Spatial-TTT: Streaming Visual-based Spatial Intelligence with Test-Time Training
Abstract: Humans perceive and understand real-world spaces through a stream of visual observations. Therefore, the ability to streamingly maintain and update spatial evidence from potentially unbounded video streams is essential for spatial intelligence. The core challenge is not simply longer context windows but how spatial information is selected, organized, and retained over time. In this paper, we propose Spatial-TTT towards streaming visual-based spatial intelligence with test-time training (TTT), which adapts a subset of parameters (fast weights) to capture and organize spatial evidence over long-horizon scene videos. Specifically, we design a hybrid architecture and adopt large-chunk updates parallel with sliding-window attention for efficient spatial video processing. To further promote spatial awareness, we introduce a spatial-predictive mechanism applied to TTT layers with 3D spatiotemporal convolution, which encourages the model to capture geometric correspondence and temporal continuity across frames. Beyond architecture design, we construct a dataset with dense 3D spatial descriptions, which guides the model to update its fast weights to memorize and organize global 3D spatial signals in a structured manner. Extensive experiments demonstrate that Spatial-TTT improves long-horizon spatial understanding and achieves state-of-the-art performance on video spatial benchmarks. Project page: https://liuff19.github.io/Spatial-TTT.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching AI to understand spaces over time—like figuring out where objects are, how big rooms are, and how things relate to each other—by watching long videos. The authors built a system called Spatial-TTT that can “remember” and update what it knows while it watches a video, so it can answer questions about the 3D world, even when the camera moves and the scene changes.
What questions did the researchers ask?
They focused on three simple questions:
- How can an AI keep track of where things are in a room while watching a long video, not just a few seconds?
- How can it keep the most useful spatial information (like object locations and sizes) without running out of memory or forgetting earlier parts?
- Can this approach beat other models on tasks that test real spatial understanding, such as counting objects across long clips or planning routes?
How did they do it?
Think of the AI like a person exploring a house with a notebook:
- When it sees new parts of the house, it updates notes instead of trying to remember every single frame.
- It keeps a moving “window” of recent details plus a compact summary of the past, so it doesn’t forget important things.
Here’s how their method works in everyday terms:
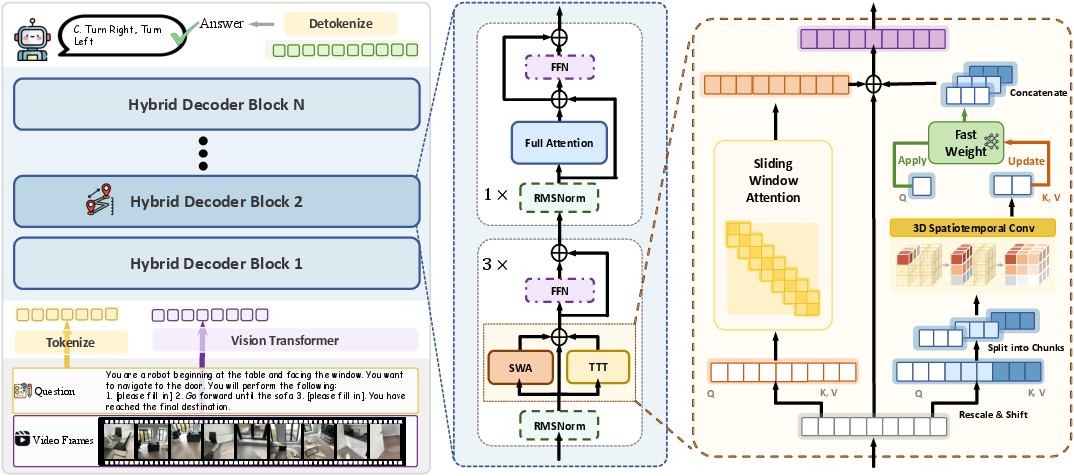
- Test-Time Training (TTT) as a scratchpad: Instead of freezing the model at test time, the system updates a small set of fast-changing “scratchpad weights” while it watches the video. These fast weights act like a notebook: they store and organize new spatial clues on the fly so the model can use them later to answer questions.
- Hybrid layers: the best of both worlds:
- Regular attention layers (anchor layers) that keep the model’s general knowledge and language skills.
- TTT layers that compress long stretches of video into a compact memory, helping it handle long videos efficiently.
- This mix keeps the model smart about language while making it better at long-term spatial memory.
