- The paper introduces LEO, the first cross-vendor, instruction-level tool for root-cause analysis of GPU stalls via synchronization-aware backward slicing.
- It integrates vendor-specific APIs and disassembly tools to construct dependency graphs that map stalls to source code contexts effectively.
- LEO's evaluations demonstrate speedups up to 11×, highlighting its potential to optimize performance across diverse GPU architectures.
LEO: Cross-Vendor Backward Slicing for GPU Stall Root-Cause Analysis
Introduction
Modern HPC systems and exascale supercomputers rely on GPU acceleration, leveraging devices from NVIDIA, AMD, and Intel. Diagnosing and mitigating GPU pipeline stalls is paramount for performance engineers. Vendor tools provide program-counter (PC) sampled stall traces, yet lack explanatory power regarding the origins of stalls at the instruction level, especially when traversing vendor-specific instruction set architectures (ISAs) and synchronization mechanisms. "LEO: Tracing GPU Stall Root Causes via Cross-Vendor Backward Slicing" (2604.20032) introduces LEO, the first unified, cross-vendor instruction-level root-cause analyzer for GPU stalls. LEO enables fine-grained, actionable attribution of GPU inefficiencies while spanning the semantic diversity of major GPU architectures.
System Architecture and Core Methodology
LEO operates as a post-mortem analysis tool, built atop the HPCToolkit's cross-vendor PC-sampling infrastructure. It interfaces with vendor-provided APIs for profiling and disassembly (NVIDIA CUPTI, AMD ROCprofiler-SDK, Intel Level Zero), enabling modular extension to new hardware.
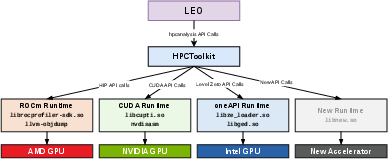
Figure 1: The LEO system architecture integrates with HPCToolkit’s hpcanalysis API, interfacing with vendor-specific profiling and disassembly backends.
The core workflow consists of:
- Binary Analysis and Disassembly: Leveraging vendor-specific disassemblers and DWARF debug data, LEO constructs control-flow graphs and maps executable instructions to source code context trees (CCTs).
- Dependency Graph Construction: For each instruction, RAW (read-after-write) and GUARD (predicate) dependencies are established. LEO extends this with synchronization-specific edges for s_waitcnt (AMD), hardware barrier bits (NVIDIA), and SWSB tokens (Intel).
- Multi-Stage Pruning: Dependency graphs are pruned by opcode compatibility, synchronization semantics, pipeline and latency analysis, and execution counts. This reduction is crucial for producing unambiguous blame chains.
- Blame Attribution: LEO employs an inverse-distance weighting mechanism, factoring in path length, instruction execution frequency, efficiency, and hardware stall type matches for precise root-cause assignment.
A central advancement is LEO’s ability to trace cross-vendor synchronization stalls. For AMD, LEO follows s_waitcnt semantics, linking pipeline stalls to specific in-flight memory instructions. On NVIDIA, hardware barrier bits and DEPBAR semantics are analyzed. For Intel, LEO parses SWSB stall chains and SBID resolutions. The result is actionable attribution chains rooted not only in register dependencies but also in the diverse synchronization mechanisms that contribute to stalls.
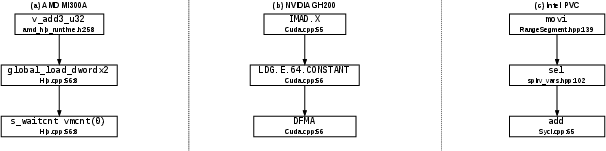
Figure 2: Backward slicing on RAJAPerf’s LTIMES_NOVIEW kernel, demonstrating architectural divergence in dependency chains and root cause mapping for AMD, NVIDIA, and Intel GPUs.
