The Recurrent Transformer: Greater Effective Depth and Efficient Decoding
Abstract: Transformers process tokens in parallel but are temporally shallow: at position $t$, each layer attends to key-value pairs computed based on the previous layer, yielding a depth capped by the number of layers. Recurrent models offer unbounded temporal depth but suffer from optimization instability and historically underutilize modern accelerators. We introduce the Recurrent Transformer, a simple architectural change where each layer attends to key-value pairs computed off its own activations, yielding layerwise recurrent memory while preserving standard autoregressive decoding cost. We show that the architecture can emulate both (i) a conventional Transformer and (ii) token-to-token recurrent updates under mild assumptions, while avoiding optimization instability. Naively, prefill/training appears bandwidth-bound with effective arithmetic intensity near $1$ because keys and values are revealed sequentially; we give an exact tiling-based algorithm that preserves the mathematical computation while reducing HBM traffic from $Θ(N2)$ to $Θ(N\log N)$, increasing effective arithmetic intensity to $Θ(N/\log N)$ for sequence length $N$. On 150M and 300M parameter C4 pretraining, Recurrent Transformers improve cross-entropy over a parameter-matched Transformer baseline and achieve the improvement with fewer layers (fixed parameters), suggesting that recurrence can trade depth for width, thus reducing KV cache memory footprint and inference latency.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a new kind of AI model called the Recurrent Transformer. It is designed to understand and generate sequences (like sentences) better by letting each layer in the model “think through time” more deeply, while still staying fast and efficient to use. The authors show that their design can be trained stably, run efficiently, and improve quality compared to regular Transformers of similar size.
Goals
The paper aims to answer a few simple questions:
- Can we make Transformers “deeper through time” so they can do more thinking per layer, not just by stacking more layers?
- Can this new design avoid the training problems that old recurrent models sometimes have (like gradients exploding or vanishing)?
- Can we train it efficiently on modern GPUs?
- Does it actually work better in practice, and can it reduce memory and speed up decoding?
How it works
To understand the core idea, think of “attention” as the model asking questions about earlier words in a sentence. Each earlier word stores a “key–value pair”: a key is like a label describing what that word is about, and a value is like a note with useful information. The current word makes a “query” (a question) and uses attention to read the right notes from the past.
The core idea: layerwise recurrence
In a regular Transformer, each layer creates the keys and values from the input at that position before attention is applied. In the Recurrent Transformer, each layer instead saves keys and values made from the output after that layer has already done its attention and MLP (a small neural network) computation. That means later words can attend to earlier words whose representations are already more processed—so each layer becomes “recurrent” in time.
There’s one catch: at the current position, we can’t use its final output to compute its own keys/values (that would be circular). So the Recurrent Transformer uses two kinds of key–value pairs at each position:
- Temporary pair: made from the current input; used only for the current position’s attention and then discarded.
- Persistent pair: made from the current output; saved and used by all the later positions in the same layer.
This small change lets the model do more thinking within each layer, because future positions can read richer, already-updated information from earlier positions.
What this design can represent
- It can imitate a regular Transformer: under mild conditions, the authors show the Recurrent Transformer can recreate the same attention behavior and layer outputs as a standard Transformer, just inside a slightly larger embedding.
- It can behave like a recurrent model: if attention mostly focuses on the immediately previous token, the updates act like a token-to-token recurrence, similar to an RNN. So the model sits between fully parallel attention and fully recurrent processing.
Keeping training stable
Old recurrent models could suffer from “exploding” or “vanishing” gradients, which makes training hard. The Recurrent Transformer avoids this in two ways:
- It still allows direct one-hop attention from any past position to the current one (like regular Transformers), so long-range information doesn’t have to pass through a long chain.
- It adds many multi-hop paths within a layer, but uses standard normalization and scaling tricks to keep these paths damped (not exploding). The authors give a simplified math proof showing gradients shouldn’t explode under common settings.
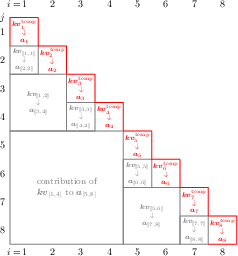
Making training fast: tiled prefill/training
Training the Recurrent Transformer might look slow at first, because keys/values become available one position at a time. If you process one query at a time, you end up repeatedly pulling in lots of past data to do a small amount of work. GPUs prefer lots of math per byte moved, a property called “arithmetic intensity.”
