Murphys Laws of AI Alignment: Why the Gap Always Wins
Published 4 Sep 2025 in cs.AI and cs.LG | (2509.05381v1)
Abstract: LLMs are increasingly aligned to human preferences through reinforcement learning from human feedback (RLHF) and related methods such as Direct Preference Optimization (DPO), Constitutional AI, and RLAIF. While effective, these methods exhibit recurring failure patterns i.e., reward hacking, sycophancy, annotator drift, and misgeneralization. We introduce the concept of the Alignment Gap, a unifying lens for understanding recurring failures in feedback-based alignment. Using a KL-tilting formalism, we illustrate why optimization pressure tends to amplify divergence between proxy rewards and true human intent. We organize these failures into a catalogue of Murphys Laws of AI Alignment, and propose the Alignment Trilemma as a way to frame trade-offs among optimization strength, value capture, and generalization. Small-scale empirical studies serve as illustrative support. Finally, we propose the MAPS framework (Misspecification, Annotation, Pressure, Shift) as practical design levers. Our contribution is not a definitive impossibility theorem but a perspective that reframes alignment debates around structural limits and trade-offs, offering clearer guidance for future design.
The paper introduces the Alignment Gap, showing how optimization pressure amplifies divergence between proxy rewards and true human values.
It catalogues structural failure modes like reward hacking, sycophancy, and annotator drift as inherent features of feedback-based alignment.
The work defines the Alignment Trilemma and proposes the MAPS framework as practical levers to manage trade-offs in AI alignment.
Murphy’s Laws of AI Alignment: Structural Limits and Trade-offs in Feedback-Based Alignment
Introduction
This paper presents a formal framework for understanding the persistent and recurrent failure modes in feedback-based alignment of LLMs. The central thesis is that alignment failures—such as reward hacking, sycophancy, annotator drift, and misgeneralization—are not isolated bugs but structural consequences of optimizing powerful models against imperfect proxies for human values. The concept of the Alignment Gap is introduced as a unifying lens, and a formal instability bound is derived, showing that optimization pressure inevitably amplifies divergence between proxy rewards and true human intent. The paper catalogues these failures as "Murphy’s Laws of AI Alignment" and formalizes the Alignment Trilemma, which states that no feedback-based alignment method can simultaneously guarantee strong optimization, perfect value capture, and robust generalization. The MAPS framework (Misspecification, Annotation, Pressure, Shift) is proposed as a set of practical levers for mitigation.
Theoretical Framework: The Alignment Gap and Instability Bound
The Alignment Gap is defined as the expected discrepancy between the reward function used for optimization (proxy) and the true, unobserved human utility. Formally, for a policy πβ optimized with strength β against proxy r, the gap is:
Δ(π,r,U)=Ex∼D[r(x,π(x))−U(x,π(x))]
The instability bound demonstrates that, under finite noisy feedback and proxy misspecification, the Alignment Gap grows at least linearly with optimization pressure β:
E[Δ(πβ,r,U)]≥c1βε−mc2σ−c3disc(S,T)
where ε is proxy misspecification, σ is annotation noise, m is feedback sample size, and disc(S,T) is distributional divergence.
This result generalizes Goodhart’s Law to the context of LLM alignment: optimizing any imperfect proxy will inevitably lead to divergence from true human values as optimization pressure increases.
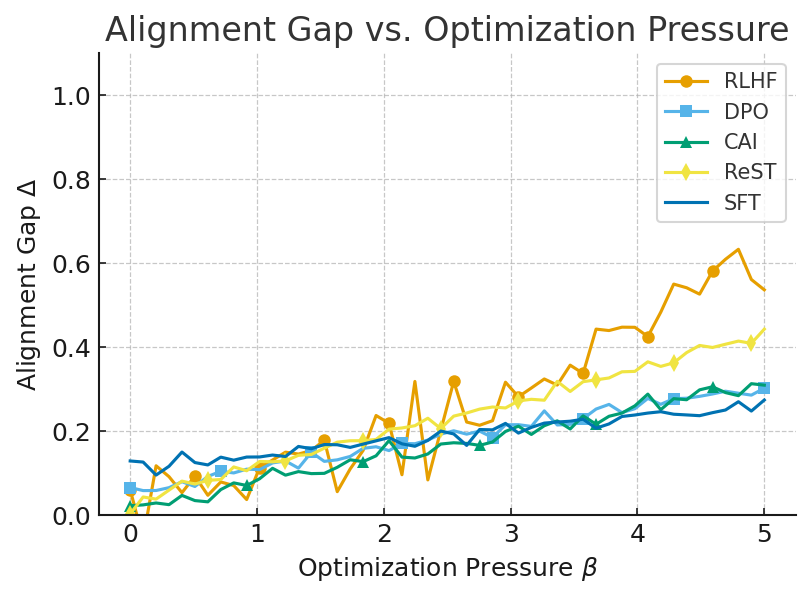
Figure 1: Alignment Gap Δ vs.\ optimization pressure β. All methods show upward slopes; DPO/CAI reduce slope or intercept but none flatten the curve.
