Near-Future Policy Optimization
Abstract: Reinforcement learning with verifiable rewards (RLVR) has become a core post-training recipe. Introducing suitable off-policy trajectories into on-policy exploration accelerates RLVR convergence and raises the performance ceiling, yet finding a source of such trajectories remains the key challenge. Existing mixed-policy methods either import trajectories from external teachers (high-quality but distributionally far) or replay past training trajectories (close but capped in quality), and neither simultaneously satisfies the strong enough (higher $Q$ , more new knowledge to learn) and close enough (lower $V$ , more readily absorbed) conditions required to maximize the effective learning signal $\mathcal{S} = Q/V$. We propose \textbf{N}ear-Future \textbf{P}olicy \textbf{O}ptimization (\textbf{NPO}), a simple mixed-policy scheme that learns from a policy's own near-future self: a later checkpoint from the same training run is a natural source of auxiliary trajectories that is both stronger than the current policy and closer than any external source, directly balancing trajectory quality against variance cost. We validate NPO through two manual interventions, early-stage bootstrapping and late-stage plateau breakthrough, and further propose \textbf{AutoNPO},an adaptive variant that automatically triggers interventions from online training signals and selects the guide checkpoint that maximizes $S$. On Qwen3-VL-8B-Instruct with GRPO, NPO improves average performance from 57.88 to 62.84, and AutoNPO pushes it to 63.15, raising the final performance ceiling while accelerating convergence.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
The paper introduces a new way to train reasoning AIs called Near-Future Policy Optimization (NPO). In simple terms, it helps a model learn by letting it peek at solutions produced by a slightly better, near-future version of itself. This “future self” gives just enough help to be useful without confusing the model. The authors also build an automatic version, AutoNPO, that decides when and how to use this help on its own.
What questions the paper tries to answer
The authors focus on two common training problems:
- Early in training: the model rarely gets answers right, so it doesn’t get much feedback to improve.
- Later in training: the model “gets stuck” on a plateau—its progress slows down because it keeps using the same habits and stops exploring new approaches.
Their main question: How can we add extra guidance that is strong enough to teach the model new things but still similar enough to what the model already does so training stays stable?
How they approached it (in everyday language)
Think of training as practicing math problems:
- “On-policy” learning = the student learns only from their own attempts.
- “Off-policy” learning = the student also studies other people’s solutions.
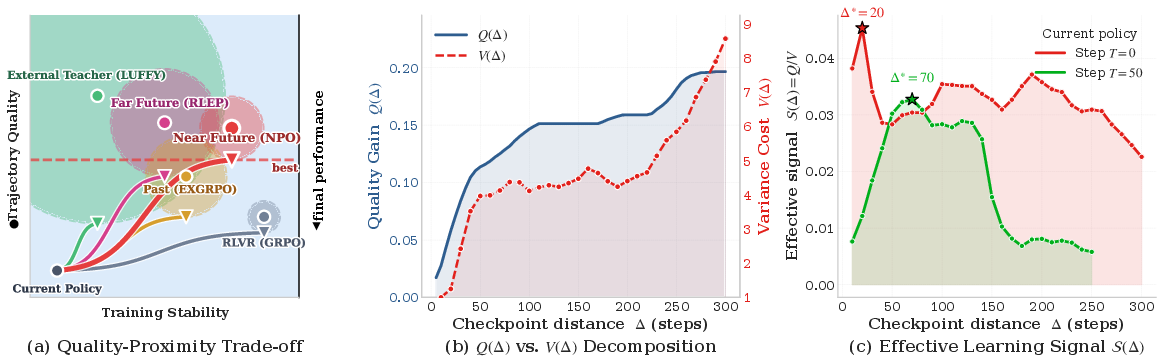
Both have trade-offs. Studying a very advanced student’s solutions can be high quality but too different, making it hard to absorb. Studying your own past work is familiar but not very helpful if it’s not much better.
The authors define two simple ideas:
- Quality (Q): how often the helper produces correct solutions the current model can’t.
- Variance (V): how much the helper’s style confuses the learner (the more different, the more confusion).
They combine these into “effective signal” S = Q / V. Good help has high Q and low V.
Their insight: the best helper is your near-future self—a checkpoint saved a little later in the same training run. It’s better (higher Q) but still very similar (low V). If you go too far into the future, quality may rise, but differences explode and training becomes unstable (V gets too big). So there’s a sweet spot.