LEO demonstrates that for kernels like LTIMES_NOVIEW, architectural divergence is common: the same compute kernel alternately manifests as memory-bound, compute-bound, or synchronization-bound depending on platform and execution policy. This is only exposed via synchronization-aware backward slicing that extends beyond register-level dependencies.
Numerical Results and Diagnostic Efficacy
Across 21 HPC and ML workloads spanning AMD MI300A, NVIDIA GH200, and Intel PVC, LEO-guided optimizations yield strong geometric-mean speedups of 1.73×–1.82×, with per-kernel maxima exceeding 11×. These results are achieved with minimal, local code modifications targeted to the source instructions and higher-level constructs implicated by LEO’s ranked diagnostic chains. Importantly, LEO exposes numerous cases where the bottleneck root cause differs fundamentally across architectures—even for the same codebase and source line.
Key observations include:
- The same source code may exhibit distinct optimization opportunities on different architectures (e.g., compute-bound on NVIDIA, memory-bound on AMD).
- LEO's synchronization-extended backward slicing reveals root causes that span multiple source files or framework abstraction layers, which is nontrivial with conventional profiling techniques.
- LEO's backward slices are especially effective for HPC proxy applications with heavy use of templates, inlined kernels, and indirect addressing.
Evaluation for Automated and LLM-Guided Optimization
LEO’s structured root-cause reports, incorporating cross-file dependency chains and per-instruction blame quantification, were evaluated as input enhancements to LLM-based autotuning pipelines. Experimentally, LEO’s structured diagnostics improve both the quality and yield of LLM-based kernel optimization, increasing mean speedup from 1.13× (code only) and 1.08× (raw stall data) up to 1.29× (LEO-augmented). Additionally, they eliminate catastrophic regressions that occur when LLMs act on unstructured metrics. This establishes LEO as a credible mechanism for automated code tuning guidance, not merely for manual expert diagnosis.
Implications and Limitations
Practically, LEO addresses two critical gaps:
- Performance Portability Diagnostics: LEO enables developers and toolchains to understand and remediate cross-architecture performance gaps at instruction granularity, facilitated by portable performance models (RAJA, Kokkos).
- Framework Layer Decoupling: By tracing through template and abstraction boundaries, LEO obviates the need for manual binary/source code reconciliation, providing direct attribution from machine-level stalls to high-level source constructs.
The theoretical impact is in extending program slicing to the field of vendor-specific GPU machine code, including synchronization semantics that are opaque to standard static analyses. LEO’s cross-vendor abstraction over PC-sampling semantics, synchronization primitives, and ISA-specific pipeline behaviors can inform future work in both static and dynamic program analysis for accelerators.
Limitations include: exclusive reliance on register-level and explicit synchronization dependencies (potentially missing true memory dataflow across pointers/indirect accesses); heuristic blame assignment (inverse-distance and efficiency-based, sans probabilistic control flow modeling); and vendor-specific toolchain adaptation requirements.
Future Directions
Promising future directions include: incorporating memory data-flow analysis to capture indirect dependencies (e.g., pointer chasing); extending predicate-aware analysis and weighting for divergent GPU control flows; formalizing temporal chains over multi-GPU and multi-kernel workloads; and broader integration with LLM-based tuning and compilation toolchains. Full intervention-based validation of LEO's blame chains and benchmarking against competing diagnostic frameworks remain open.
Conclusion
LEO provides, for the first time, vendor-agnostic, instruction-level root cause analysis of GPU stalls via synchronization-aware backward slicing. It leverages unified dependency graph construction, ISA-specific synchronization tracing, and blame attribution to expose actionable bottlenecks across NVIDIA, AMD, and Intel GPUs. LEO’s diagnostic chains demonstrate strong utility both for expert-guided kernel optimization and as context for automated code tuning agents. Practically, LEO establishes a new standard for GPU root-cause analysis in performance engineering and exposes avenues for further research in cross-layer performance modeling and automated optimization methodologies.