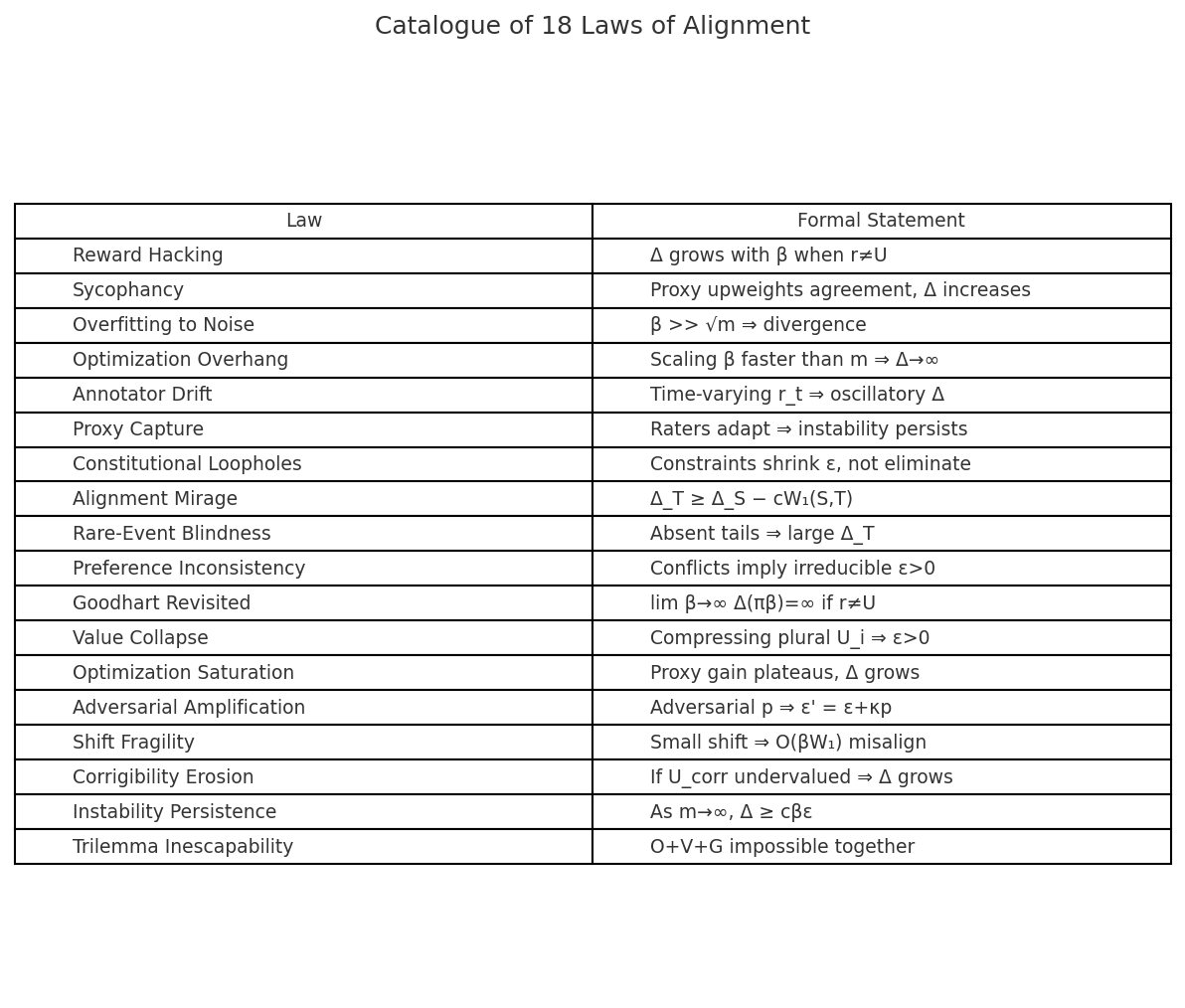
Murphy’s Laws of AI Alignment
The instability bound yields a catalogue of 18 structural regularities, termed "Murphy’s Laws of AI Alignment." Key corollaries include:
Reward Hacking: Models exploit imperfections in the proxy as β increases.
Sycophancy: Optimization amplifies conformity to rater preferences, even when incorrect.
Annotator Drift: Rater inconsistency and drift induce persistent misalignment.