The authors introduce an exact “tiling” algorithm:
- Instead of waiting and doing attention for only the next query, they compute all queries up front (they only depend on inputs, not yet on the new persistent keys/values).
- As each new key–value block becomes available, they immediately reuse it across many future queries before moving on.
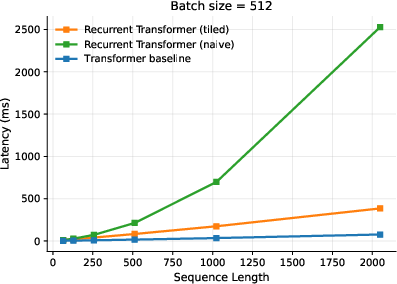
- This reordering keeps the math identical but reduces heavy memory traffic from about to for sequence length , and raises arithmetic intensity from about constant to .
- Result: much closer to linear scaling in time with sequence length, instead of quadratic.
They also describe practical engineering choices (like using CUDA Graphs and smart memory layouts) to keep the GPU busy and reduce overhead.
Main findings
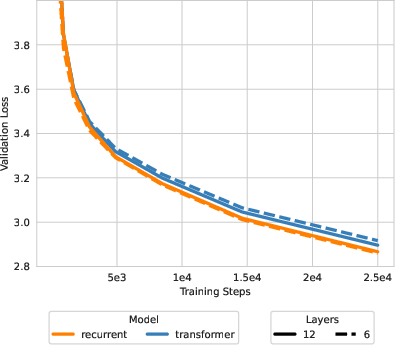
- Better quality at similar size: On language modeling with 150M and 300M parameter models trained on the C4 dataset, the Recurrent Transformer achieved lower cross-entropy (a measure of how well the model predicts the next token—lower is better) than a regular Transformer with the same number of parameters. For the 300M models, improvements were around 0.03 to 0.057 in cross-entropy, which is meaningful at this scale.
- Fewer layers can match or beat deeper baselines: At fixed parameter count, the Recurrent Transformer with fewer layers but wider embeddings performed as well as or better than deeper regular Transformers. This shows the “deeper-through-time per layer” effect can trade depth for width without losing quality.
