- The paper introduces the Bayesian Medical Belief Engine (BMBE) that separates LLM-based language parsing from deterministic diagnostic inference.
- It employs a sequential Bayesian decision process with tunable confidence thresholds to enhance accuracy and enable selective abstention.
- Empirical validation shows BMBE achieves higher diagnostic harmonic scores and cost-efficiency compared to standalone LLM doctors.
Modular Medical Dialogue via Bayesian Belief Engine: Summary and Analysis
Motivation and Architectural Overview
LLMs have achieved strong fluency in natural-language medical dialogue but fundamentally lack mechanisms for calibrated, auditable probabilistic inference. The core thesis of "Statistics, Not Scale: Modular Medical Dialogue with Bayesian Belief Engine" (2604.20022) is that this conflation of language and reasoning in end-to-end LLM-based diagnostic agents is an architectural error, not merely a matter of engineering or scaling. The proposed solution is the Bayesian Medical Belief Engine (BMBE), a modular architecture in which the LLM is demoted to a pure sensor layer—parsing patient utterances into structured evidence and verbalizing questions—while all diagnostic inference resides within a deterministic, auditable Bayesian engine operating over an explicit, replaceable knowledge base (KB).
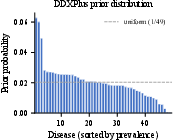
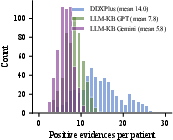
Figure 2: DDXPlus prior distribution exhibits a heavy-tailed prevalence spectrum typical of real-world diseases (left); patient evidence count per KB reflects data density for sequential inference (right).
The BMBE approach guarantees privacy (no patient data enters the LLM), supports plug-and-play statistical backends for population adaptation, produces an explicit calibrated accuracy–coverage tradeoff via a confidence threshold, enables precise abstention instead of forced guesses, and exposes each inference step to audit. This modularization stands in strict contrast with both traditional expert systems—which required structured clinician input—and contemporary LLM-driven diagnostic pipelines, which fail to offer calibrated posteriors, information-theoretic questioning, principled stopping, or guarantees against hallucination and confidence miscalibration.
Diagnostic dialogue is formalized as a sequential Bayesian decision process over disease space D and feature space F. The system maintains a belief state bt at turn t; selects features via expected information gain (EIG) to maximally reduce posterior entropy; updates beliefs with Jeffrey's conditioning for hedged/uncertain evidence; and determines whether to diagnose or abstain by thresholding the maximum posterior probability (τ). This threshold controls accuracy–coverage tradeoff, providing explicit deployment flexibility absent from standalone LLM agents.
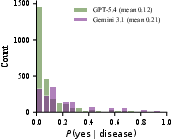
Figure 4: Distribution of LLM-elicited binary likelihoods P(yes for both LLM-generated knowledge bases (left), reflecting weakly informative medical features.
The KB-backed reasoning module is fully auditable and deterministic—every inference step (prior, evidence integration, belief update, and question selection) can be externally inspected or recalibrated as population priors and disease-prevalence change.
Efficacy and Empirical Validation
Main Results: Outperforming Standalone LLMs
On the DDXPlus dataset (49 diseases, 314 features, n=50 synthetic patients), BMBE variants—regardless of the LLM sensor backend—consistently achieve higher diagnostic harmonic scores (DHS) than all standalone LLM-based doctors, even when using significantly smaller, cheaper LLMs. For instance, BMBE+GPT-5.4-nano obtains a DHS of 88, versus a maximum DHS of 76 for the strongest standalone LLM (Gemini 3.1 Pro)—all at an order of magnitude lower cost.
Statistical Separation Gap
Notably, for all three major model families (GPT, Gemini, Llama), swapping a standalone LLM doctor for a BMBE using an inexpensive sensor LLM from the same family yields a strong increase in quality alongside a substantial cost reduction. This statistical separation gap is robust to model scale, architecture, and sensor choice—the performance gains are architectural, arising from enforcing statistical reasoning with a Bayesian engine rather than informational advantages associated with LLM's internal knowledge.
Knowledge Base Origin: Architecture, Not Data
A crucial experiment replaces the empirical knowledge base with LLM-generated KBs, ensuring that both BMBE and standalone LLM doctors reason from identical clinical knowledge (i.e., the LLM’s own beliefs, zero-shot). Under these conditions, the BMBE matches or surpasses standalone LLMs in accuracy and DHS, especially on rare diseases, despite only using low- to mid-tier LLM sensors. This isolates the measured architectural benefit from data-availability confounds.
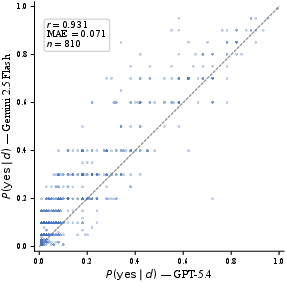
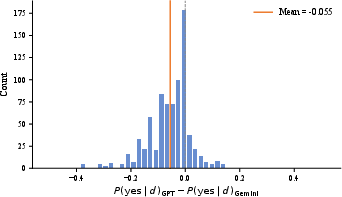
Figure 6: Scatter plot of P(yes likelihoods for 45 shared features in two LLM-generated KBs; Pearson r=0.93 confirms high inter-model agreement.
