- The paper presents a teleportation-based protocol that parallelizes non-Clifford gate synthesis, achieving up to a 3× speedup without extra qubit overhead.
- It benchmarks three architectural strategies using high-rate QLDPC codes, reducing required physical atoms and wall-time for dynamics simulations.
- The approach emphasizes spatial efficiency and idle module utilization to enable early fault-tolerant quantum advantage on neutral atom platforms.
Architectures for Early Fault-Tolerant Quantum Advantage with Neutral Atoms
Introduction and Context
This work systematically investigates architectural strategies to enable early demonstrations of fault-tolerant quantum advantage using neutral atom platforms (2604.19735). Neutral atom systems have rapidly advanced, now allowing for the simultaneous control of thousands of coherent qubits and the realization of quantum error correction (QEC) at experimentally relevant scales. The paper addresses the critical question of how to architect a scalable, fault-tolerant device that balances space (qubit overhead) and time (execution wall-time), targeting relevant quantum algorithms (e.g., dynamics simulations) and considering the highly asymmetric operation times found on neutral atom hardware—most notably, the slow mid-circuit measurement relative to fast gates and shuttling operations.
Compilation Paradigms and QEC Code Selection
The analysis contrasts three classes of compilation and architectural strategies, each anchored to a different scheme for fault-tolerant logical gate implementation:
- Transversal-based architectures: Logical gates are implemented directly by transversal operations between code blocks (e.g., surface codes), affording high parallelism but at the expense of substantial spatial overhead due to low encoding rates.
- Extractor-based (code surgery) architectures: Computation proceeds via sequences of projective measurements (Pauli-based computation), leveraging high encoding-rate quantum LDPC (QLDPC) codes like the bivariate bicycle or gross code, resulting in significant space efficiency but limited ability to parallelize non-Clifford gate synthesis.
- Hybrid (load/store) architectures: These approaches attempt to combine the temporal advantages of transversal gates permitted in low-rate codes with spatial efficiencies from QLDPC memories, orchestrating data movement via teleportation or code surgery between memory and compute regions.
The paper adopts high-rate QLDPC codes, specifically the bivariate bicycle/two-gross code family, as the default memory primitive for extractor-based and hybrid designs due to their industrial relevance and explicit hardware ISAs.
The main technical contribution is the identification and mitigation of serialization bottlenecks inherent to extractor-based architectures. The dominant source of latency is the sequential synthesis of R(φ) (arbitrary rotation) gates, which translates to long chains of T-state injections. The authors propose a teleportation-based parallelization protocol utilizing the reconfigurable neutral atom connections and the otherwise idle logical ancilla qubits within each module.
After arbitrarily designating one injection pivot per commuting rotation, the protocol creates magic states via multiple T-state factories and redistributes projective measurements to maximize utilization. The degree of parallelization scales as O(U), where U is the instantaneous number of unutilized modules in the system. This approach preserves spacetime efficiency, requiring no overhead in qubit number.
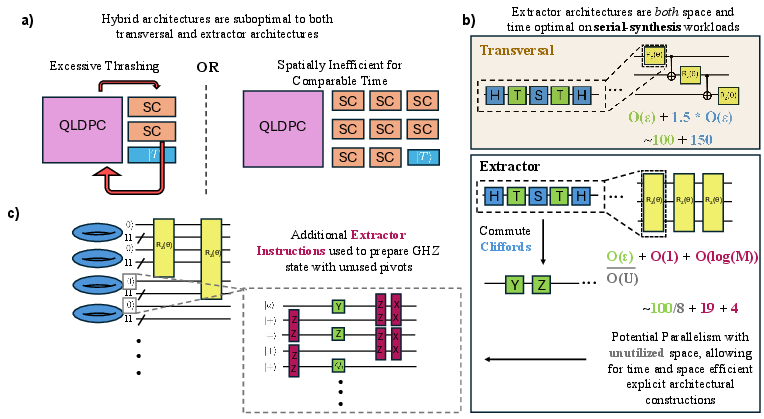
Figure 1: Timing and space overheads of hybrid, transversal, and extractor architectures; extractor-based schemes with teleportation-based parallelization efficiently leverage idle modules for non-Clifford gate acceleration.
