- The paper demonstrates that fine-tuning regimes act as subspace-constrained optimizations that directly influence continual learning performance.
- The study shows that method ranking and forgetting rates vary significantly with the adaptation depth, highlighting regime-dependent plasticity and stability trade-offs.
- Empirical evaluations using ResNet-18 across multiple benchmarks confirm that controlling trainable parameters is crucial for reproducible continual learning comparisons.
Fine-Tuning Regimes as a Determinant of Continual Learning Evaluation
Introduction
The work titled "Fine-Tuning Regimes Define Distinct Continual Learning Problems" (2604.21927) critically assesses the assumption that continual learning (CL) method comparisons are stable across different fine-tuning conditions. The research formalizes trainable parameter subsets as projectors onto subspaces, demonstrating that adaptation regime choice is a consequential experimental factor. Notably, it provides empirical evidence that the ranking of standard CL methods—online EWC, LwF, SI, and GEM—can change depending on the layer set allowed for parameter updates, even when all other variables are controlled.
Theoretical Framework: Adaptation as Subspace-Constrained Optimization
A rigorous subspace lens formalizes each fine-tuning regime as an orthogonal projector selecting parameter coordinates allowed to change during CL. Each training step performs a projected gradient update, limiting optimization to the span defined by the regime. Theoretical decomposition shows that, within this subspace, both the current-task signal and the knowledge-preservation regularizer act through the same restricted parameter set, and their interaction (measured as the inner product) changes as the subspace varies.
This leads to the key insight: the regime changes both the capacity for plasticity and the mechanisms of stability, not simply the count of trainable parameters. For example, shallow adaptation regimes, which update only late (output-proximal) layers, offer limited flexibility but mitigate interference at the representation level. In contrast, deeper regimes span more parameters, increasing expressivity but also allowing gradient signals for different tasks to compete more freely.
Systematic Empirical Evaluation Across Methods, Regimes, and Datasets
The experimental protocol implements five regimes on ResNet-18 (varying the number of trainable residual blocks, from last block only to full finetuning), four canonical CL algorithms, and five image recognition benchmarks (MNIST, Fashion MNIST, KMNIST, QMNIST, CIFAR-100). For each method-regime-dataset combination, 11 task orders are sampled, and accuracy and forgetting are tracked.
The most impactful finding is that method ranking is not invariant across regimes, revealed by mean Kendall’s τ rank-correlation coefficients that decrease substantially between restrictive and permissive adaptation regimes. These reversals are pronounced across all benchmarks, including standard continual learning datasets and the more complex CIFAR-100.
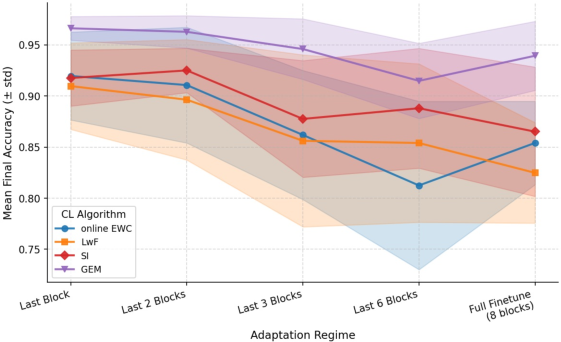
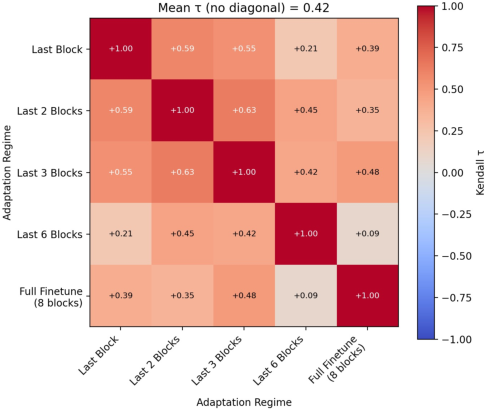
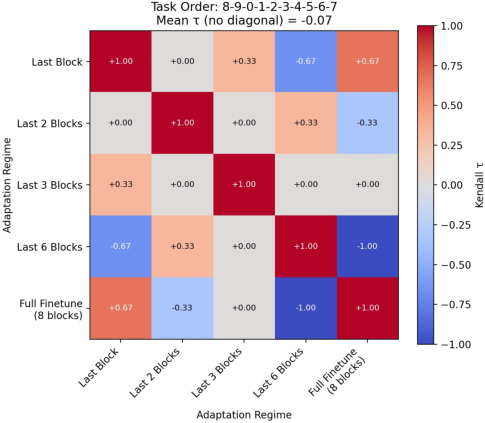
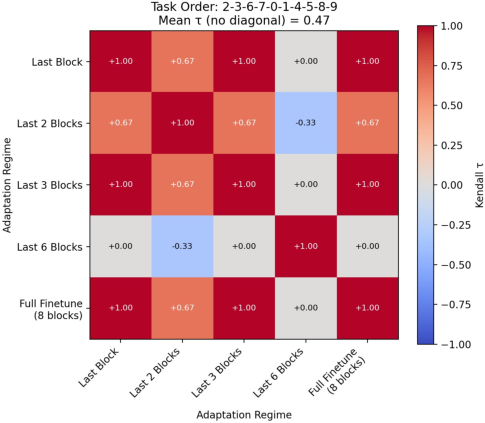
Figure 1: Final accuracy of four continual learning strategies across different fine-tuning regimes on Fashion MNIST, highlighting both mean performance shifts and large variances.