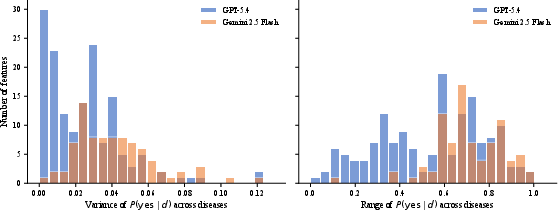
Figure 8: Gemini 3.1 features (right) are more discriminative than GPT-5.4 (left); valuable for sharper Bayesian updates.
Operating Point Control and Selective Abstention
The BMBE framework exposes a continuous, tunable accuracy–coverage frontier by adjusting the posterior confidence threshold τ. In sharp contrast, standalone LLMs only support a single, opaque abstention decision. The system’s selective abstention ensures that when diagnostic uncertainty remains high after query budget exhaustion, it declines to provide a diagnosis, dramatically reducing uncalibrated errors at high-confidence settings.
Robustness to Adversarial Patient Personas
Robustness evaluation demonstrates that the BMBE maintains stable diagnostic performance across varied patient communication styles—including adversarial cases (trust withholding, verbosity, dazed states). Standalone LLM doctors, in contrast, experience severe performance degradation, especially in coverage, when confronted with adversarial communication.
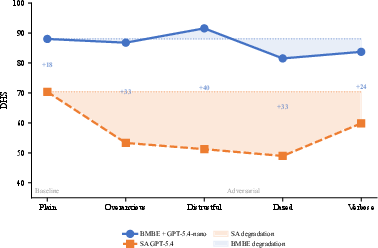
Figure 1: DHS (diagnostic harmonic score) remains stable for BMBE across patient personas and collapses for standalone doctors under adversarial conditions.
Disease Scaling
BMBE exhibits stable accuracy as the candidate disease set size increases, scaling from F0 to F1, unlike standalone LLMs, whose performance remains flat and does not adapt to expanded hypothesis sets.
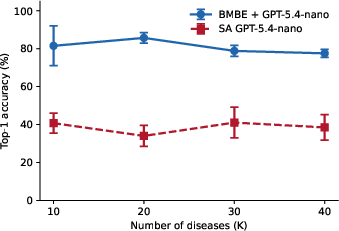
Figure 3: Top-1 accuracy as disease space F2 scales; BMBE’s performance is robust while standalone LLMs plateau.
Technical Contributions
- Strict Language–Reasoning Separation: The LLM is isolated to schema-based parsing (evidence extraction) and natural language question generation with zero access to posterior or uncertainty information. The Bayesian engine maintains all state and executes all updates.
- Flexible, Safe Deployment: A single threshold parameter, F3, provides safety/throughput adjustment (abstention for unclear cases), supporting diverse clinical contexts with no retraining.
- Plug and Play Backend: Updating the reasoning module to a region/population-specific KB is trivial and auditable; no LLM modification or fine-tuning is required.
- Calibrated Inference: Output confidence is mathematically interpretable and adjustable, yielding calibrated selective accuracy and minimizing the risk of overconfident misdiagnoses.
- Privacy by Design: Patient text never enters the LLM for downstream inference, mitigating secondary privacy concerns in practice.
Implications, Limitations, and Future Directions
Practical Impact
BMBE validates a paradigm shift for medical AI deployment: decompose systems into language-handling and inference components, leveraging LLM strengths for semantic parsing but restricting medical decision-making to deterministic, auditable, population-adaptable statistical algorithms. This enables safe, scalable, low-cost deployment, especially in settings where regulatory, auditability, and privacy requirements are strict.
The method is deployable in new populations by simply substituting the KB, facilitating global clinical expansion without growing concerns over LLM training bias or regional datum acquisition.
Theoretical Implications
The demonstrated statistical separation gap is robust to KB origin and LLM sensor quality, signaling a fundamental architectural limitation of end-to-end LLMs for probabilistic medical decision-making. The explicit EIG-based questioning and principled uncertainty modeling cannot be matched by scaling LLM parameters alone.
Limitations
- Closed World Assumption: BMBE is restricted by KB completeness; novel or out-of-KB disease states cannot be handled except by abstention.
- Simulated Evaluation: Experiments use synthetic patients; deployment in real clinical interaction contexts will require further validation.
- Limited Spontaneous Evidence Integration: Volunteered evidence not explicitly queried may not propagate to inference, limiting conversational naturalism relative to holistic LLM dialogue models.
Future Work
- Tightening the language module to leverage as much volunteered evidence as possible without violating the separation principle.
- Extending to open-world settings with dynamic candidate expansion in response to out-of-KB evidence patterns.
- Clinical trials in real-world settings with actual patient–clinician interactions.
- Integrating more expressive probabilistic graphical models (e.g., loopy graphical disease-feature relationships) as backends to better capture complex dependencies.
Conclusion
The BMBE framework introduces and validates a strict modularization of clinical dialogue systems: LLMs act as language sensors, while Bayesian engines shoulder the core diagnostic reasoning. This architectural separation yields consistent improvements in accuracy, robustness, cost-effectiveness, and controllability over standalone LLM doctors, irrespective of backend model scale or knowledge base. The results robustly argue for designing clinical AI systems around explicit, auditable statistical reasoning—rather than ever-larger end-to-end LLMs—for safe and reliable medical decision support.