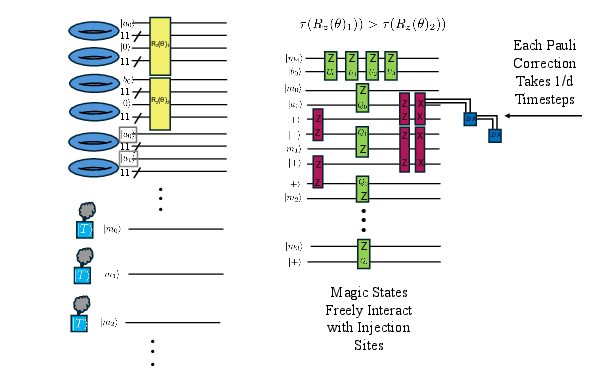
Figure 2: Teleportation-based parallelization circuit for T-state injection—injection pivots (a0, b0) and factory distribution maximize parallel synthesis of non-Cliffords.
Numerical Results: Space-Time Efficiency and Benchmarking
A comprehensive simulation suite evaluates architectural choices on quantum advantage-relevant benchmarks—Heisenberg, transverse-field Ising (nearest and long-range), and Fermi-Hubbard models—under realistic hardware noise and operation times.
Key outcomes include:
- The proposed parallelized extractor architecture achieves up to 3× speedup over standard extractor designs with no qubit overhead; on larger synthesizable workloads, it surpasses transversal architectures in wall-time and remains strictly superior in space-time product across a wide parameter regime.
- Quantum advantage is attainable for select dynamics simulations with as few as 11,495 physical atoms in ∼ 15 hours, compared to the >60,000 atoms required for equivalent transversal code approaches.
- Extractor-based architectures, with the parallelization protocol, achieve the lowest overall spacetime cost for two out of four quantum advantage benchmarks, and remain competitive on all others.
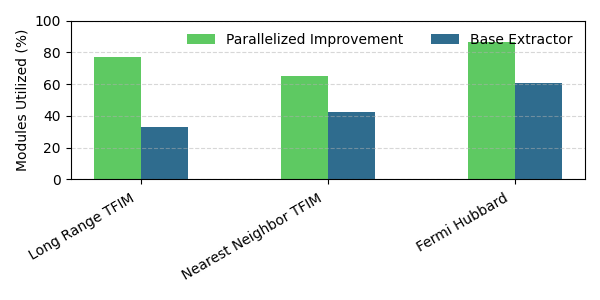
Figure 3: Module utilization across benchmarks; parallel injection maximizes utilization during non-Clifford gate synthesis.
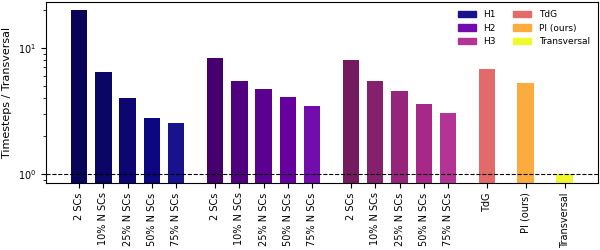
Figure 4: Wall clock time for QASMBench kernels under various compiler policies; extractor-based with parallel-injection dominates across resource settings.
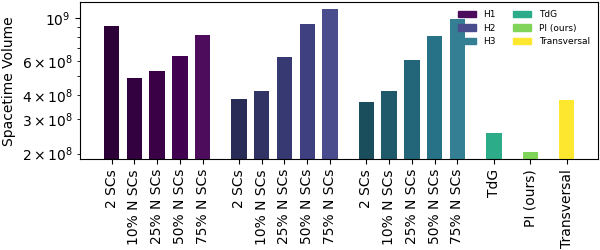
Figure 5: Spacetime volume for QASMBench suite—extractor-based architectures remain superior at all resource levels.
Sensitivity Analysis and Hybrid Architecture Limitations
Space-time efficiency is further scrutinized against:
- Synthesis precision ϵ: Higher R(φ) precision increases the relative benefit of extractor architectures, as non-Clifford synthesis dominates.
- Memory–compute code pairing: Results generalize across alternate QLDPC codes (e.g., HGPS, lifted product) and topological compute cores (surface, color codes); higher encoding rate QLDPCs further accentuate extractor-based advantages.