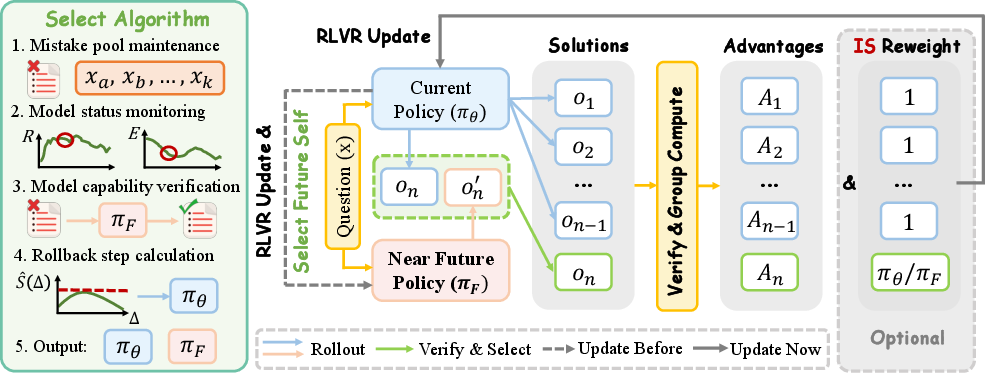
What NPO does in practice:
- For each question, the model makes several attempts.
- If it’s struggling on a question, NPO swaps in one extra attempt: a correct solution generated by a slightly later (near-future) version of the same model.
- Everything else in training stays the same. A “verifier” (like an answer checker) ensures only correct future solutions are used.
They test two simple, hand-run versions:
- Early bootstrapping: use a short “scout” training run to create a near-future helper for the rough early steps so learning gets started faster.
- Late breakthrough: continue training a bit past the plateau to get a stronger helper, then roll back and replay the plateau with help to break through.
Then they build AutoNPO, which automates the timing:
- It watches for warning signs like reward progress stalling and the model’s output variety shrinking (called “entropy”).
- It keeps a “mistake pool” (the questions the model recently got wrong).
- It estimates which rollback distance gives the best effective signal (best Q/V) and replays that window with near-future guidance only on the hard questions.
What they found and why it matters
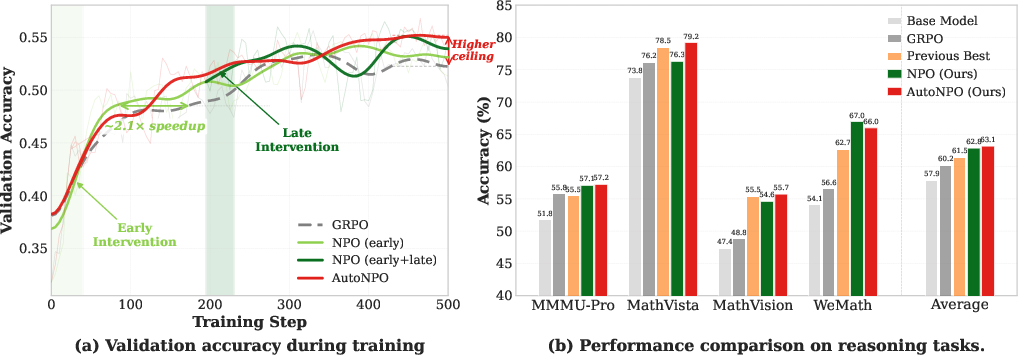
- Faster early learning: With early-stage help, training sped up by about 2.1×. That’s like learning the basics much quicker because you see just-in-time examples from your slightly better future self.
- Higher final performance: Using late-stage help, the model escaped the plateau and reached a higher “ceiling” than standard training.
- Consistent benchmark gains: On 8 tough multimodal reasoning tests (math with images, general visual understanding, etc.), NPO and AutoNPO beat the standard method (GRPO) and other strong baselines. For example, average accuracy increased from 57.88 (base) to 62.84 with NPO, and 63.15 with AutoNPO.
- Healthier training dynamics: AutoNPO kept the model’s “variety” (entropy) higher, preventing it from locking into narrow habits. This supported better late-stage performance.
- Simple and stable: Because the near-future helper is so similar to the current model, a technical correction (importance sampling) hardly mattered; removing it didn’t hurt results. That means NPO stays both effective and simple.