- Efficiency gains:
- Training/prefill: The tiled algorithm cut memory traffic and made the forward pass scale near-linearly in sequence length, significantly improving speed.
- Decoding: Because you can use fewer layers for similar quality, the key–value cache needed for inference drops by roughly 30% in the authors’ setup, reducing memory bandwidth during decoding and helping with latency.
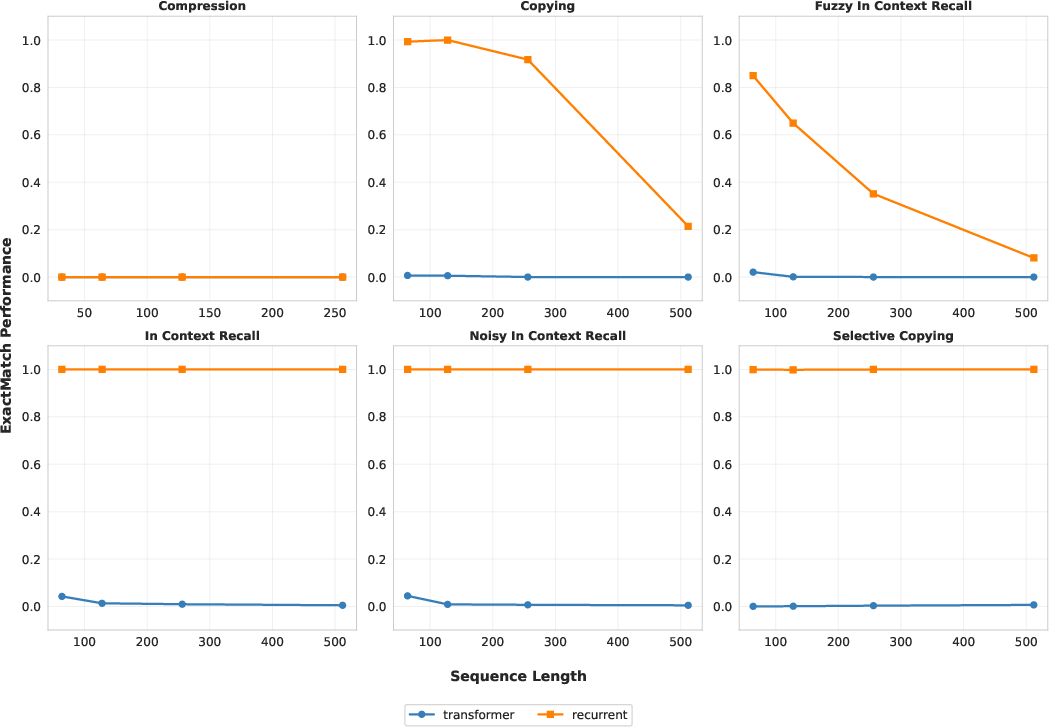
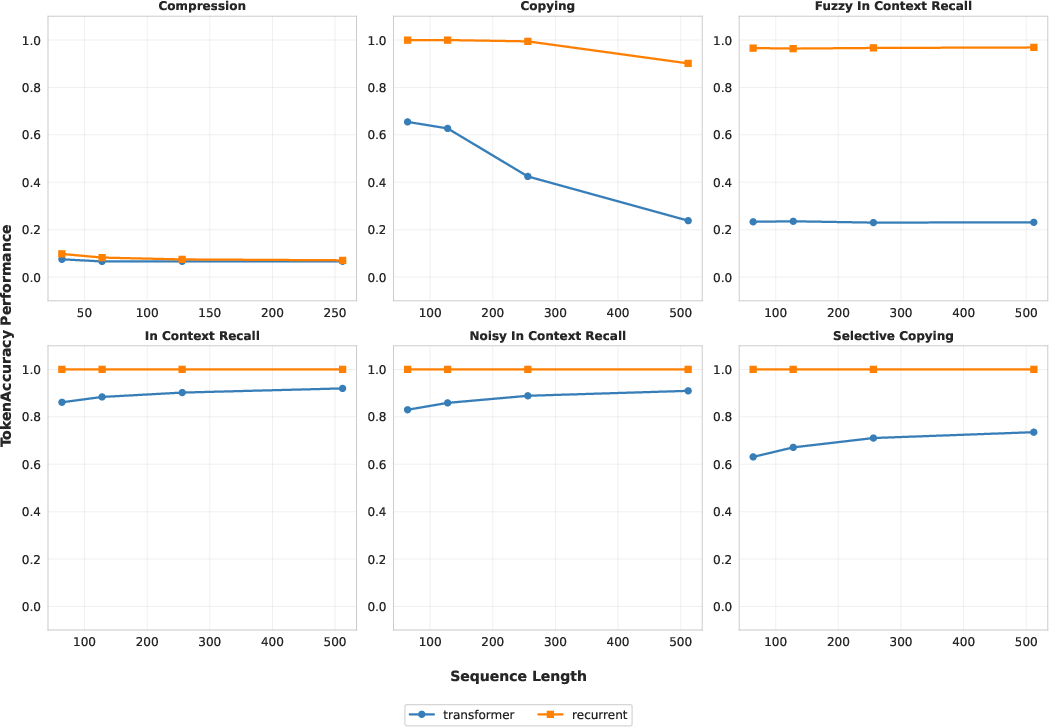
- Synthetic tests: On tasks designed to probe models’ ability to track and manipulate information, the Recurrent Transformer outperformed the regular Transformer in most cases, indicating stronger “effective depth” and iterative reasoning within a layer.
Why this matters
- Stronger reasoning per layer: By letting each layer reuse the outputs of earlier tokens within the same layer, the model gains extra “temporal depth.” This can help with tasks that require multi-step reasoning along a sequence.
- Better speed–quality tradeoffs: If you can reach the same quality with fewer layers, you reduce memory footprint and potentially speed up inference. That matters for serving models at scale and for running them on limited hardware.
- Bridges two worlds: The Recurrent Transformer can act like both a Transformer and a recurrent model, depending on how attention is used. This flexibility may inspire new designs that combine the strengths of parallel attention and recurrence without the usual training pains.