- Large chunks + sliding window: Instead of updating the notebook every tiny step (which is slow and choppy), the model updates in larger “chunks,” like reading and summarizing a few pages at a time. At the same time, it uses a sliding window of nearby frames so it doesn’t lose smoothness across time—like flipping between recent pages to keep the story straight.
- Spatial-predictive mechanism (seeing neighbors): The model doesn’t just look at each video token (tiny piece of an image) alone. It uses small 3D filters (like looking at nearby pixels across space and time) so it better understands how objects move and how different views fit together. This helps it track geometry and continuity—think “this chair here is the same chair I saw a moment ago from another angle.”
- Training with dense scene descriptions: Most datasets ask tiny questions (“How many chairs?”). That’s helpful, but it doesn’t train the model to remember the whole room. So the authors built a dataset where the model must write rich, structured scene descriptions: the room type, objects and counts, and how things are arranged. This is like a teacher asking, “Describe the whole room in detail,” not just “What color is the couch?” It trains the model to build a full mental map.
- Two training stages: 1) First, train the model to build strong global spatial memory using those detailed room descriptions. 2) Then fine-tune it on many spatial Q&A tasks (counting, distances, directions, planning routes) so it can recall and reason over what it stored.
What did they find, and why is it important?
- Stronger performance on spatial tests:
- VSI-Bench (egocentric video spatial questions): best overall performance.
- MindCube (viewpoint changes and occlusions): clearly better than both open-source and proprietary baselines.
- VSI-SUPER (very long videos: recall and counting): performed well even as videos got very long, especially for continual counting across long time spans.
- Works on long videos without choking: Many models slow down or run out of memory on long videos because attention grows too fast with input length. Spatial-TTT uses its “notebook” idea to keep memory and compute close to growing linearly with video length, so it remains efficient and stable.
- Small model, big gains: Even with a relatively small base model (about 2B parameters), Spatial-TTT outperformed larger and well-known models on spatial tasks. This shows that smart memory design and training can matter more than just making models bigger.
Why it matters: Being able to understand space over time is crucial for robots, AR glasses, and autonomous systems. They need to know where things are, how they move, and how to navigate—often from continuous, moving-camera video, not single snapshots.
What’s the bigger impact?
- Smarter, safer navigation and interaction: Robots and assistants could better map rooms, remember what they’ve seen, and plan paths or actions more reliably.
- Better long-horizon understanding: This approach shows how to handle long input streams (like hours of video) without losing track or blowing up memory. That can help many tasks beyond spatial reasoning.
- A step toward active perception: By updating its internal memory while watching, the model acts more like a human observer—selecting, organizing, and retaining important details as it goes.
In short, Spatial-TTT teaches AI to build and maintain a living “mental map” of the world while it watches, making it better at answering where things are and how they relate—exactly the kind of skill real-world systems need.
Knowledge Gaps
Open Questions, Limitations, and Knowledge Gaps
Below is a single consolidated list of concrete gaps and unresolved questions that future work could address:
- Test-time objective is unspecified: the paper does not define the exact self-/unsupervised loss used to compute gradients for fast-weight updates at inference (e.g., next-token likelihood, masked prediction, contrastive, temporal consistency), nor how it is computed on video tokens without labels and aligned with spatial goals.
- Stability and convergence of TTT over long streams: no analysis of drift, catastrophic forgetting, or error accumulation in fast weights across hours-long inputs; no reset/regularization strategies or guarantees reported.
- Latency and energy costs: wall-clock throughput, per-chunk backward-pass latency, and energy usage across hardware (A100/H100, consumer GPUs) are not measured; real-time feasibility at typical frame rates (e.g., 10–30 fps) is unclear.
- Memory footprint of the fast-weight branch: size and scaling of fast weights per layer/head are not quantified; initialization and reset policies across sessions are not specified.
- Sensitivity to key hyperparameters: no ablations on chunk size b, window size w, annealing schedule, TTT:anchor layer ratio (fixed at 3:1), learning rates, Muon optimizer settings, and number of update steps per chunk.
- Missing “no-TTT” training control: there is no baseline trained on the same dense scene-description + 3M spatial QA data with full attention (no TTT), making it hard to disentangle gains from architecture vs. additional data.
- Scope and coverage of training data: dense descriptions (≈16k) and much of the 3M spatial QA are indoor-centric (ScanNet/ARKitScenes); generalization to outdoor scenes, dynamic crowds, deformable objects, and adverse conditions is untested.
