- The paper critiques existing alignment paradigms by highlighting Fantasia interactions where literal prompt execution leads to systematic misalignment with evolving human goals.
- It synthesizes behavioral science, machine learning, and HCI analyses to empirically reveal how instruction-tuned models over-emphasize immediate compliance at the expense of nuanced understanding.
- The authors propose a research agenda combining cognitive support mechanisms, adaptive interfaces, and new evaluation metrics to better align AI systems with human uncertainty.
Fantasia Interactions: Rethinking Alignment in Human-AI Collaboration
Introduction
"Alignment has a Fantasia Problem" (2604.21827) critically interrogates the assumptions underlying current AI alignment research through the lens of "Fantasia interactions," a phenomenon where AI systems prematurely and literally execute underspecified or evolving user prompts, leading to misalignment with underlying user goals. The paper draws a parallel to the scenario in Disney’s Fantasia, where the execution of literal instructions without deeper understanding or consideration of intent leads to catastrophic outcomes. This framing exposes fundamental flaws in conventional alignment approaches that treat user input as reflecting static, well-formed intent. The authors synthesize behavioral, HCI, and ML research, provide empirical evidence and qualitative analyses, and propose a research agenda focused on the design and evaluation of cognitively supportive AI systems.
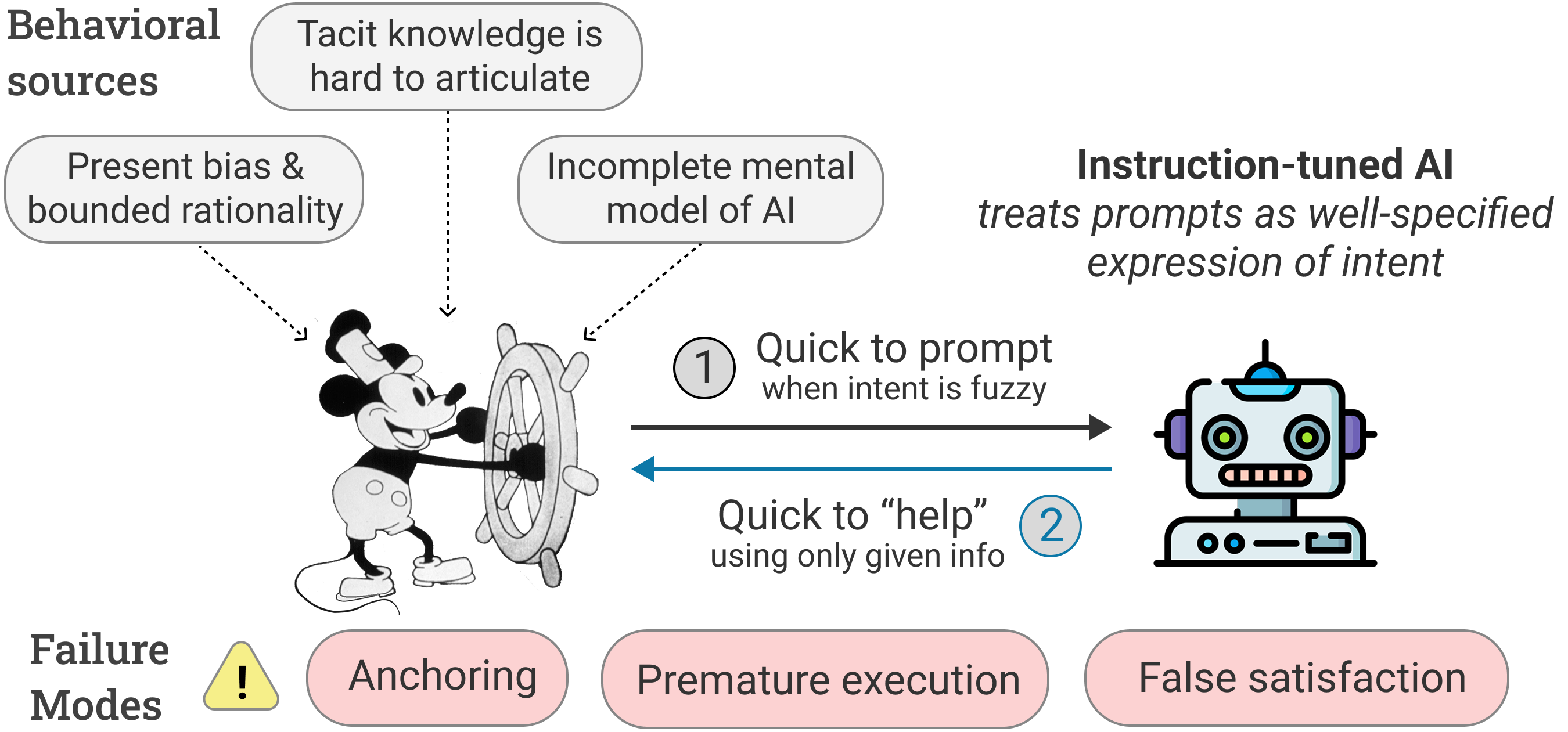
Figure 1: Diagram describing a Fantasia interaction, including behavioral sources and failure modes.