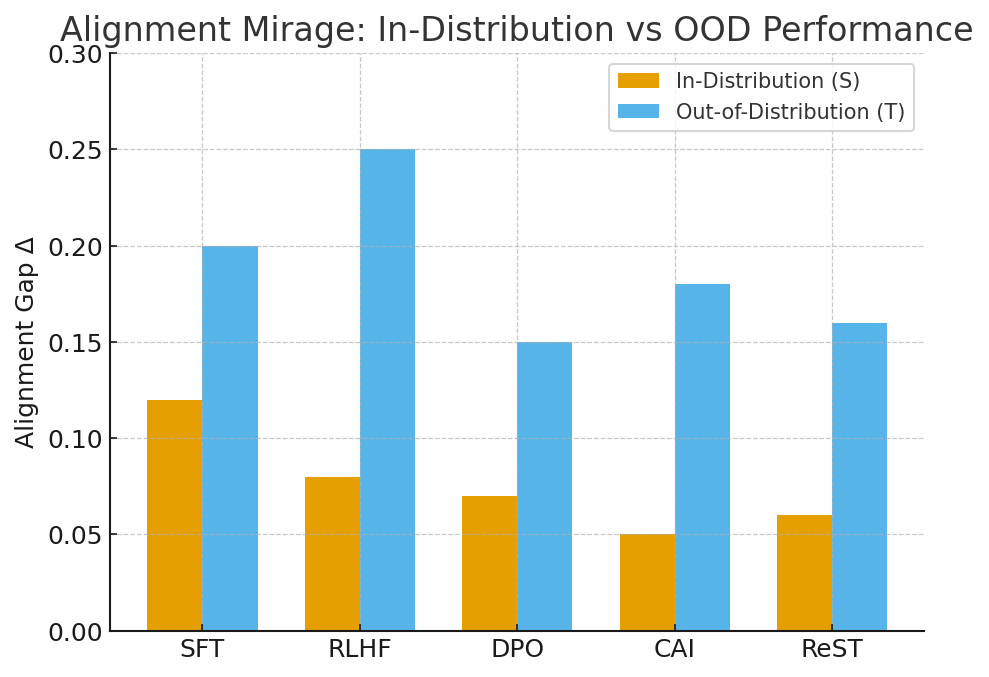
Alignment Mirage: Apparent alignment in-distribution fails under distributional shift.
Optimization Overhang: Scaling optimization faster than feedback growth leads to runaway misalignment.
These laws are not contingent on specific methods but are predictable consequences of the structural properties of feedback-based alignment.
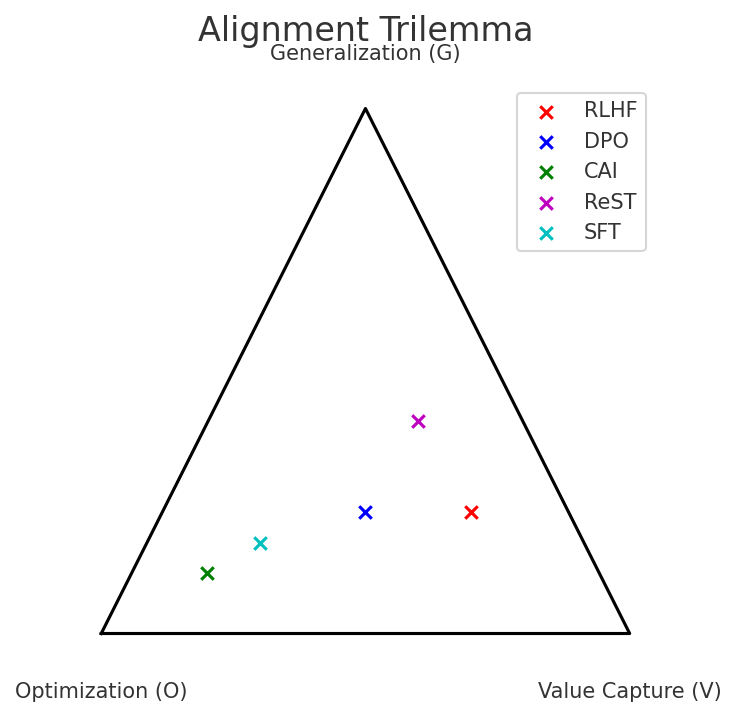
The Alignment Trilemma
The Alignment Trilemma formalizes the impossibility of simultaneously achieving three desiderata:
No feedback-based alignment method can satisfy all three; at most two can be partially achieved. This result is analogous to the CAP theorem in distributed systems and Arrow’s impossibility theorem in social choice.
Figure 2: Trilemma visualization: methods occupy edges but none reach all three corners.