- Distribution shift and robustness: no controlled evaluations under occlusion, motion blur, low light, camera shake, compression artifacts, or sensor noise.
- Frame rate and duration scaling: results on VSI-SUPER use 1 fps and max 120 minutes; behavior at higher fps (10–30) and day-long or continuous streams remains unknown.
- Handling multi-question streaming: the system is not evaluated for interactive settings with multiple queries interleaved during the stream or mid-video question timing.
- Loop-closure and re-visitation: ability to re-localize and recall previously seen objects/rooms, deduplicate counts, and maintain consistent maps over revisits is not studied.
- Interpretability and diagnostics: no tools or probes to inspect what fast weights store (e.g., objects, layout, metric cues) or to visualize memory content and failure modes.
- Privacy and safety: TTT memory may inadvertently store sensitive visual information; retention/erasure policies, privacy controls, and safety constraints are not addressed.
- Combining TTT with explicit geometry: while the method avoids explicit depth/pose, it does not explore integration with metric depth, SLAM, or NeRF-derived features, nor analyze complementarity vs. redundancy.
- Spatial-predictive mechanism design space: only depthwise 3D conv with 3×3×3 kernels is used; effects of kernel sizes, dilation, separable vs. grouped convs, local attention, and learned receptive fields are not ablated.
- Token-grid assumption: the approach reshapes tokens to a spatiotemporal grid; handling variable resolutions/aspect ratios, patch dropping, sparse/object tokens, or irregular sampling is not detailed.
- Interaction between SWA and TTT branches: outputs are summed without learned gating; trade-offs, potential double-counting, and learned mixture strategies are not evaluated.
- Model scaling: results are reported for a 2B base; whether gains persist, shrink, or improve at 7B/72B scales and the corresponding cost/benefit trade-offs remain open.
- Update rule alternatives: only Muon is evaluated; comparisons to Adam/SGD, orthogonal gradient projection variants, Hebbian/linear fast weights, learned optimizers, or optimizer-free meta-updates are missing.
- Reset and continual learning across sessions: policies for when and how to reset fast weights between videos, and potential for safe cross-session continual learning, are unspecified.
- Streaming supervision alignment: how the dense scene-description pretraining shapes test-time update behavior is not quantified; causal connections between dense targets and improved long-horizon recall are not measured.
- Benchmark breadth: MindCube evaluation uses the Tiny subset; performance on the full benchmark and additional spatial suites (e.g., embodied navigation, long-term object permanence) is not reported.
- Downstream embodied tasks: no closed-loop evaluations in robotics/AR (e.g., navigation, pick-and-place, route execution) to validate that the learned spatial memory translates to action.
- Fairness and contamination: data curation details for the 3M QA (licenses, synthetic vs. real, filtering, overlap with test sets) are relegated to Supplementary; potential benchmark leakage is not ruled out.
- Resource analysis is incomplete: the memory/TFLOPs table is truncated and lacks end-to-end throughput numbers, batch size impacts, and resolution scaling curves.
- Multi-modality extension: integration with depth, IMU, LiDAR, audio, or language-driven memory control is not explored; whether language prompts can steer which spatial evidence is retained is an open design point.
- Handling moving agents and physical dynamics: reasoning about interactions, articulated objects, and non-rigid motion is not explicitly targeted or evaluated.
Practical Applications
Overview
Spatial-TTT introduces a streaming visual-spatial intelligence framework that:
- Maintains a compact, adaptive “fast-weight” memory updated online (test-time training) to accumulate 3D evidence from long videos.
- Uses a hybrid architecture (interleaving TTT layers with anchor self-attention) and a large-chunk + sliding-window attention pipeline for efficient long-horizon processing.
- Adds a spatial-predictive mechanism (depthwise 3D spatiotemporal convolutions on Q/K/V) to better capture geometric correspondence and temporal continuity.
- Trains with dense 3D scene descriptions to supervise the formation of persistent, structured spatial memory.
This enables robust spatial reasoning over hours-long egocentric videos with near-linear compute/memory scaling, achieving strong results on spatial benchmarks (VSI-Bench, MindCube-Tiny, VSI-SUPER).
Below are practical applications derived from these findings, organized by time-to-deployability.
Immediate Applications
The following can be implemented with existing models/hardware and modest engineering integration, leveraging Spatial-TTT’s current capabilities and efficiency.
