- triplet-based objectives: Losses using anchor–positive–negative triplets to balance local and global structure. "use triplet-based objectives to balance local and global structure,"
- UMAP: A manifold-learning-based DR method optimizing a fuzzy topological graph in low dimensions. "UMAP fits its output kernel parameters via Gauss-Newton optimization rather than scipy curve fitting;"
- unified memory: A shared memory architecture between CPU and GPU that avoids data transfer overheads. "unified memory access that eliminates CPU-GPU data transfers."
Collections
Sign up for free to add this paper to one or more collections.