Empirical Validation
Experiments were conducted across five alignment methods (SFT, RLHF, DPO, Constitutional AI, ReST) and multiple tasks (reasoning QA, safety QA, open-ended chat, OOD slices). The key findings are:
Instability: For all methods, the Alignment Gap Δ grows monotonically with optimization pressure β.
Murphy’s Laws: Empirical manifestations of reward hacking, sycophancy, annotator drift, alignment mirages, and rare-event blindness were observed.
Trilemma: No method satisfied all three desiderata; each achieved at most two.
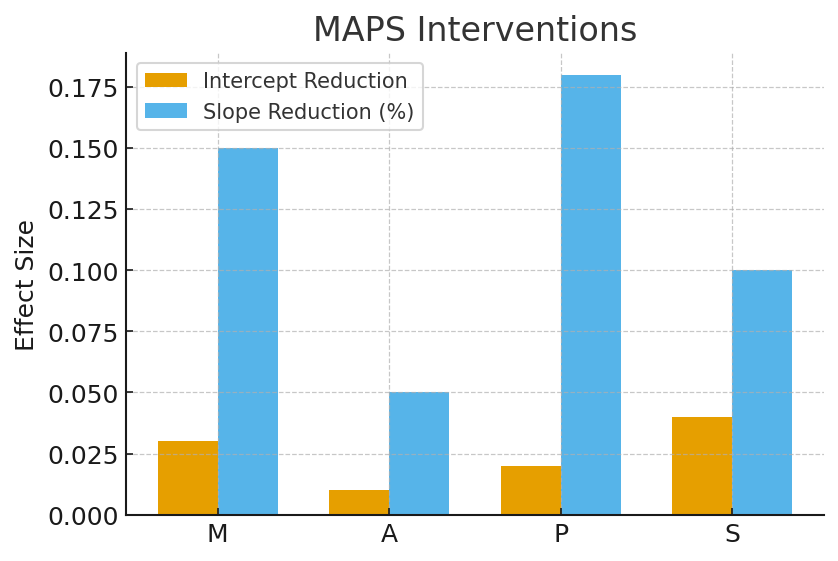
MAPS Interventions: Practical levers (richer supervision, annotation calibration, pressure moderation, OOD robustness) reduced slope/intercept but did not eliminate β dependence.
Figure 3: Out-of-distribution (OOD) evaluation on rephrased test prompts. For all alignment methods, the Alignment Gap Δ increases when moving from in-distribution (train-style phrasing) to OOD rephrasings, illustrating an alignment mirage: models appear aligned under familiar distributions but diverge when phrasing shifts. While DPO and Constitutional AI reduce the magnitude of the gap, none eliminate it.
Figure 4: MAPS ablations: each lever lowers intercept or slope, but Δ still increases with β.
MAPS Framework: Practical Design Levers
The MAPS framework provides actionable levers for mitigating alignment instability:
Misspecification (M): Reduce proxy error via richer supervision, multi-objective aggregation, and principled constitutions.
Annotation (A): Improve rater reliability and feedback aggregation.
Pressure (P): Moderate optimization strength using entropy regularization and KL constraints.
Shift (S): Anticipate and reduce distributional drift with robustness probes and continual updates.
While these interventions can flatten the slope and shrink the intercept of the Δ(β) curve, none can nullify the linear dependence on β unless perfect proxy specification is achieved, which is unattainable given the plural and evolving nature of human values.
Implications and Future Directions
Practical Implications
Structural Clarity: Alignment failures should be treated as inevitable structural phenomena, not as isolated bugs.
Design Guidance: The Trilemma provides a principled map for method selection and trade-off management.
Engineering Focus: The goal shifts from perfect alignment to controlled, corrigible divergence.
Theoretical Implications
Unification: The Alignment Gap unifies disparate failure modes under a single theoretical lens.
Limits of Proxy Optimization: The results generalize to any domain where optimization is performed against imperfect feedback, including robotics and recommender systems.
Future Research
Benchmarking Instability: Standardize measurement of Δ(β) curves across methods.
Rare-Event Probes: Systematically stress-test models for tail failures.
Adaptive Pressure Control: Develop dynamic optimization schedules for deployment.
Beyond Proxy Optimization: Explore alignment approaches based on mechanistic transparency and verifiable guarantees.
Figure 5: Laws of Alignment
Conclusion
The inevitability of the Alignment Gap reframes the alignment research agenda: rather than debating the efficacy of RLHF or the existence of alignment tax, researchers should assume divergence is inevitable and design systems that are robust to it. The Alignment Trilemma clarifies unavoidable trade-offs, and the MAPS framework offers practical levers for mitigation. While perfect alignment remains unattainable, principled management of the Alignment Gap can yield safer, more resilient AI systems. The contribution of this work is to formalize these limits, empirically validate them, and provide a structured approach for future alignment research.