- Spatial memory SDK for long-video analytics (Software/AI tooling)
- What: An SDK that offers streaming spatial Q&A, counting, relative direction/distance queries, event order recall, and global scene descriptions from long egocentric or fixed cameras.
- Tools/workflows:
- A Python/C++ API exposing chunked streaming ingestion, dual KV caches, and on-the-fly fast-weight updates.
- Integrations with OpenVINO/TensorRT for edge acceleration; REST/grpc microservices for on-prem/cloud deployments.
- Assumptions/dependencies:
- Base MLLM weights (e.g., Qwen3-VL-2B-derived) and Spatial-TTT layers available.
- Sufficient edge/GPU compute for ~1–5 fps processing; calibrated chunk/window sizes per device.
- Retail shelf auditing and perpetual counting (Retail)
- What: Continuous on-shelf object counting, planogram checks, and stock-out detection across hours with occlusions and camera motion.
- Tools/workflows:
- Ceiling cams/bodycams feed → Spatial-TTT counting module → real-time dashboard alerts.
- Integration with planogram databases; APIs to store long-horizon counts per SKU/location.
- Assumptions/dependencies:
- Domain adaptation for store layouts/products; privacy-compliant video capture.
- Frame-rate throttling or batching to match edge compute constraints.
- Warehouse and factory inventory sensing (Logistics/Manufacturing/Robotics)
- What: Persistent counts, object location/relations, and order-of-appearance logging for pallets, totes, tools.
- Tools/workflows:
- ROS2 node publishing “scene memory” (objects, counts, relations) to planning/localization stacks.
- Operator bodycam or AMR camera feeds processed online; APIs to WMS/MES.
- Assumptions/dependencies:
- Indoor-focused training may require fine-tuning for industrial environments and safety gear.
- Stable camera parameters or IMU/odometry help but aren’t strictly required.
- AR scene narration and spatial Q&A (AR/VR, Accessibility, Education)
- What: On-device room description (type, size), object listings and counts, and relative directions for AR glasses or smartphones.
- Tools/workflows:
- ARKit/ARCore plugin that streams frames to an on-device Spatial-TTT engine; voice-based Q&A.
- Use dense scene descriptions for accessible navigation or STEM education.
- Assumptions/dependencies:
- Mobile acceleration (NNAPI/Metal) and model compression or offloading to edge server.
- Latency budget depends on fps and chunk size; 1–3 fps feasible today.
- Facility inspection and documentation (AEC/Facility Management)
- What: Automated room-size estimation, asset enumeration, and spatial relation summaries for as-built documentation.
- Tools/workflows:
- Walkthrough video → structured “scene walkthrough” text + JSON schema (objects, counts, pairwise relations).
- Export to BIM tools (e.g., IFC tagging) or CMMS.
- Assumptions/dependencies:
- Indoors bias aligns well; may need calibration for varying lenses and motion blur.
- QA via human-in-the-loop for high-stakes compliance.
- Security and loss-prevention video summarization (Security/Operations)
- What: Long-horizon recall of object appearances, order of events, and spatial relations to reduce manual video review.
- Tools/workflows:
- Streaming ingestion from NVR → event/sequence summarization with timestamped spatial facts.
- Policy-defined retention with privacy by design (on-prem, encrypted, face-blur).
- Assumptions/dependencies:
- Legal/privacy alignment; careful logging of test-time model state for auditability.
- Domain adaptation to lighting, camera angles.
- Sports and gym analytics (Media/Wellness)
- What: Persistent counting (reps, equipment usage) and spatial relation summaries (who was where) from long recordings.
- Tools/workflows:
- In-venue cameras → real-time counters and spatial summaries displayed on dashboards.
- Assumptions/dependencies:
- Calibration for field-of-view and rapid motion; sampling strategies to fit compute budgets.
- Drone and handheld inspection counting (Energy/Utilities/Infrastructure)
- What: Maintain counts/locations of panels/meters/valves across flights/walkthroughs with occlusions and revisits.
- Tools/workflows:
- Drone/bodycam streams → Spatial-TTT memory → inspection report with counts and relations.
- Assumptions/dependencies:
- Outdoor generalization may require fine-tuning; variable lighting/weather; flight stabilization.
Long-Term Applications
These require further research, scaling, multi-sensor integration, or broader productization and regulation.
- Lifelong spatial memory for embodied agents (Robotics, Smart Home)
- What: Home/office robots that maintain persistent, cross-session spatial memory to find, count, and manipulate objects under changing layouts.