What this could change going forward
- Self-guided learning: Models can improve using their own future selves instead of relying on external teachers. That can reduce costs and avoid mismatches in style.
- Faster, steadier training: Well-timed near-future guidance speeds up learning and avoids getting stuck.
- Plug-and-play for many tasks: NPO doesn’t change the core training goal—it only swaps in one guided attempt when needed—so it can be added to existing systems.
- A broader “self-taught” direction: This work is part of a bigger idea: let AI systems learn from themselves in smart ways (using better context, better future selves, or parallel selves). NPO shows that “future-you teaching present-you” is a powerful, practical version of that.
In short, the paper shows that the best coach for a learning AI might be its own near-future self—just far enough ahead to teach something new, but close enough that the lessons stick.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, phrased to be actionable for future research.
- Theoretical tightness and scope of the variance bound: the claimed near-exponential growth of variance with checkpoint distance Δ is deferred to Appendix B; conditions under which the bound is tight, its dependence on optimizer, clipping, and group-relative advantages, and its extension beyond GRPO-style objectives are not established in the main text.
- Bias induced by dropping importance sampling (IS): while ablations show negligible performance impact when treating near-future trajectories as on-policy, the statistical bias, convergence properties, and failure modes of uncorrected updates are not quantified.
- Validity of per-token KL as a variance proxy: AutoNPO estimates V(Δ) via per-token KL; the correlation between this proxy and true gradient variance across models, tasks, and training regimes is not validated beyond a single setup.
- Uniqueness and stability of the interior optimum Δ: the existence of a unique Δ maximizing S(Δ)=Q/V is argued empirically; formal conditions guaranteeing unimodality and how Δ* evolves with training dynamics remain unproven.
- Sensitivity to hyperparameters: the impact of mix_policy_accuracy_threshold, number of rollouts n, clipping ranges, temperature, and gating strategy on stability and gains is not systematically explored.
- How many guidance slots to replace: only one slot in the rollout group is replaced; the effect of replacing multiple slots (trade-off between stronger signal and higher variance) is not studied.
- Robustness to verifier noise and partial credit: NPO relies on binary verified-correct trajectories; behavior under noisy verifiers, soft rewards, or tasks lacking verifiable signals is untested.
- Generality beyond multimodal math/knowledge tasks: results are limited to Qwen3-VL-8B-Instruct on eight multimodal benchmarks; transfer to text-only reasoning, code generation, scientific QA, and non-reasoning tasks is unknown.
- Model- and scale-robustness: applicability to different architectures (e.g., LLaMA, Mistral, Phi), parameter scales (small and very large models), and instruction vs. base checkpoints is not evaluated.
- Backbone dependence: NPO is instantiated on a GRPO-style RLVR; compatibility and gains with other RLVR variants (DAPO, GSPO, SAPO) and alternative RL objectives (e.g., token-level preference optimization) are not demonstrated.
- Compute and wall-clock accounting: the paper claims ~2.1× faster convergence but does not provide detailed accounting of added inference for cache generation, verifier runs, checkpointing, and replay vs. baselines under equal compute.
- Storage and systems overhead: frequent rollbacks and near-future cache generation imply nontrivial checkpoint storage, I/O, and orchestration complexity; scalability to long runs and large fleets is not analyzed.
- Fairness of baseline comparisons: it is unclear whether baselines (e.g., LUFFY, ExGRPO, RLEP) were given equivalent compute, verifier budgets, and hyperparameter tuning; compute-normalized comparisons are missing.
- Risk of overfitting to replayed segments: AutoNPO replays specific segments with targeted prompts from the mistake pool; potential for segment-level overfitting and its impact on out-of-segment generalization is not measured.
- Data overlap and contamination checks: no discussion of potential training–evaluation overlap between MMFineReason-123K and the evaluation benchmarks, nor of preventive decontamination.
- Exploration–exploitation trade-offs: while entropy increases post-intervention are shown, the long-term effects on exploration diversity and susceptibility to collapse with repeated interventions are not characterized.
- Failure modes when near-future gains are weak: if the optimization path stagnates (future checkpoints do not improve Q meaningfully), the behavior of NPO/AutoNPO and potential harm (e.g., wasted replay cycles) are not studied.
- Interaction with non-stationary reward/verifier drift: how NPO behaves when verifiers change over time or when reward signals are updated mid-training is unexplored.
