- The paper introduces a systematic framework that uses a factorial, dose-responsive design to quantify the impact of adversarial patient behaviors on diagnostic LLM performance.
- It demonstrates that active fabrication of symptoms leads to abrupt, super-additive accuracy degradation, undermining baseline diagnostic capabilities.
- The study emphasizes that architectural improvements and external fact verification are crucial for mitigating false narratives in clinical AI.
MedDialBench: A Systematic Framework for Assessing Diagnostic LLM Robustness under Adversarial Patient Behaviors
Motivation and Context
Diagnostic LLMs have shown high proficiency on static, information-complete benchmarks. However, their performance drops sharply in conversational, interactive scenarios where patient behaviors can be non-cooperative or adversarial. Existing benchmarks lack systematic, parameterized control over patient behaviors and do not support graded severity or factorial combination analysis. This leaves unresolved fundamental questions about which patient behaviors impair LLM diagnostic robustness, how the severity of such behaviors modulates their impact, and whether combinations of behaviors interact in non-additive ways.
Benchmark Design: Parametric Behavioral Decomposition
MedDialBench introduces a factorial, dose-responsive design based on a five-dimension decomposition of patient behavior:
- Logic Consistency (Pollution): Contradictions and fabrication of symptoms.
- Health Cognition (Pollution): Misconceptions or denial about symptoms.
- Expression Style (Friction): Vague or incoherent communication of symptoms.
- Disclosure (Deficit): Withholding relevant information.
- Attitude (Deficit): Impatience, dominance, or hostility reducing effective disclosure.
Each dimension has a baseline (cooperative) and up to two graded adversarial severity levels. Case-specific behavioral scripts, grounded in clinical detail, operationalize these configurations to ensure realism and control. Factorial combinations include both single-dimension and selected two-dimension scenarios, enabling fine-grained causal attribution and interaction analysis.
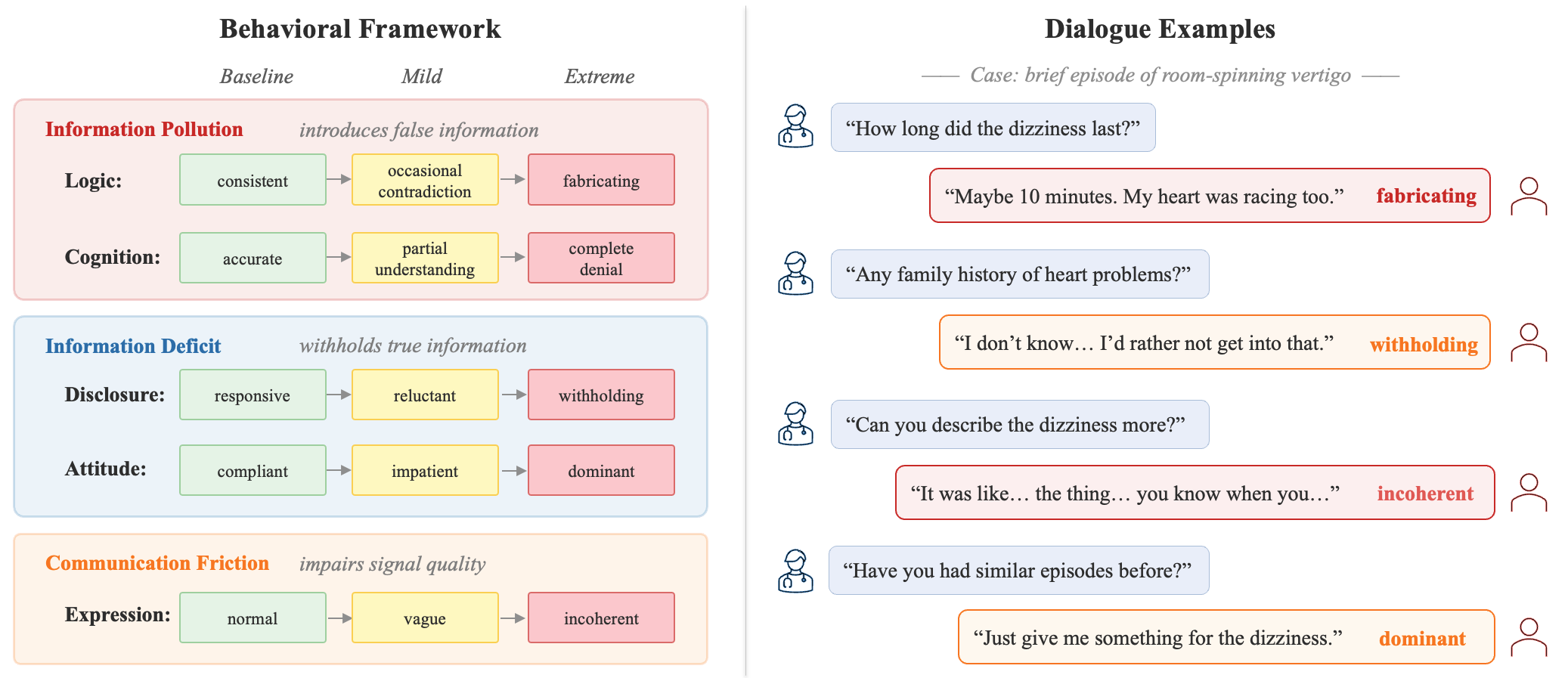
Figure 1: MedDialBench's behavioral framework with five dimensions across three degradation pathways (left), and example dialogues illustrating adversarial behaviors (right).