- Tools/products:
- “Spatial-TTT world model” fused with SLAM/SDF map and a task planner; cross-session persistence with memory replay.
- Dependencies/assumptions:
- Multi-sensor fusion (RGB-D/LiDAR), robust re-localization, safety certifications; catastrophic-forgetting controls for test-time updates.
- Fleet-scale digital twins updated from video (Smart Buildings/Cities)
- What: Continually updated digital twins with object inventories and spatial constraints learned from distributed cameras.
- Tools/products:
- Edge-deployed Spatial-TTT nodes + central knowledge graph; APIs for BIM, maintenance, and analytics.
- Dependencies/assumptions:
- Data governance, privacy, and interoperability standards; cross-building generalization and drift monitoring.
- AR “persistent understanding” across sessions (AR Cloud)
- What: AR devices that remember spatial layouts and object relations across days, enabling stable anchoring, navigation, and collaborative tasks.
- Tools/products:
- Cloud-backed spatial memory service with identity tracking and versioning; shared anchors for multi-user scenarios.
- Dependencies/assumptions:
- Robust identity persistence and re-association; low-latency sync; privacy-preserving identity schemas.
- Spatial copilot for surgeons and clinicians (Healthcare)
- What: OR/ward assistants that recall instrument counts, room layout, and item placement over long procedures.
- Tools/products:
- Sterile OR camera integration; HUD/voice guidance; EHR/asset tracking linkage.
- Dependencies/assumptions:
- Clinical-grade validation, reliability, and explainability; secure on-prem deployment and regulatory clearance.
- Advanced autonomous driving spatial reasoning (Mobility)
- What: Long-horizon occlusion reasoning, object recall, and route context memory in complex environments.
- Tools/products:
- Spatial-TTT fused with LiDAR/radar and HD maps; supports rare-event handling and long-term context.
- Dependencies/assumptions:
- Outdoor domain shift; multi-sensor alignment; adversarial robustness; stringent safety requirements.
- Proactive safety and compliance monitoring (Policy/Public sector)
- What: Systems that continuously track safety equipment presence, occupancy constraints, or evacuation routes over long spans.
- Tools/products:
- Policy dashboards that quantify compliance with spatial memory back-ends and audit trails.
- Dependencies/assumptions:
- Standards for logging test-time adaptations; certification programs for streaming AI.
- Personal assistance for the visually impaired with lifelong context (Daily life/Accessibility)
- What: Assistants that remember home/work layouts, item locations, and changes over time to guide users.
- Tools/products:
- Wearable camera → on-device Spatial-TTT → audio guidance with object/route memory.
- Dependencies/assumptions:
- Strong on-device compute or efficient distillation; privacy guarantees; personalization safeguards.
- Multi-sensor spatial foundation models (Research/Academia)
- What: Extending Spatial-TTT to fuse RGB, depth, IMU, and event cameras for more stable and metric-accurate memory.
- Tools/workflows:
- Benchmarks for streaming fusion; layerwise fast-weight adaptation policies; self-supervised objectives tailored to geometry.
- Dependencies/assumptions:
- New datasets with dense multi-sensor labels; standardized evaluation for streaming spatial reasoning.
- Regulation and benchmarking of streaming spatial AI (Policy/Standards)
- What: Standards for performance, safety, privacy, and logging for models that adapt weights at inference.
- Tools/workflows:
- Certification suites based on VSI-Bench/VSI-SUPER-like tasks; reproducibility protocols for TTT updates.
- Dependencies/assumptions:
- Cross-industry consensus on transparency of online weight updates and retention policies.
- Content production and analytics at scale (Media/Sports)
- What: Automated, semantics-rich spatial summaries of long games/shows, tactical analyses, and storyline maps.
- Tools/products:
- “Spatial storylines” timelines extracted via streaming memory with entity/scene graphs.
- Dependencies/assumptions:
- Robust identity tracking across cameras and sessions; rights management and data sharing rules.
Notes on feasibility across applications:
- Domain shift: The model is trained primarily on indoor, egocentric data; outdoor/industrial/medical deployments will need adaptation.
- Compute/latency: Spatial-TTT is efficient versus quadratic attention, but real-time high-fps or high-res requires optimization (quantization, distillation, accelerator-specific kernels).
- Privacy/compliance: Streaming adaptation on live video necessitates on-device or on-premise processing, audit logs of fast-weight updates, and adherence to privacy regulations.
- Stability and safety: Test-time training must include safeguards against drift/adversarial inputs (e.g., bounded update rules, rollback, monitoring).