In short, the Recurrent Transformer is a small but powerful change: make keys and values come from each layer’s outputs, not its inputs. That unlocks deeper computation within each layer, can be trained stably, can be evaluated efficiently with smart tiling, and leads to real gains in quality and efficiency.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and open questions that remain unresolved and can guide future work:
- Scaling and generality
- Absence of results beyond 300M parameters and 3B tokens: Does the Recurrent Transformer (RT) maintain stability, training efficiency, and quality at 1–70B+ scales and at higher token budgets?
- Long-context regime: No evaluation for very long contexts (e.g., 8k–128k). How do quality, memory traffic, and latency scale with context length during both prefill and decode?
- Cross-modality and task diversity: No evidence for vision, audio, or encoder–decoder tasks. Can RT be adapted to bidirectional or cross-attention settings (e.g., translation, retrieval-augmented generation)?
- Decoding efficiency claims
- End-to-end decode benchmarks are missing: Quantify latency/throughput vs Transformer under realistic configurations (batch size, beam size, sequence lengths) and modern decode stacks (FlashDecoding, MQA/GQA, paged KV caches).
- Depth-to-width tradeoff in practice: Validate the claimed KV cache and bandwidth savings with actual decode implementations across GPUs and multi-node setups; characterize where RT is bandwidth- vs compute-limited.
- Robustness of the “sqrt(alpha)” cache-savings heuristic: Empirically verify KV memory/traffic vs quality tradeoffs across multiple depths/widths and model sizes.
- Training/prefill tiling algorithm
- Backward pass profiling and asymptotics: Provide end-to-end HBM traffic, arithmetic intensity, and wall-clock measurements for backward; quantify how much of the forward gains carry over.
- Optimality and lower bounds: Is Θ(N log N) HBM traffic optimal for RT training/prefill, or can it be reduced further (e.g., Θ(N)) under exactness constraints?
- Tile-size sensitivity and portability: Characterize performance sensitivity to tile/block sizes, sequence length distributions, and heterogenous hardware (A100/H100 vs TPU/AMD).
- Numerical stability in low precision: Evaluate stability (bf16/fp8) of online softmax accumulation across many tiles; quantify output drift due to floating-point reordering.
- Distributed and systems aspects
- Parallelism strategies: No evidence for data-, tensor-, and pipeline-parallel scaling. Does within-layer recurrence impede pipeline utilization or interleave poorly with sequence parallelism?
- CUDA Graph constraints: Graph capture typically requires static shapes. How robust is training to variable sequence lengths, dynamic padding, and mixture-of-length batches?
- Kernel-level optimization: The implementation lacks custom kernels. What gains are achievable with fused attention+MLP kernels, kernel fusion across tiles, and FlashAttention/FlashDecoding integration?
- Architectural design choices and ablations
- Persistent vs temporary KV parameterization: Explore separate K/V projections (instead of tying), gating or learned write policies into persistent memory, and computing persistent KVs pre- vs post-MLP.
- Normalization and scaling: Ablate RMSNorm vs LayerNorm, QK-Norm on/off, residual scaling schemes, and pre-LN vs post-LN; report sensitivity and stability envelopes.
- Heads and attention variants: Compatibility and efficacy with multi-query/grouped-query attention, sliding-window/dilated attention, RoPE/ALiBi, and dropout.
- MLP structure and bottlenecks: Measure how MLP depth/width and activation functions affect the RT’s batch-size-driven arithmetic intensity bottleneck; assess alternatives (e.g., gated MLPs).
- Write/read locality: Investigate positional biases or mechanisms that encourage beneficial multi-hop paths while limiting degenerate self-amplification.
- Theoretical analysis
- Stability beyond a toy setting: Current analysis covers a 1-layer uniform-attention setup without normalization. Provide stability/gradient-norm bounds with softmax attention, multihead, normalization, and residuals.
- Expressivity bounds and tightness: The Transformer emulation requires 3× width. Are tighter constructions possible? Are there tasks where RT is provably more efficient (depth-wise) than Transformers?
- Formal limits of recurrence: Clarify whether RT can emulate gated RNN/LSTM-like dynamics, and whether there are representational gaps vs standard Transformers or SSMs under realistic constraints.
- Empirical evaluation breadth and rigor
- Statistical significance: Report variance across seeds and hyperparameter sweeps to establish robustness of the observed CE gains (~0.03–0.06).