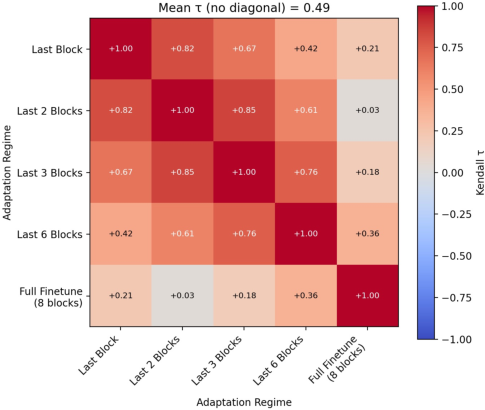
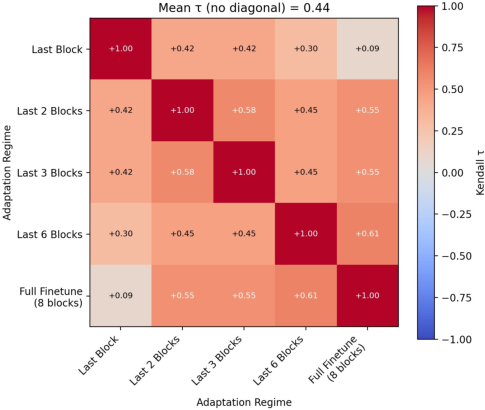
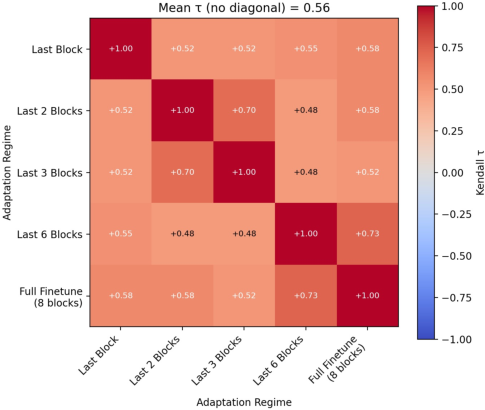
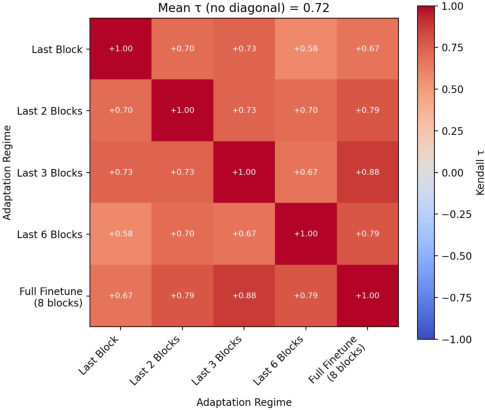
Figure 2: Mean Kendall’s τ across regime-specific rankings on CIFAR-100, showing significant ranking instability as the adaptation regime changes.
Notably, for some datasets, mean τ drops to approximately $0.42$ (Fashion MNIST), confirming frequent rank rearrangements. Even on natural image data (CIFAR-100), full finetuning grants higher final performance to some methods relative to others, while more restrictive regimes can reverse the observed hierarchy. Standard deviations in final accuracy and forgetting are also larger under regime variation, especially for under-constrained adaptation.
These results demonstrate that the choice of which subset of parameters to update fundamentally redefines the effective continual learning problem, and controlling only for backbone architecture and optimizer does not ensure meaningful algorithmic comparison.