- Tooling maturity: Production-grade implementations benefit from packaged ROS2 nodes, AR SDK plugins, and standardized JSON schemas for scene graphs and counts.
Glossary
- Anchor layers: Self-attention layers preserved in the model to maintain pretrained knowledge and full-context reasoning. Example: "self-attention anchor layers"
- Causal constraints: Restrictions that prevent tokens from accessing future information during updates to avoid leakage. Example: "causal constraints in TTT updates"
- Causal lower-triangular attention matrix: The masked attention structure allowing each token to attend only to past tokens. Example: "the causal lower-triangular attention matrix within each chunk"
- Constant-memory streaming: Processing long streams with bounded memory via caching and chunked updates. Example: "constant-memory streaming"
- Cross-modal alignment: Consistent mapping between visual and textual representations in multimodal models. Example: "cross-modal alignment"
- Depth-wise 3D spatiotemporal convolutions: Channel-wise convolutions across space and time that aggregate local neighborhoods for tokens. Example: "depth-wise 3D spatiotemporal convolutions"
- Dirac-initialized: Initialization of convolution kernels as identity mappings using Dirac delta to preserve initial behavior. Example: "Dirac-initialized"
- Egocentric (video understanding): First-person viewpoint video understanding emphasizing what the observer sees. Example: "egocentric video understanding"
- Fast weights: Adaptable subset of parameters updated online to serve as a compact memory of recent context. Example: "adaptive fast weights"
- Hybrid TTT architecture: Interleaving TTT layers with standard self-attention to balance adaptation and preserved reasoning. Example: "hybrid TTT architecture"
- KV cache: Stored key–value tensors used by attention to efficiently reuse past context. Example: "dual KV cache mechanism"
- LaCT: A large-chunk TTT update strategy that improves parallelism and hardware efficiency. Example: "The LaCT chunk size b is set to 2648"
- Large-chunk updates: Updating fast weights using large token chunks to enhance parallelism and coherence. Example: "large-chunk updates"
- Mean Relative Accuracy (MRA): A metric for numerical questions that measures prediction closeness relative to ground truth. Example: "Mean Relative Accuracy (MRA)"
- Metric grounding: The model’s ability to relate predictions to real-world geometry and distances. Example: "stronger metric grounding"
- Muon update rule: An optimizer-style update that uses momentum and gradient orthogonalization for stable fast-weight adaptation. Example: "Muon update rule"
- Newton-Schulz iterations: An iterative matrix method used here to orthogonalize gradients during updates. Example: "Newton-Schulz iterations"
- Object-centric 3D scene graphs: Structured representations of scenes capturing objects and their spatial relations in 3D. Example: "object-centric 3D scene graphs"
- Orthogonalized gradient: A gradient transformed to be orthogonal to certain directions to stabilize parameter updates. Example: "orthogonalized gradient"
- Point-wise linear projections: Independent linear mappings applied to each token to produce Q, K, and V without neighborhood context. Example: "point-wise linear projections"
- Sliding window annealing strategy: Training schedule that gradually reduces the attention window size to shift reliance onto TTT. Example: "sliding window annealing strategy"
- Sliding-window attention (SWA): Attention restricted to a fixed-size recent window to preserve local continuity efficiently. Example: "sliding-window attention (SWA)"
- Spatiotemporal grid: A 3D arrangement of tokens over time and space used to apply local operations. Example: "spatiotemporal grid"
- Spatiotemporal inductive bias: Architectural bias that encourages learning patterns across both space and time. Example: "injects spatiotemporal inductive bias directly into the TTT branch"
- Spatial-predictive mechanism: A module that aggregates local spatiotemporal context to improve predictive updates in TTT. Example: "spatial-predictive mechanism"
- Sublinear memory growth: Memory usage that increases slower than linearly with input length, enabling scalability. Example: "achieving sublinear memory growth"
- SwiGLU-MLP: An MLP using SiLU-gated linear units (SwiGLU) for expressive, non-linear transformations. Example: "SwiGLU-MLP"
- Test-Time Training (TTT): Paradigm that adapts a subset of model parameters during inference using unlabeled test data. Example: "Test-Time Training (TTT)"
- TTT pending KV cache: A buffer that accumulates key–value pairs until reaching the chunk size, then triggers a fast-weight update. Example: "TTT pending KV cache"
Collections
Sign up for free to add this paper to one or more collections.