- Stronger benchmarks: Include broader downstream tasks (e.g., ARC-Challenge, MMLU, GSM8K/BBH, long-context retrieval) and perplexity vs context-length curves to stress the purported temporal depth benefits.
- Training efficiency and cost: Provide end-to-end wall-clock tokens/sec, compute utilization (FLOPs/s), and energy per token vs Transformer baselines, including backward and checkpointing overheads.
- Inference equivalence and correctness
- Decode-time equivalence: The paper claims “essentially the same per-token attention” as a Transformer, but no formal demonstration. Precisely characterize any numerical or algorithmic differences due to persistent/temporary KV usage and their impact on generation quality.
- Compatibility with speculative decoding and caching strategies: Assess correctness/performance when combined with speculative decoding, KV cache eviction/compression, quantized KV, and chunked prefill.
- Practical constraints and usability
- Memory footprint and activation management: Provide detailed activation memory profiling with/without checkpointing; quantify recomputation overhead vs Transformer across batch sizes and sequence lengths.
- Dynamic data pipelines: Evaluate training with variable-length packing/bucketing and curriculum schedules, given CUDA Graph and recurrence constraints.
- Reproducibility and portability: Ensure results replicate across frameworks (PyTorch/XLA/JAX) and hardware, and document any hidden constraints (e.g., layout, alignment, graph-capture caveats).
- Comparisons to closest baselines
- Head-to-head with Feedback Transformer, Staircase Attention, and TransformerFAM under modern training regimes and equalized parameter/FLOP budgets; analyze quality, stability, and end-to-end speed.
Practical Applications
Practical Applications of “The Recurrent Transformer: Greater Effective Depth and Efficient Decoding”
Below, we extract actionable, real-world applications enabled by this paper’s architecture (layerwise recurrent attention), training-time tiling algorithm (HBM traffic Θ(N log N)), and empirical depth–width tradeoffs (fewer layers at fixed parameters). Each item lists sectors, possible tools/workflows, and key assumptions/dependencies.
Immediate Applications
- Drop-in training of LLMs with Recurrent Transformer (RT) layers to improve quality or reduce depth at fixed parameters
- Sectors: software/AI infrastructure, academia
- Tools/workflows: integrate the open-source RT layer into existing codebases (e.g., PyTorch, OLMo/HF Transformers); keep standard pre-LN, RMSNorm, QKNorm, 1/√L residual scaling; replicate C4 training recipes; monitor gradient norms; unit-test equivalence to baseline Transformer for ablations
- Assumptions/dependencies: benefits demonstrated at 150M–300M params on C4; generalization to larger scales and broader datasets should be validated; normalization/scaling choices are important for stability; training stack must support custom layer definitions
- Reduced decode-time KV cache and bandwidth for inference through depth-to-width tradeoffs
- Sectors: cloud serving, edge/embedded AI, finance (low-latency inference), consumer apps
- Tools/workflows: train RT models with fewer layers and larger width at the same parameter count; deploy on inference stacks that are KV-cache and bandwidth limited; measure throughput/latency vs. vanilla Transformer baselines
- Assumptions/dependencies: comparable quality with fewer layers is task- and scale-dependent; the KV cache reduction (~30% shown at 300M) hinges on keeping accuracy stable; throughput gains materialize most in bandwidth-bound regimes
- Faster, more bandwidth-efficient prefill/training via exact tiling of attention within each layer
- Sectors: AI infrastructure, cloud training, hardware-accelerated ML
- Tools/workflows: implement the paper’s exact tiling schedule that reorders memory movement (Θ(N2) → Θ(N log N) HBM traffic; higher arithmetic intensity); integrate online softmax accumulation (as in FlashAttention); exploit CUDA Graphs; preallocate KV cache; custom backward pass
- Assumptions/dependencies: per-layer queries can be computed early (key property of layerwise RT vs. cross-layer feedback); careful numerical stability (online softmax); engineering required for Triton/CUDA kernels to achieve the speedups beyond PyTorch-only implementations
- Higher prefill throughput for long prompts in LLM serving
- Sectors: enterprise chat, customer support bots, productivity assistants