Optimization Signal Analysis: Gradient Magnitude and Forgetting
To link the observed instability to underlying optimization mechanics, the projected gradient norm (within the trainable subspace) is analyzed in relation to post-training task forgetting. Variation in gradient magnitude is tightly coupled with overall forgetting, and both increase systematically with more permissive (deeper) adaptation regimes.
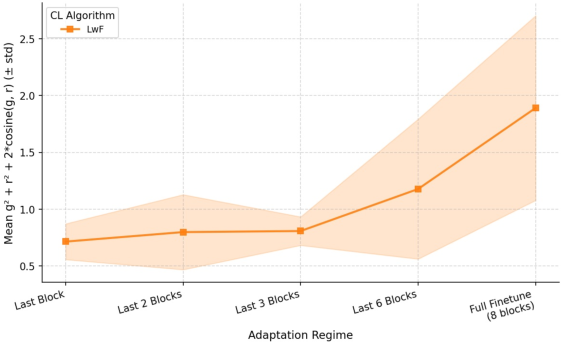
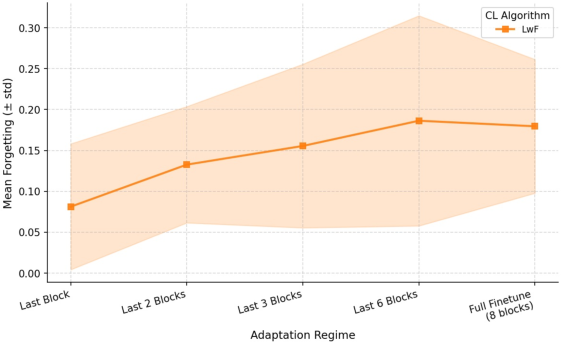
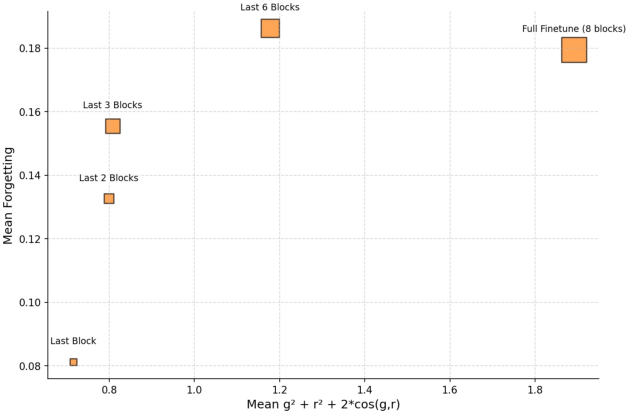
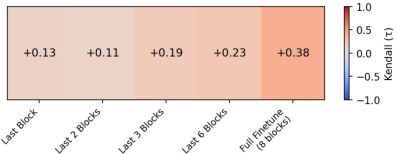
Figure 3: As more of the network is made trainable, projected gradient magnitude and catastrophic forgetting both increase, and their correlation tightens.
In particular, the Kendall’s τ correlation between gradient norm and forgetting is substantially higher under full finetuning. This implies that in deeper regimes, catastrophic forgetting not only becomes worse on average but also is more directly explained by the scale of parameter shifts allowed by the regime.
Implications and Future Directions
The primary implication is that comparisons between CL algorithms are regime-conditional: any superiority claim based on fixed adaptation (such as full network update) can be negated by altering which parameters are updated. This has direct ramifications for the design of CL benchmarks and for the reproducibility of conclusions in the field.
Practically, the results underscore the necessity of explicitly reporting and varying trainable depth as an experimental axis. Theoretically, the findings support a view where the geometry of the trainable subspace—rather than method design alone—plays a central role in shaping stability-plasticity trade-offs.
Notably, the study leaves open the generalization to alternative subspace parameterizations, such as sparse masking or low-rank adaptation, as well as to task-agnostic or class-incremental settings. Extension to other architectures (e.g., Transformers) should be prioritized to assess architectural sensitivity of these effects.
Conclusion
This work delivers strong evidence that fine-tuning regimes—specifically, the explicit selection of trainable parameter subspaces—are a first-class variable in continual learning evaluation. Regime-dependent gradient flows systematically alter method ranking, catastrophic forgetting, and optimization trajectories, indicating that any CL algorithm’s empirical standing is inextricably linked to such underlying experimental choices. Future CL studies should integrate regime variation as part of standard benchmark and reporting protocols to foster robust and generalizable method assessment.