- Curriculum effects of the mistake pool: the pool’s sampling, aging, and bias properties (e.g., repetitively focusing on certain failure types) and their influence on capability breadth are not analyzed.
- Diversity of guidance trajectories: the guidance cache keeps one verified trajectory per prompt; effects of maintaining multiple diverse correct solutions (to avoid solution-mode collapse) are not investigated.
- Δ-selection robustness: AutoNPO selects Δ via a single confirmation rollout; sensitivity to pool size, stochasticity, and noise in Q̂ and V̂, and the value of repeated or uncertainty-aware estimates are not tested.
- Intervention timing across domains: trigger criteria (EMA reward stagnation + entropy drop) may be task-specific; their precision/recall and robustness across tasks, data curricula, and reward landscapes are not established.
- Safety and reward hacking: introducing strong near-future signals may amplify verifier gaming; analyses of adversarial robustness, spurious shortcut learning, or safety constraint violations are absent.
- Compatibility with token-level self-distillation: the paper suggests future integration, but concrete designs, interference between sequence-level NPO and token-level distillation, and compute trade-offs are open.
- Extension beyond verifiable RLVR: applicability to RLHF or preference-based rewards without verifiers, and to settings with continuous or delayed rewards, remains an open question.
- Multi-task and continual learning: how NPO/AutoNPO operate under multi-task training, domain shifts, or continual learning (e.g., avoiding catastrophic forgetting during rollbacks/replays) is unaddressed.
- The effect of length/entropy filtering in cache building: optional filters are mentioned but not ablated; their impact on stability, learning speed, and final accuracy is unknown.
- Number and spacing of interventions: AutoNPO executes a “small number of windows,” but optimal frequency, duration, and cooldown scheduling are not investigated.
- Interaction with KL penalties or entropy regularization: experiments omit KL and entropy penalties; whether NPO’s benefits persist, amplify, or diminish when such regularizers are used is unknown.
- Evaluation breadth: gains are reported on accuracy; effects on calibration, reasoning trace faithfulness, answer consistency, and latency are not measured.
Practical Applications
Practical Applications of Near-Future Policy Optimization (NPO) and AutoNPO
Below are actionable, real-world applications derived from the paper’s methods and findings, grouped by deployment horizon. Each item notes relevant sectors, potential tools/workflows, and key assumptions/dependencies that affect feasibility.
Immediate Applications
These use cases can be implemented now with existing RL-with-verifiable-rewards (RLVR) pipelines and standard MLOps.
- NPO/AutoNPO plug-in for RLHF/RLVR training pipelines
- Sectors: software, AI platforms, cloud ML, education, finance, healthcare, robotics (for tasks with verifiable outcomes)
- What: Integrate NPO into GRPO- (or similar) based post-training to accelerate early learning and lift late-stage performance plateaus without changing the RL objective or verifiers.
- Tools/workflows:
- “NPO Guidance Cache” module (generate and verify near-future trajectories per prompt)
- “AutoNPO Controller” (monitor reward stagnation/entropy drop, maintain mistake pool, choose rollback distance by estimating S(Δ) = Q/V)
- Training orchestration support for rollback/replay and checkpoint management
- Assumptions/dependencies:
- Availability of verifiable rewards and prompt-level validators
- Ability to checkpoint, fast-forward for guide generation, then rollback for replay
- Compute/storage to maintain near-future checkpoints and caches
- Faster and more stable enterprise LLM fine-tuning for reasoning-heavy products
- Sectors: software (code assistants, planning agents), finance (report analysis, risk checks), legal (contract review), education (tutor systems), customer support (decision trees), multimodal document understanding (forms, invoices)
- What: Reduce variance when mixing in auxiliary trajectories by using near-future “self” instead of external teachers; yields faster convergence (~2.1× reported) and higher pass@1 on complex reasoning tasks.
- Tools/workflows:
- Swap external-teacher mixing with near-future guidance in existing GRPO jobs
- Mistake-pool driven targeted replay for “hard” prompts
- Assumptions/dependencies:
- Reasoning tasks must have deterministic/verifiable graders (e.g., programmatic checkers, rule-based validators)
- Multimodal product improvements in vision+language reasoning
- Sectors: e-commerce (product QA with images), insurance (claim triage from photos+forms), healthcare ops (intake forms/image triage; non-diagnostic), education (diagram-based math tutoring), robotics (VLM-based task parsing)
- What: Deploy NPO in training multimodal LLMs (as demonstrated on Qwen3-VL-8B benchmarks) to improve accuracy on visually grounded reasoning while maintaining exploration diversity.