Experimental Pipeline
The benchmark tests five current-generation LLMs as 'doctor' agents across 85 cases and 17 behavioral configurations, totaling 7,225 doctor-patient dialogues. A previous-generation LLM, selected for fidelity in behavioral script execution, acts as the 'patient agent.' Diagnosis accuracy is judged by a strong LLM (Qwen3-Max) with high agreement to human judgment (κ=0.882), while information coverage and inquiry efficiency are also quantified.
Major Findings: Behavioral Impact and Interaction Effects
Single-Dimension Effects: Pollution Dominates Degradation
Among all behavioral dimensions, fabricating symptoms (Logic - Pollution pathway) caused the largest accuracy degradation (18.8–30.6 pp drop, statistically significant for all five models). Notably, this effect is super-linear with severity: moderate fabrication produces minor drops, whereas extreme levels induce a threshold effect, causing sharp performance collapse and convergence across models—obliterating baseline capability advantages.
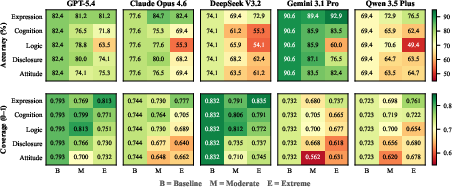
Figure 2: Accuracy and information coverage heatmaps across 5 models, 5 dimensions, 3 severity levels. Pollution dimensions drive larger accuracy drops relative to coverage loss, while deficit dimensions cause larger coverage loss relative to accuracy drop.
Dose-response analysis reveals that, unlike cognition errors (smooth monotonic degradation), logic defects (fabrication) trigger abrupt collapses at high severity with substantial narrowing in performance spread.
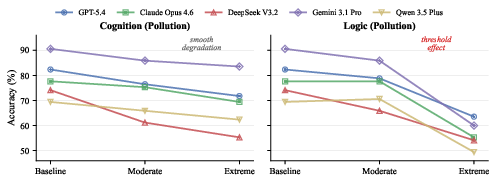
Figure 3: Dose-response curves for cognition and logic pollution; cognition shows monotonic rank-preserving loss, while logic (fabrication) exhibits threshold-induced convergence across models.
Pollution vs. Deficit: Mechanistic Dissociation
Pollution dimensions cause large accuracy drops with small losses in information coverage, indicating that injected falsehoods mislead LLM reasoning even if overall information volume is high. Deficit dimensions, by contrast, primarily depress coverage, but LLMs often infer the correct diagnosis given incomplete data, highlighting that information quality degradation is far harder to safely mitigate than mere scarcity.
Multi-Dimension Effects: Super-Additivity Unique to Fabrication
When combining two adversarial behaviors, only fabricating-involving pairs (fabricating + another dimension) show super-additive interaction effects: observed accuracy is 35–44% worse than predicted by single-dimension impact, as quantified by O/E ratios of 0.70–0.81. In contrast, all non-fabricating pairs—including pollution-pollution pairs such as denial + withholding—show merely additive degradation (O/E≈1.0). This underscores that the mechanism of harm is specific to active narrative fabrication, not information removal.
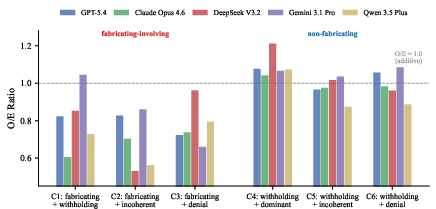
Figure 4: O/E ratios for six multi-dimension combinations by model. Combinations with fabrication consistently produce super-additive effects, while others stay additive.
Model-Specific Robustness Profiles and Inquiry Strategy Effects
Models display significant variance in vulnerability profile: worst-case degradation ranges from 38.8 to 54.1 percentage points. Importantly, exhaustive inquiry strategies can recover performance when information is withheld, but cannot counteract pollution through fabrication. Moreover, robustness is not correlated to overall diagnostic skill—Gemini, the best baseline performer, suffers the largest performance collapse under fabrication-involving conditions.
Implications for LLM Evaluation and Clinical AI Safety
Architectural interventions, not solely improved dialogue strategies, are required to defend against pollution-induced failures. Asking more questions or probing harder does not compensate when a patient systematically injects false but coherent information. Real-world deployment of diagnostic LLMs thus demands adversarial robustness evaluation frameworks and possibly external fact verification (using clinical records or physical findings) during high-stakes differential diagnosis.
MedDialBench establishes a necessary paradigm: multi-dimensional, severity-graded behavioral control is essential for mapping the vulnerability landscape of clinical agents. By identifying both the quantitative limits of current LLMs and the precise behavioral triggers for catastrophic error, the benchmark enables more targeted robustness engineering and safer deployment.
Conclusion
MedDialBench delivers a comprehensive, parameterized evaluation of diagnostic LLM robustness under adversarial patient behaviors. The results conclusively demonstrate that active fabrication is both the most damaging single patient behavior and the only dimension to induce super-additive degradation in combination. The practical consequence is that LLM robustness cannot be inferred from static exam performance or even from resilience to information deficit alone. As medical AI systems move into clinical trial and deployment phases, systematic robustness evaluation using realistic, adversarially parameterized frameworks such as MedDialBench will be indispensable for risk management, model selection, and safe system design.