- The paper introduces a diagnostic framework using plasticity/stability profiles and Boundary-Profile Sensitivity (BPS) to quantify the impact of taskification.
- It empirically shows that different segmentation windows (9-, 30-, and 44-day) significantly affect forecasting error, forgetting, and backward transfer metrics.
- The findings underscore the necessity of treating temporal taskification as a key evaluation variable to build more robust continual learning benchmarks.
Temporal Taskification in Streaming Continual Learning: Implications for Evaluation Instability
Introduction
"Temporal Taskification in Streaming Continual Learning: A Source of Evaluation Instability" (2604.21930) systematically interrogates the assumption that temporal partitioning of continuous data streams into discrete tasks is an innocuous preprocessing step in streaming continual learning (CL). By treating temporal taskification itself as a structural variable, the authors expose its pronounced impact on plasticity/stability profiles, downstream continual learning performance metrics (e.g., MSE, Forgetting, Backward Transfer), and overall benchmark robustness. The work presents a diagnostic framework—prior to any model training—rooted in information-theoretic profile distances and introduces Boundary-Profile Sensitivity (BPS) as a quantitative metric of taskification robustness to local boundary perturbations.
Theoretical Framework: Plasticity, Stability, and Taskification
A central contribution is the abstraction from task-indexed views of continual learning to representations invariant to the number and boundaries of tasks. The framework constructs:
- Plasticity Profile: The empirical distribution of discrepancies (e.g., Wasserstein distance) between adjacent task-level distributions, summarizing the typicality and severity of local distributional shifts induced by taskification.
- Stability Profile: The empirical distribution of discrepancies between distant (non-adjacent) task pairs, probing the long-range recurrence and regime regularity within the induced task sequence.
From these, a profile distance metric, Dprof, is defined to compute the structural similarity between any pair of taskifications, operationalized as a function of distributional distances between their respective plasticity and stability profiles. This quantifies, model-free, whether different taskification choices induce genuinely distinct CL regimes.
Boundary-profile sensitivity (BPS) further assesses the expected change in profile distance when task boundaries are randomly perturbed within a local neighborhood. High BPS signals that CL conclusions are structurally sensitive to minor, arbitrary differences in task boundary alignment, often occurring near abrupt changepoints, narrow transients, or phase-sensitive recurrences.
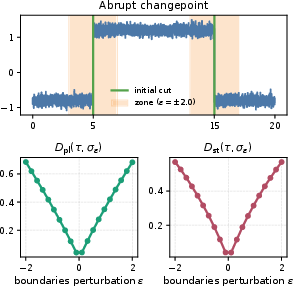
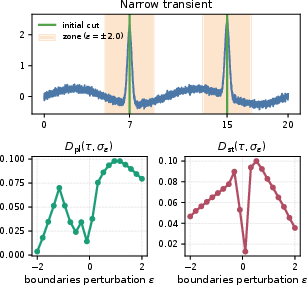
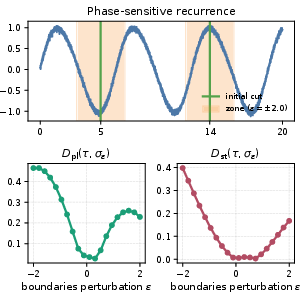
Figure 1: A minor boundary movement across a changepoint can produce a large jump in adjacent-task discrepancy and, thus, plasticity profile.
Experimental Analysis
The empirical study employs the CESNET-Timeseries24 network traffic dataset, segmenting the continuous stream into 9-day, 30-day, and 44-day window-based taskifications. All variables downstream—dataset, model architecture (Transformer), and resource budget—are held fixed to isolate the effect of only the taskification. These partitions capture different temporal structures and frequency components present in the underlying stream.
The top row of Figure 2 presents pairwise Wasserstein distances between the induced tasks for each split. The 9-day segmentation reveals highly irregular and noisy inter-task transitions, contrasting with the smoother, more regular transitions observed in 30-day and 44-day splits. The bottom row quantitatively compares the distance matrices, demonstrating that 30-day and 44-day taskifications are structurally more similar to each other than either is to the more fine-grained 9-day partition; the latter introduces greater fragmentation of regimes.