- T-state supply: Extraction protocol speedups manifest robustly with O(U)0 5 T-state factories; in the limit of severe T-state starvation, the base extractor and parallel schemes converge in latency.
Hybrid load/store architectures remain suboptimal in both space and time. Excessive thrashing (data movement and serialization) results in higher wall time without commensurate qubit savings. Spacetime-optimal operation is unattainable except in pathological precision regimes.
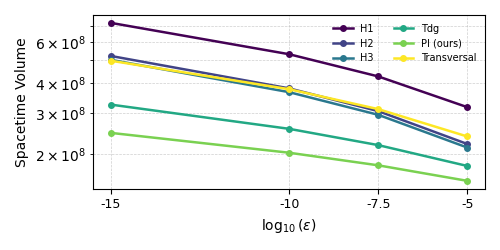
Figure 6: Sensitivity of extractor spacetime efficiency to rotation synthesis precision; extractor architectures outperform hybrids over all practical O(U)1.
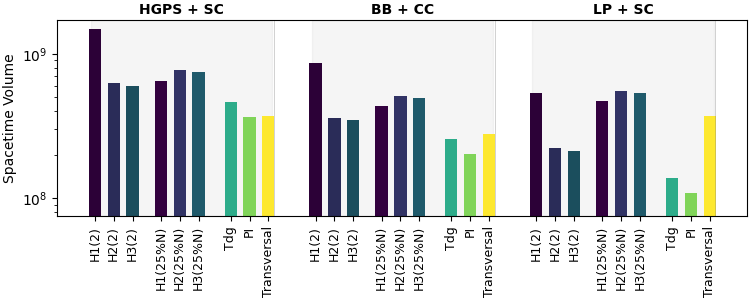
Figure 7: Hybrid code configurations—tradeoff curves for HGPS, BB, and LP codes paired with different transversal compute codes.
Explicit Hardware Realism: Gate Scheduling, Shuttling, and T Factory Integration
The simulation pipeline integrates low-level considerations such as shuttling, gate mapping, and non-deterministic T-state factory yields, aligning the instruction/cycle cost model to realistic neutral atom hardware. End-to-end simulations confirm the dominance of measurement latency and minimal impact of shuttling/gating, underlining the relevance of logical-level architectural optimizations.
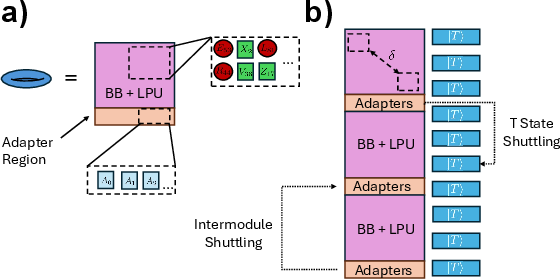
Figure 8: Physical mapping, modular decomposition, and shuttling schedule for two-gross and lifted product units; maximal interaction distance constraints and movement symmetry enable efficient inter-module coupling.
Theoretical Implications and Future Directions
The explicit identification of idle module exploitation and the development of a concrete, parallel-injecting extractor protocol advance the practice of Pauli-based compilation and modular QLDPC architectures. The work supports the case for prioritizing spatial efficiency and idle-resource utilization for early quantum advantage, rather than focusing resources on fully parallelizable transversal gates. It suggests that, particularly under the measurement bottleneck of neutral atom platforms, architectural innovation at the logical and compilation level directly delivers practical quantum outcomes.
Future directions include:
- Extension to dynamic mapping and adaptive scheduling algorithms responsive to T-state factory stochasticity.
- Exploration of universal extractor instruction sets for broader QLDPC classes.
- Hardware–software co-design for dynamically reconfigurable module geometries.
Conclusion
The study provides a decisive architectural framework for early fault-tolerant demonstrations of quantum advantage in neutral atom systems. By exploiting unutilized protocols for idle module utilization, and thoroughly quantifying space-time tradeoffs under realistic constraints, it motivates extractor-based, parallelized execution as the optimal strategy for near-term, large-scale, fault-tolerant quantum computation targeting dynamics simulation workloads. The explicit benchmarks and resource targets presented will guide both experimental roadmaps and continued architectural innovation in scalable quantum information processing.
Reference:
"Architecting Early Fault Tolerant Neutral Atoms Systems with Quantum Advantage" (2604.19735)