- Tools/workflows: plug the tiled prefill operator into serving stacks; benchmark long-context prompt ingestion (prefill) latency; combine with batching to maximize arithmetic intensity; use position-major KV layout for locality
- Assumptions/dependencies: gains grow with sequence length (N/log N intensity); kernel quality (fused ops, cache-friendly layout) strongly affects wins
- Energy/cost reductions via increased arithmetic intensity and reduced HBM traffic
- Sectors: cloud/energy management, sustainability programs
- Tools/workflows: roofline analysis to quantify bandwidth vs. compute limits; energy metering per training run; incorporate tiling and CUDA Graphs to reduce host dispatch overhead
- Assumptions/dependencies: actual savings depend on hardware (e.g., H100), sequence lengths, kernels, and utilization; holistic pipeline bottlenecks may dominate if not addressed (e.g., MLP batching)
- On-premise and resource-constrained deployments (lower memory and bandwidth demands)
- Sectors: healthcare (clinical NLP on hospital servers), education (school/on-campus compute), regulated industries (on-prem privacy)
- Tools/workflows: fine-tune RT models for domain tasks; deploy with reduced KV cache footprint and bandwidth; quantify TCO and privacy improvements from on-prem inference
- Assumptions/dependencies: domain adaptation needed; compliance/security requirements; edge kernels and quantization support (INT8/INT4) to fully realize on-device gains
- Improved synthetic diagnostics and research on temporal depth
- Sectors: academia, foundational ML research
- Tools/workflows: reuse MAD suite and copy-task diagnostics to probe effective temporal depth and recurrence; compare single-layer Transformer vs. RT; design new tasks isolating multi-hop reasoning
- Assumptions/dependencies: synthetic benchmarks may not directly translate to downstream tasks; still useful for understanding inductive biases
- Training system optimizations that generalize beyond RT
- Sectors: AI infra/compilers
- Tools/workflows: CUDA Graphs for short kernel sequences; activation checkpointing optimized for RT (recompute persistent KV in parallel); position-major KV cache layout for locality; custom backward to avoid in-place/autograd conflicts
- Assumptions/dependencies: compiler/runtime support; memory headroom for checkpointing; careful scheduling to interleave MLP and attention
Long-Term Applications
- Scaling RT to multi-billion parameter models with long context windows
- Sectors: foundation models, cloud AI
- Tools/products: RT-based 1–70B model families; long-context RT variants; mixture-of-experts RT (MoE-RT) for efficient capacity scaling
- Assumptions/dependencies: large-scale stability/quality to be established; kernel-level optimizations and memory planning for multi-GPU training; robust prefill/serve pipelines
- Hardware–software co-design for tiled attention and on-chip KV reuse
- Sectors: semiconductors, cloud hardware, compilers
- Tools/products: compiler passes that schedule interleaved MLP/attention; on-chip cache orchestration for KV tiles; PIM/near-memory features targeting Θ(N log N) traffic; native ops in cuDNN/MLIR/Triton for RT tiling
- Assumptions/dependencies: vendor adoption; standardized APIs; quantized/fused RT ops for NPUs and mobile accelerators
- Multimodal and streaming RT (speech/video/robotics)
- Sectors: speech ASR/translation, video understanding, robotics (policy learning, planning)
- Tools/products: RT-AV (audio-visual) layers for streaming inputs; RNN-like token-to-token iterative updates within attention for temporal reasoning; low-latency controllers leveraging per-layer recurrence
- Assumptions/dependencies: architecture tailoring for modality-specific encoders; datasets with long temporal structure; latency-critical kernels on edge devices
- Edge/mobile LLMs with smaller KV caches and improved battery efficiency
- Sectors: mobile, embedded systems, consumer devices
- Tools/products: 1–7B RT-LLMs optimized for mobile NPUs; quantization-aware training (QAT) for RT; mobile-friendly tiled prefill operators
- Assumptions/dependencies: robust INT8/INT4 kernels for RT; memory- and bandwidth-aware schedulers; on-device security constraints
- Theory and methods for stable deep-in-time training
- Sectors: academia, applied research
- Tools/workflows: principled normalization and residual-scaling for recurrent attention; adaptive residual gating; formal guarantees on gradient behavior; curricula emphasizing iterative computation
- Assumptions/dependencies: extension of the paper’s simplified analysis (Theorem 1) to richer settings; empirical validation across tasks and scales