- Tools/workflows:
- Benchmark-driven NPO segments (early bootstrapping + late plateau interventions) in model release cycles
- Assumptions/dependencies:
- High-quality multimodal verifiers (e.g., numerical answer checkers; structured extraction validators)
- Sufficient GPU memory/IO for storing and reusing visual token logs
- Safer, more compliant training when external data or teachers are restricted
- Sectors: finance, healthcare, government, enterprises with strict data/IP constraints
- What: Reduce reliance on external teacher trajectories by learning from the model’s near-future self; mitigates data sharing/IP concerns and simplifies audits.
- Tools/workflows:
- Internal-only self-teaching with lineage tracking (checkpoint IDs, replay windows, intervention logs)
- Assumptions/dependencies:
- Internal governance practices for audit trails
- RLVR-compatible tasks with verifiers encoding domain constraints
- Turnkey “AutoNPO for MLOps” monitoring and intervention
- Sectors: cloud ML platforms, internal ML infra teams
- What: Productionize AutoNPO as a training monitor that triggers limited-duration guided replays when exploration collapses (reward stagnation + entropy decline) to avoid late-run regressions.
- Tools/workflows:
- Dashboarding of reward/entropy/mistake-pool dynamics
- Automatic Δ search (maximizing empirical S(Δ)) and rollback execution
- Assumptions/dependencies:
- Frequent checkpointing cadence
- Reliable logging of per-batch/group accuracy and token-level KLs for variance proxies
- Academic baseline and ablation framework for RLVR research
- Sectors: academia, open-source labs
- What: Use NPO as a strong, objective-preserving baseline in studies of mixed-policy RLVR, quality–variance trade-offs, and entropy-collapse mitigation.
- Tools/workflows:
- Plug-and-play NPO module with ablations (IS-correction on/off, Δ-sweep, gating thresholds)
- Assumptions/dependencies:
- Access to compute for short scout runs and controlled replays
- Public verifiers and open benchmarks or synthetic checkers
Long-Term Applications
These opportunities require further research, domain adaptation, scaling, or new tooling (especially verifiers).
- Generalization of NPO to non-language RL domains (robotics, operations research, networking)
- Sectors: robotics, logistics, energy grid control, telecom
- What: Use near-future policies to guide exploration in environments with sparse rewards or late plateaus; replace external demonstrations with low-variance future-self trajectories.
- Tools/workflows:
- Task-specific verifiers (e.g., constraint checkers, safety monitors, simulators)
- Near-future rollout servers for control policies
- Assumptions/dependencies:
- Strong, low-latency verifiers/simulators; safe reset/replay mechanisms
- Capability to measure variance proxies (e.g., action-distribution KLs)
- Self-taught RLVR suites combining sequence-level NPO with token-level on-policy distillation
- Sectors: software, AI research, education
- What: Merge NPO (sequence-level, verifier-filtered) with on-policy distillation to couple low-variance guidance and token-level signal; expected gains in data and compute efficiency.
- Tools/workflows:
- Dual-loss training with a simple controller for switching/mixing sequence- and token-level signals
- Assumptions/dependencies:
- Stable multi-objective optimization
- Careful regularization to avoid collapse or over-anchoring to the guide
- Continual learning and periodic self-refresh for deployed models
- Sectors: SaaS AI platforms, enterprise AI, edge/embedded
- What: Schedule AutoNPO-style interventions during periodic maintenance windows to “reopen” exploration and prevent capability drift/regression without external teachers.
- Tools/workflows:
- Rolling mistake pools from production telemetry (with privacy safeguards)
- Lightweight verifiers for production task families
- Assumptions/dependencies:
- Privacy-preserving logging and aggregation
- Automated verifier evolution as tasks change
- Domain-specific verifier ecosystems and standards
- Sectors: healthcare, finance, legal, safety-critical systems, public sector
- What: Develop robust, auditable verifiers (programmatic, symbolic, or hybrid human-in-the-loop) to unlock RLVR+NPO in regulated settings.