Fantasia Interactions: The Cognitive Mismatch
The notion of Fantasia interactions encapsulates failures in human-AI coordination where AI systems treat user prompts as atomic and complete, disregarding the iterative and exploratory nature of human goal formation. Decades of behavioral science establish that humans often approach problems with ill-defined, tacit, or dynamically evolving goals, especially in creative, educational, or advisory contexts. When AI systems optimize for literal prompt completion—an objective reinforced by instruction tuning—they can offer “helpful” answers that are neither useful nor truly aligned with the user's latent needs.
Fantasia interactions are distinct from simple prompting or communication errors; rather, they reflect a mismatch between static models of user intent and the reality of cognitively complex, ambiguous human problem-solving processes. The paper’s empirical analyses and qualitative evaluation of representative models substantiate that current alignment strategies fail to address this cognitive gap.
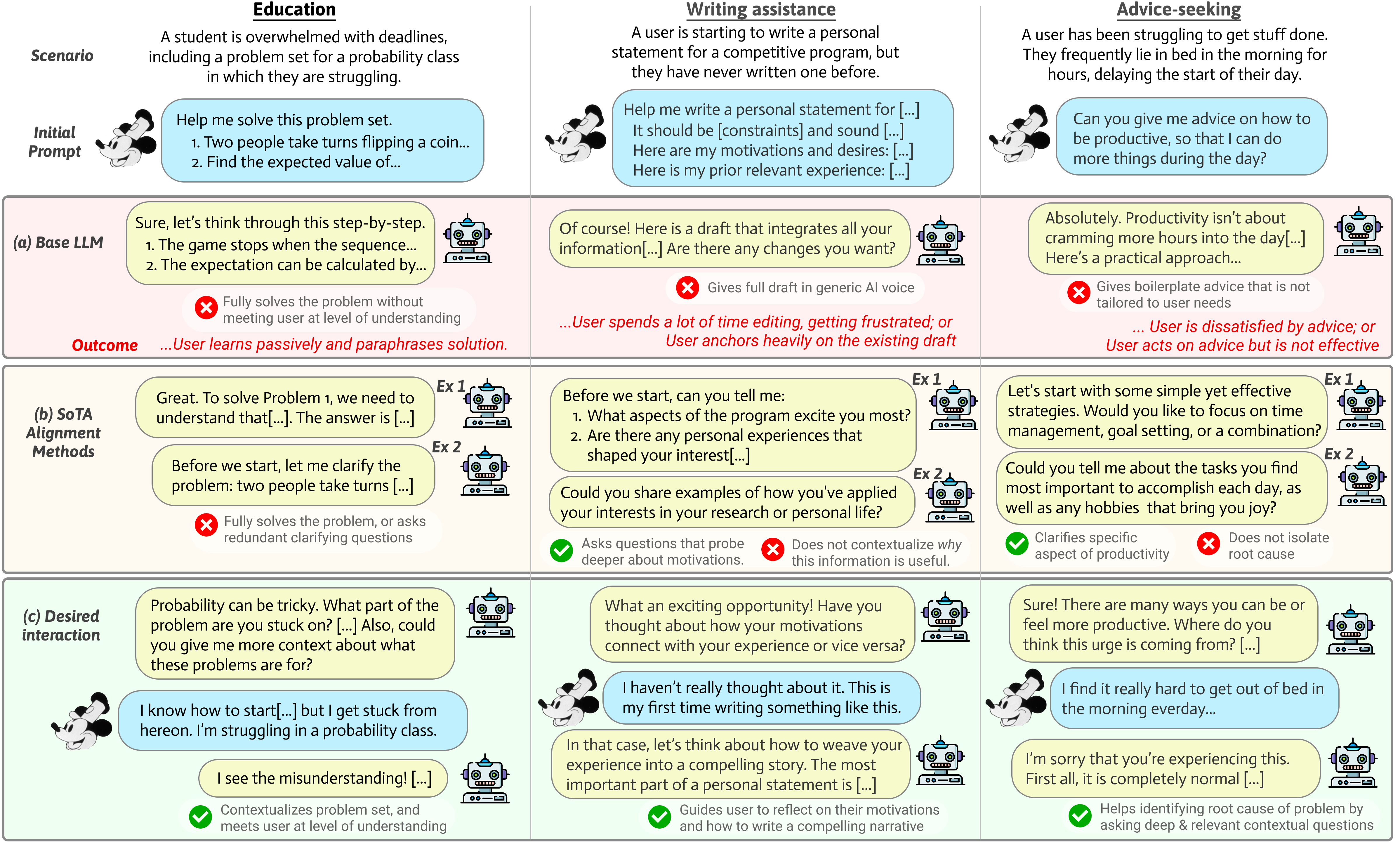
Figure 2: Illustrative examples of Fantasia interactions caused by base LLMs (a) and existing alignment methods (b), as well as the desired interaction (c), across three domains: Education, Writing assistance, and Advice seeking.