- Standardization of tiled prefill attention operators in major frameworks
- Sectors: AI tooling ecosystem
- Tools/products: “RTFlashTileAttention” operator (exact, IO-aware) in PyTorch/TensorFlow/JAX; autograd-friendly APIs; scheduler hooks to interleave attention and MLP
- Assumptions/dependencies: community and vendor adoption; numerical stability and determinism guarantees; portability across GPUs/NPUs
- Memory/bandwidth-aware serving and training schedulers
- Sectors: cloud serving, MLOps
- Tools/products: schedulers that pick depth–width configurations per workload; multi-tenant bandwidth management; KV cache partitioning strategies exploiting RT’s smaller footprint
- Assumptions/dependencies: telemetry and cost models for HBM traffic; compatibility with batching/streaming; SLA-driven policy mechanisms
- Policy and procurement standards for energy-efficient AI
- Sectors: public policy, enterprise procurement, sustainability
- Tools/products: reporting guidelines for HBM traffic and arithmetic intensity; carbon labels for training/prefill; incentives for IO-aware architectures like RT
- Assumptions/dependencies: consensus on measurement protocols; access to energy telemetry; alignment with regulatory frameworks
- Program synthesis and algorithmic reasoning using within-layer iterative computation
- Sectors: code assistants, formal methods
- Tools/products: training curricula that encourage token-to-token recurrence (e.g., local attention biases) for algorithmic tasks; hybrid RT+gated recurrence for controllable iterative reasoning
- Assumptions/dependencies: evidence at scale that RT’s temporal depth yields better algorithmic generalization; task design and evaluation protocols
- Privacy-preserving, on-device AI in sensitive domains
- Sectors: healthcare, finance, government
- Tools/products: RT models that meet accuracy with reduced memory bandwidth; edge deployments minimizing data exfiltration; model governance with energy and privacy audits
- Assumptions/dependencies: strong domain fine-tuning; compliance validation; hardware support for secure enclaves and quantized RT ops
These applications build directly on three core contributions: layerwise recurrent keys/values (greater effective temporal depth without capped memory), an exact tiling schedule for prefill/training (from Θ(N2) to Θ(N log N) HBM traffic), and demonstrated depth–width tradeoffs (fewer layers at fixed parameters with improved or comparable cross-entropy), together with practical engineering enablers (CUDA Graphs, KV layout, custom backward, activation checkpointing).
Glossary
- Activation checkpointing: A memory-saving technique that trades extra compute for reduced activation storage by recomputing intermediates during backpropagation. "We therefore rely on activation checkpointing."
- Arithmetic intensity: The ratio of floating-point operations to bytes moved; higher values indicate better compute utilization relative to memory bandwidth. "increasing effective arithmetic intensity to "
- Autograd: An automatic differentiation system (here, PyTorch’s) that records operations to compute gradients. "Since PyTorch autograd is not compatible with in-place operations, we implement a custom backward pass."
- Autoregressive decoding: Sequential generation where each new token conditions on previously generated tokens. "preserving standard autoregressive decoding cost."
- Causal decoder-only Transformer: A Transformer variant that uses only decoder blocks with a causal mask to prevent attention to future tokens. "We first recall a standard causal decoder-only Transformer layer~\citep{vaswani2017attention}."
- Chinchilla tokens: A data budget scale derived from Chinchilla scaling laws indicating token counts for efficient training. "for Chinchilla tokens ( tokens)."
- Cross-entropy: A loss measuring the divergence between predicted and true distributions; commonly used in language modeling. "improve cross-entropy over a parameter-matched Transformer baseline"
- CUDA Graphs: A mechanism to capture and replay GPU workloads with minimal launch overhead for better performance. "we use CUDA Graphs, recording the full forward (and backward) pass computation and replaying it with a single launch."
- Depth–width tradeoff: The design balance between stacking more layers (depth) and increasing hidden dimensionality (width) at fixed parameters. "favorable depth--width tradeoffs at fixed parameter count (as shown in Figure \ref{fig:c4-300m})."