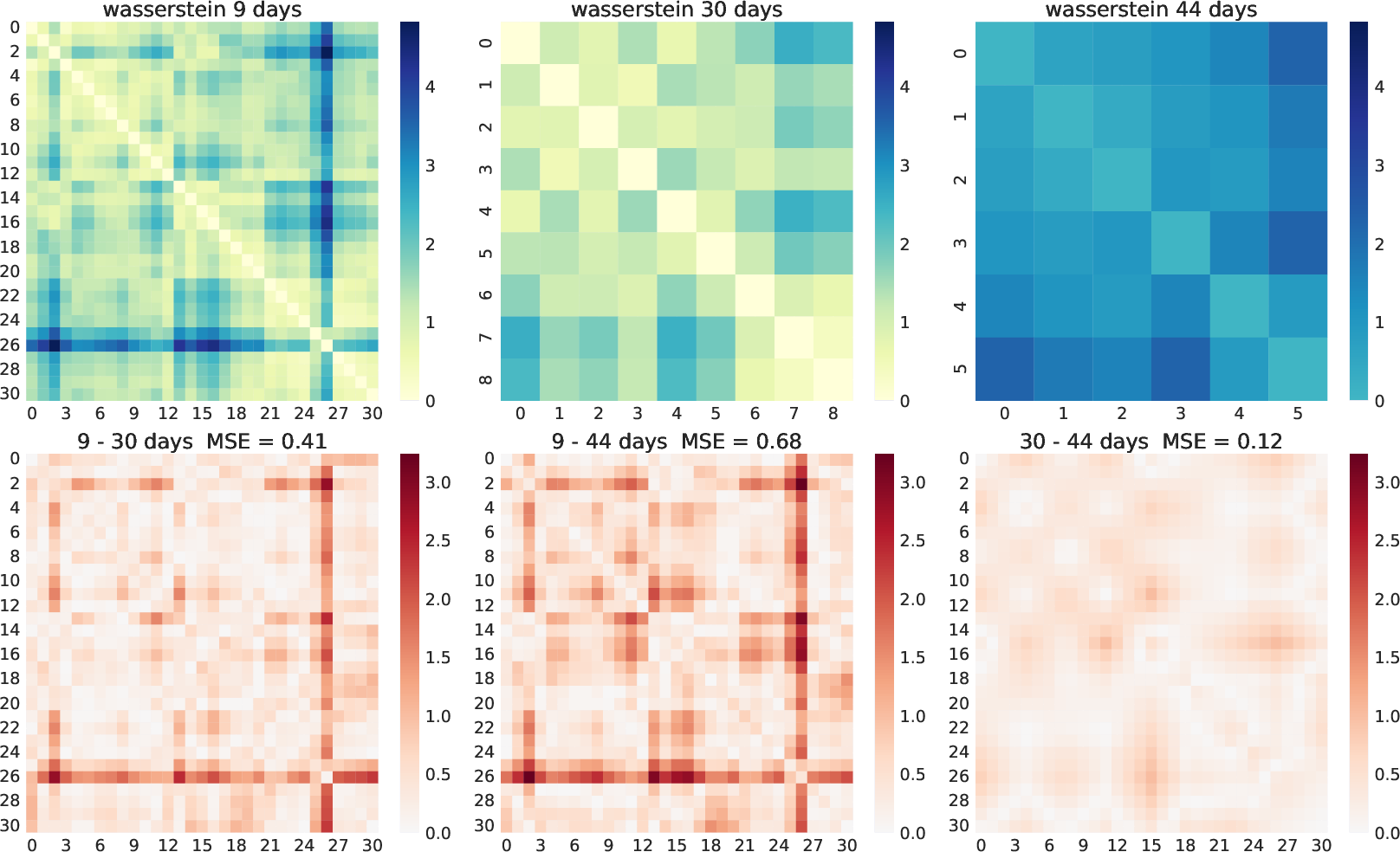
Figure 2: Wasserstein distance matrices for the 9-, 30-, and 44-day taskifications (top); MSE comparisons and corresponding absolute differences (bottom) evidence structural divergence between splits.
Downstream, classical CL algorithms (Finetune, ER, EWC, LwF) are evaluated on all splits. Performance metrics (average MSE, Forgetting, Backward Transfer) exhibit substantial sensitivity to taskification. For instance, the 30-day split consistently achieves lower forecasting error and more stable transfer than the 9-day or 44-day variants; the 44-day split often degrades performance and increases metric variance across runs. This evidences that the difficulty and regime structure of CL evaluation is materially altered by partitioning choice—a split with shorter windows may fragment natural regimes, while a longer window can aggregate over multiple, distinct shifts.
Profile distance computations are consistent with these observations: splits differing more in window length yield larger profile distances, indicating more distinct CL regimes prior to training. BPS is highest in the 9-day setup, indicating that short-window taskifications are structurally fragile to minor boundary perturbations.
Implications for Continual Learning Evaluation
The results demonstrate that taskification is not a neutral axis of CL benchmark construction. Modest changes in window size or alignment—often determined ad hoc—can shift observed trends in forgetting, transfer, or MSE. Thus, claims about a method's stability-plasticity trade-off, robustness, or suitability for streaming environments are contingent not only on architecture or optimization, but critically on the (often unexamined) particulars of how streams are partitioned.
This dependence is problematic for comparative benchmarking. Two model families run on identically sampled underlying streams, but partitioned with different windows (or with different boundary phase alignments), may yield divergent conclusions about relative merit, even though the underlying data-generating process is unchanged.
The methodological recommendation is to treat taskification as a first-class evaluation variable. The diagnostic framework—profile distributions and BPS—supports the identification of robust splits and the quantification of bench-marking fragility. Pre-training assessment of a taskification’s sensitivity can guide the construction of more reliable and defensible benchmarks.
Prospects for Future Research
Potential follow-on work is abundant. The generalization of profile-based diagnostics to adaptive, data-driven, or distribution-aware segmentation procedures is immediate. Furthermore, the design of CL algorithms inherently robust to taskification variability, or even invariant to explicit task boundaries (task-free CL), is a critical step toward more realistic streaming learning settings. Incorporating taskification sensitivity into hyperparameter search, protocol design, or as a regularizer during architecture selection could mitigate benchmark lottery effects and enhance reproducibility.
Extending these diagnostics to diverse real-world domains—beyond network traffic to sensor data, finance, or industrial settings—will inform whether the observed magnitudes and mechanisms of taskification sensitivity generalize. Moreover, there is a need to investigate interactions between dataset attributes (seasonality, abruptness, recurrence) and choice of profile metrics (Wasserstein vs. other divergences) for even more precise quantification.
Conclusion
The paper establishes, both theoretically and empirically, that temporal taskification is a fundamental and under-scrutinized source of evaluation variability in streaming continual learning (2604.21930). The proposed framework makes this dependence explicit through taskification-invariant profiles and BPS, demonstrating that benchmark conclusions—such as the efficacy of a given continual learning algorithm—are not solely properties of the dataset and methods but are also contingent on arbitrary choices in how streams are temporally partitioned. As the field moves toward streaming, task-agnostic, and more robust CL paradigms, explicit handling and reporting of taskification parameters, and adoption of pre-training diagnostic metrics, is essential for advancing both theoretical and applied continual learning research.