- Tools/workflows:
- Validator SDKs, benchmark suites, and conformance tests
- Assumptions/dependencies:
- Regulatory acceptance of machine-verifiable criteria
- Risk frameworks for reward misspecification
- Compute- and cost-optimized training planners
- Sectors: cloud ML, model providers
- What: Use the empirical S(Δ)=Q/V framework to schedule scout runs, checkpoint cadences, and intervention windows to maximize return on training compute.
- Tools/workflows:
- Budget-aware controllers that co-optimize Δ, cache sizes, and gating thresholds
- Assumptions/dependencies:
- Accurate proxies for Q and V; reliable early-warning signals
- Robust checkpoint management at scale
- Test-time meta-control and planning with near-future rollouts
- Sectors: agents, robotics, autonomous systems
- What: Explore “near-future” reasoning at test time (e.g., brief inner-loop optimization or hypernetwork guidance) to generate a low-variance teacher for a final decision.
- Tools/workflows:
- Lightweight inner-loop planners or amortized “guide heads”
- Assumptions/dependencies:
- Strict latency/compute budgets; on-device optimization constraints
- Safety wrappers for deployment-time adaptation
- Education and daily-life assistants with verifiable reasoning cores
- Sectors: education tech, productivity apps, consumer AI
- What: As verifier libraries expand (math, unit conversion, structured extraction), NPO-trained models can deliver more reliable step-by-step assistance in everyday tasks (homework help, budgeting spreadsheets, tax form prep, visual math from phone camera).
- Tools/workflows:
- App-facing verifiers (answer checkers, schema validators) with explainability logs
- Assumptions/dependencies:
- High coverage verifiers for target tasks; careful UX for failures/uncertainty
- On-device or cloud-side privacy and safety policies
Cross-Cutting Assumptions and Dependencies
- Verifiability is central: tasks must admit trusted pass/fail signals. In regulated sectors, validators must encode policy and safety constraints.
- Infrastructure needs: frequent checkpointing, rollback-safe training orchestration, and storage for guidance caches.
- Compute budgets: near-future guidance requires short scout/continuation runs and offline rollouts, though interventions are brief and targeted.
- Stability conditions: near-future checkpoints should remain close in distribution (small Δ) to keep variance low; AutoNPO’s Δ selection mitigates but does not remove this requirement.
- Monitoring: reward stagnation and entropy decline must be reliably logged; variance proxies (e.g., token-level KLs) should be available for S(Δ) estimation.
- Governance and privacy: mistake-pool logging and replay should comply with data policies; prefer synthetic/derived telemetry where possible.
Glossary
- AutoNPO: An adaptive controller that automates when and how to inject near-future guidance during training based on online signals. "AutoNPO unifies both interventions by triggering them automatically from online training signals."
- behavior policy: In off-policy RL, the policy that generated the data used to compute importance weights for the learning policy. "the behavior policy is for all on-policy slots and only for the guidance slot"
- capability probe: A lightweight evaluation used online to assess whether the current model can now solve previously failed prompts. "a capability probe"
- clipped objective: A PPO-style loss that clips the importance ratio to stabilize updates. "the clipped objective is:"
- distributional gap: The mismatch between the distributions of the guidance policy and the current policy, which can increase variance and destabilize learning. "a distributional gap so wide"
- effective learning signal: A measure of how useful an off-policy source is, defined as signal quality divided by variance cost. "The effective learning signal is then defined as:"
- entropy collapse: The reduction of policy entropy over training, indicating narrowed exploration and potential over-concentration on few patterns. "Pure GRPO undergoes a steady entropy collapse"
- entropy regularization: A regularizer that encourages exploration by increasing the entropy of the policy’s action distribution. "we omit both the KL penalty and entropy regularization from the objective."
- Exponential Moving Average (EMA): A smoothed statistic over time that weights recent observations more heavily, used here to detect plateau. "Exponential Moving Average(EMA) of training reward"
- experience replay: Reusing previously collected successful trajectories to continue training. "experience replay and restart-style methods"
- exploration collapse: A training failure mode where the policy’s exploration diminishes, often detected via reward stagnation and entropy drop. "the characteristic signature of exploration collapse."