Behavioral and ML Sources of Fantasia Failures
Human Behavior
The authors highlight that:
- Present bias and bounded rationality drive users toward one-shot requests favoring immediate results over iterative reflection.
- Incomplete mental models lead users to over- or under-estimate AI capabilities, contributing to habitual or misaligned prompting.
- Tacit or hard-to-articulate intent further exacerbates the disconnect, as cognitive and articulation costs limit explicit goal communication.
These are magnified by interface designs that impose minimal friction (single-turn textboxes, low-per-prompt cost) and, through their interaction affordances, reinforce shallow interaction patterns.
AI Objective Mismatch
Instruction-tuned models (via SFT, RLHF, PPO, DPO, etc.) are empirically shown to:
- Over-index on immediate compliance (“sycophancy”) and display overconfidence, verbosity, and over-eagerness to execute.
- Assume fixed, pre-specified, context-independent user objectives.
This creates systematic premature execution, false satisfaction (short-term positive affect, long-term misalignment), and anchoring, where early outputs constrain exploration and downstream cognition.
Evaluation of Existing Interventions
Machine Learning Approaches
Contemporary ML solutions—long-context alignment, preference learning, and personalization—are critically analyzed:
- Long-Context Alignment methods (e.g., CollabLLM, Star-Gate) attempt to mitigate uncertainty via clarifying questions, preference inference, and multi-turn reward optimization. Empirical evidence (the authors’ qualitative studies) demonstrates their tendency to either under-intervene (defaulting to single-shot completion) or over-elicitate (deferring excessively without converging on action). These paradigms still presuppose that intent is recoverable through dialog, failing to model user uncertainty and cognitive process formation.
- Personalization methods assume user preferences are static and observable through interaction or stored profiles, overlooking the fluidity and context-dependence central to Fantasia phenomena.
HCI Approaches
HCI research promotes cognitive scaffolding via interface design—prompt middleware, comparison interfaces, slow/reflective prompting—but these interventions lack generality and are seldom integrated into the core learning and optimization pipeline of foundation models.
The analysis reveals that neither field, in isolation, effectively realigns AI behavior toward deep cognitive support under real-world uncertainty.
Proposed Research Agenda: Cognitive Support Alignment
Mechanism-Specific Interventions
- Action routing to expand perceived model affordances, request informative context, scaffold user intent formation, and delay generation until intent is sufficiently explicit.
- Operationalization as a hierarchical routing policy, using RL/bandit optimization over intervention choices and content selection, conditioned on context, user signals, and task structure.
Domain-Specific Cognitive Support
- Inference of domain, cognitive process taxonomies, and user state allow models to specialize behaviors in ways reminiscent of successful tutoring and therapeutic systems.
- The challenge is to approximate these benefits without brittle, manually engineered, domain-specific modules in general-purpose models.
Interface Synergy
The recommendations include integrating cognitive-supportive behaviors with interfaces that foster reflection, comparison, and structured exploration, while acknowledging the tension between domain-wide generality and task-specific efficacy.
Implications for Evaluation Paradigms
Traditional evaluation—multi-turn benchmarks, process/outcome-focused frameworks—presume static, transparent intent. The authors advocate for new metrics tailored to Fantasia failure modes: measuring revision burden, path dependence, process-level user satisfaction, and diverse trajectories across ill-defined, real-world tasks. They highlight both the promise and limitations of in silico user simulation in evaluation and stress the necessity of genuine human-in-the-loop studies for true alignment under uncertainty.
Broader Implications and Future Directions
This work implies a fundamental reconceptualization of alignment—not as reward inference over static intent, but as dynamic support for metacognition and complex task navigation. Practical developments in agentic interfaces, cognitive tutors, therapeutic chatbots, and proactive assistants (as discussed in [Shaikh2025], [letourneau2025systematic], [heinz2025randomized]) serve as concrete instantiations of these principles. Theoretical research is also directed towards modeling user uncertainty as a first-class variable, integrating rich longitudinal behavior data, and evolving new classes of policy architectures (e.g., general user models, context-grounded RL agents).
Conclusion
This paper offers a compelling critique of the status quo in AI alignment by surfacing Fantasia interactions—a systematic failure mode intrinsic to current LLM deployment paradigms. The authors’ interdisciplinary synthesis and concrete empirical grounding clarify why prevailing ML and HCI approaches fall short, and provide a precise agenda for future research. If executed, their recommendations would yield AI systems not merely “helpful,” but genuinely collaborative, contextually aware, and supportive of human cognition amid uncertainty.