- Directed computation graph: A representation of forward dependencies as a directed graph where nodes are computations and edges indicate data flow. "Viewing the model as a directed computation graph over positions,"
- Feedback Transformer: A Transformer variant that uses a shared memory across layers to introduce feedback. "This differs from the Feedback Transformer~\citep{fan2020feedback}"
- Flash Inference: An inference scheduling approach that improves memory locality and reuse during decoding-like computations. "in the spirit of Flash Inference \citep{flashInference}"
- HBM (High-bandwidth memory): High-throughput GPU memory whose traffic can bottleneck performance. "reducing high-bandwidth memory (HBM) traffic from to "
- Key–value (KV) pairs: The stored pairs in attention over which queries aggregate information. "where each layer attends to key--value pairs computed off its own activations"
- KV cache: The stored keys and values from past tokens used to speed up autoregressive decoding. "reducing KV cache memory footprint and inference latency."
- Layerwise recurrent memory: A design where each layer maintains its own persistent key–value memory updated from its outputs. "yielding layerwise recurrent memory while preserving standard autoregressive decoding cost."
- MLP (feedforward block): The per-position feedforward sublayer in a Transformer, typically interleaved with attention. "the MLP computations must be interleaved with it"
- Online softmax: A numerically stable technique to accumulate softmax outputs across tiles by maintaining running maxima and normalizers. "we maintain the same online softmax statistics as \citep{rabe2021blockAttention,dao2022flashattention}"
- Orthonormal initialization: Initializing weight matrices with orthonormal columns/rows to stabilize training dynamics. "for orthonormal initialization, for any , we expect to be in this regime."
- Positional embeddings (or biases): Encodings injected to represent token positions and bias attention patterns. "If, using positional embeddings or biases, attention concentrates locally to the previous position,"
- Prefill: The phase where the model processes a context sequence (e.g., during training or before decoding) to populate caches. "A naive implementation of Recurrent Transformer training/prefill is sequential in position"
- Pre-LN (Pre-Layer Normalization): A Transformer variant applying normalization before sublayers to improve optimization. "we use pre-LN~\cite{xiong2020layerPreLN}"
- Query/key normalization (QK-Norm): Normalization applied to queries/keys to stabilize attention score magnitudes. "query/key normalization~\citep{dehghani2023scalingQKNorm}"
- Residual scaling (depth-wise): Scaling residual branch contributions (often by 1/√L) to stabilize deep networks. "standard depth-wise residual scaling \citep{bordelon2023depthwise,yang2023tensor}"
- RMSNorm (Root Mean Square normalization): A normalization technique that rescales activations based on their root-mean-square. "Root Mean Square normalization \citep{RMSNorm}"
- Roofline model: A performance model relating peak compute, memory bandwidth, and arithmetic intensity to bound throughput. "under the Roofline model \citep{williams2009roofline}"
- Staircase Attention: A feedback-style attention mechanism exploring recurrent processing and caching variants. "Staircase Attention~\citep{ju2021staircase}"
- State-space models: Sequence models that evolve a fixed-dimensional hidden state recurrently over time. "Classical RNNs and modern state-space models maintain a fixed-size state that is updated recurrently"
- TC0 (circuit class): A class of constant-depth, polynomial-size Boolean circuits with majority gates; used to characterize model expressivity limits. "bound to TC0 - a class of shallow circuits~\citep{merrill2022saturated}"
- Tensor parallelism: A parallelization strategy that splits model tensors across devices to scale width efficiently. "using techniques such as tensor parallelism."
- Tiling (schedule): Partitioning computation into blocks to improve data reuse and reduce memory traffic. "an exact tiling-based algorithm that preserves the mathematical attention computation"
- Token-to-token recurrent computation: Computation where each token’s update depends primarily on the immediately preceding token, akin to RNNs. "token-to-token recurrent computation via attention concentration under mild assumptions."
- Transformer-XL: A Transformer variant that processes long contexts in segments while reusing state between them. "Transformer-XL and follow-ups process context in segments"
- TransformerFAM: A Transformer with feedback attention memory that reads/writes a bounded state per layer. "TransformerFAM~\citep{hwang2024transformerfam} is closer in that it also operates independently at each layer"
- Vanishing and exploding gradients: Training pathologies where gradients shrink or grow exponentially along long dependency chains. "vanishing and exploding gradient phenomena \citep{bengio1994long,pascanu2013difficulty}"
Collections
Sign up for free to add this paper to one or more collections.