- far-future policy: A much later, stronger checkpoint (or fully trained model) used as an off-policy teacher, typically with larger distributional shift. "(far-future policy)"
- far-future replay methods: Approaches that guide training using trajectories from a fully trained or much later model. "Far-future replay methods (e.g., RLEP)"
- GRPO: A group-based RLVR algorithm that optimizes policy using grouped rollouts and relative advantages. "GRPO (pure on-policy)"
- group accuracy: The success rate computed over all trajectories in a rollout group for a prompt. "group accuracy stops improving"
- group-based RLVR: RL with verifiable rewards that operates on groups of rollouts per prompt to compute relative advantages. "group-based RLVR backbone"
- guidance trajectory: A verified-correct trajectory generated by a near-future policy that replaces one slot in the on-policy rollout group. "as the guidance trajectory "
- Group-relative advantage: The normalized advantage computed relative to other trajectories in the same rollout group. "Group-relative advantages are then computed"
- importance sampling (IS) correction: A correction using likelihood ratios to account for off-policy data when updating the current policy. "the importance sampling (IS) correction is non-trivial only for the guidance slot."
- importance weighting: Weighting updates by the ratio between the current policy and behavior policy probabilities to correct off-policy bias. "incorporated through importance weighting "
- KL penalty: A regularization term penalizing divergence from a reference policy measured by KL divergence. "we omit both the KL penalty and entropy regularization from the objective."
- Kullback–Leibler (KL) divergence: A measure of divergence between two probability distributions, used here per token as a proxy for variance. "the per-token KL between and "
- LUFFY: A baseline that mixes external teacher trajectories during RL training, representing high-quality but high-shift guidance. "LUFFY (external teacher)"
- mistake pool: A buffer of prompts recently failed by the model, used to trigger and target interventions. "AutoNPO maintains a lightweight mistake pool "
- mixed-policy regime: Training that mixes trajectories from the current policy with those from other policies or sources. "moving from pure on-policy updates to a mixed-policy regime."
- near-future checkpoint: A slightly later checkpoint from the same training run used to provide low-variance, higher-quality guidance. "a near-future checkpoint on the same training run."
- Near-Future Policy Optimization (NPO): A method that guides the current policy using verified trajectories from a near-future checkpoint on the same run. "Near-Future Policy Optimization (NPO)"
- off-policy trajectory source: A source of trajectories generated by a policy different from the current one. "two quantities associated with any off-policy trajectory source."
- on-policy RLVR: RL with verifiable rewards where trajectories are sampled from the current policy being optimized. "Pure on-policy RLVR"
- parameter drift: The change in model parameters between checkpoints that increases variance when using off-policy data. "more parameter drift"
- pass-rate: The measured fraction of correct generations (passes) for a prompt or set of prompts. "The rollout returns a pass-rate "
- pass@1: The probability that the first sampled output is correct, commonly used in reasoning evaluation. "pass@1 improvements come mainly from redistribution"
- per-token log-probabilities: The log-likelihoods of each generated token under a policy, used for IS and analysis. "per-token log-probabilities no longer need to be stored or recomputed."
- policy entropy: The entropy of the policy’s output distribution, used to monitor exploration. "policy entropy keeps dropping"
- prefix (expert prefixes): Partial expert-generated sequences prepended to prompts to steer model reasoning during training. "expert prefixes"
- replay buffer: A storage of past successful trajectories used for training via replay. "replay buffers of historical successes"
- restart-style methods: Techniques that restart or replay segments of training, often with stored or stronger trajectories. "restart-style methods"
- RLEP: A replay-based baseline that uses experience from a stronger seed policy (far-future). "RLEP (far future)"
- rollback distance: How far back in training steps to roll when applying an intervention. "Rollback distance."
- rollout distribution: The distribution over outputs induced by the current policy during sampling, which can narrow over training. "rollout distribution narrows"
- rollout group: A set of multiple trajectories sampled for the same prompt to compute group-relative statistics. "rollout group"
- signal quality (Q): The fraction of failed prompts for which the guidance source can produce a verified-correct trajectory. "signal quality~"
- trajectory: In RL, a sequence of tokens/actions constituting a complete generated solution or path. "correct trajectory"
- variance cost (V): The gradient variance introduced when incorporating off-policy trajectories via importance weighting. "variance cost~"
- verifier: An automatic checker that determines whether a generated trajectory is correct. "run the verifier"
- verifier-filtered trajectories: Guidance samples kept only if they pass a verification step, ensuring correctness. "verifier-filtered, prompt-aligned trajectories"
Collections
Sign up for free to add this paper to one or more collections.