- The paper introduces MAGEO, a multi-agent system that integrates causal evaluation and memory-driven skill distillation to enhance generative engine optimization.
- It employs a Twin Branch evaluation protocol with the DSV-CF metric, achieving a Word-Level Visibility score of 4.52 and outperforming heuristic baselines.
- Reusable strategy learning and engine-specific preference modeling ensure cost-effective, scalable optimization while preserving content fidelity.
Multi-Agent Strategy Learning for Generative Engine Optimization: MAGEO
Introduction and Motivation
The transition from traditional Search Engine Optimization (SEO) towards Generative Engine Optimization (GEO) marks a fundamental change in information access and content creator visibility. LLM-based Generative Engines (GEs) such as Gemini, ChatGPT, and Qwen leverage Retrieval-Augmented Generation (RAG), producing citation-grounded answers instead of ranked lists. This shift moves the optimization locus from manipulating ranking to enhancing content impact within synthesized responses, posing four major challenges: opacity of presentation, undefined optimization metrics, unclear strategy paths, and ambiguous engine preferences.
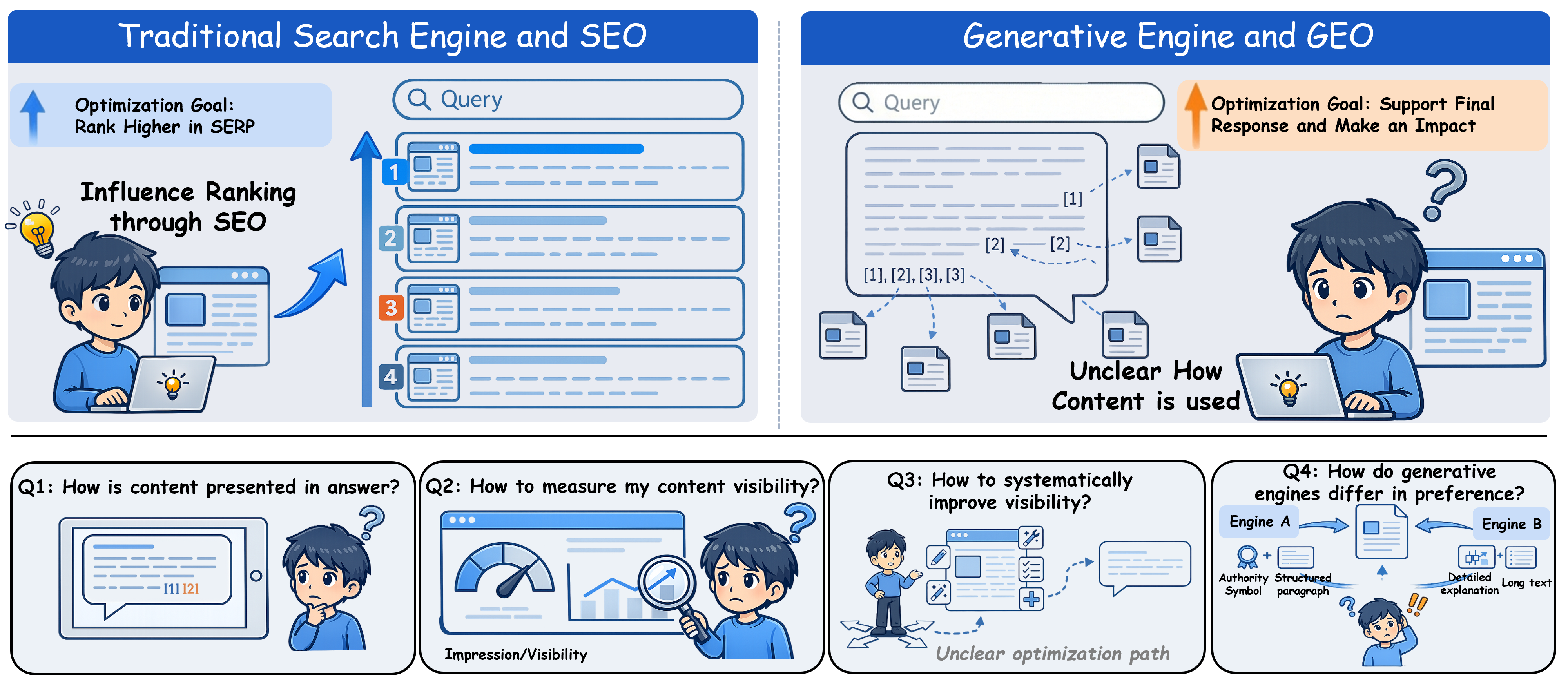
Figure 1: The paradigm shift from SEO to GEO, highlighting the transition from ranking goals to synthesis-based impact and four core optimization challenges.
Existing GEO approaches optimize each instance in isolation, disregarding accumulated experience and lacking mechanisms for strategy transfer or preference adaptation across engines. Previous work, including GEO and GEO-Bench, primarily employs heuristic-based metrics that treat visibility and attribution separately, often permitting exposure increments to coincide with miscitation. In response, the paper reframes GEO as a reusable strategy learning problem and presents MAGEO—a multi-agent system integrating causal evaluation, memory-driven skill distillation, and engine-specific preference modeling, supported by the robust benchmark MSME-GEO-Bench.
Methodological Framework
Twin Branch Evaluation Protocol and DSV-CF Metric
To address the black-box nature of GEs, the Twin Branch protocol establishes a controlled causal evaluation: it compares engine output with and without content edits under a frozen retrieval list, isolating the effect of optimizations. The optimization objective is the DSV-CF metric—a dual-axis formulation combining Surface Semantic Visibility (SSV) and Intrinsic Semantic Impact (ISI), penalized for citation inaccuracies:
SDSV−CF=λ⋅SˉSSV+(1−λ)⋅SˉISI−γ(1−AA)
with λ=0.5 and γ=0.5 in default settings to balance visibility and fidelity.
Multi-Agent Architecture and Reusable Strategy Learning
MAGEO operates with four collaborating agents: Preference, Planner, Editor, and Evaluator. The Preference Agent models engine-specific citation preferences from large-scale data. The Planner synthesizes the profile and retrieves relevant skills from the Skill Bank to propose strategic edits. The Editor implements these edits via parallel sampling, and the Evaluator predicts DSV-CF gains, enforcing a fidelity gate to maintain semantic consistency.
The Skill Bank acts as a memory buffer, abstracting effective edit patterns into transferable, engine-scenario-indexed strategies. Step-level memory records outcomes within an optimization session, while creator-level memory consolidates recurring techniques. Retrieval from the Skill Bank allows rapid strategy deployment for new instances, reducing exploration costs and increasing optimization efficiency.
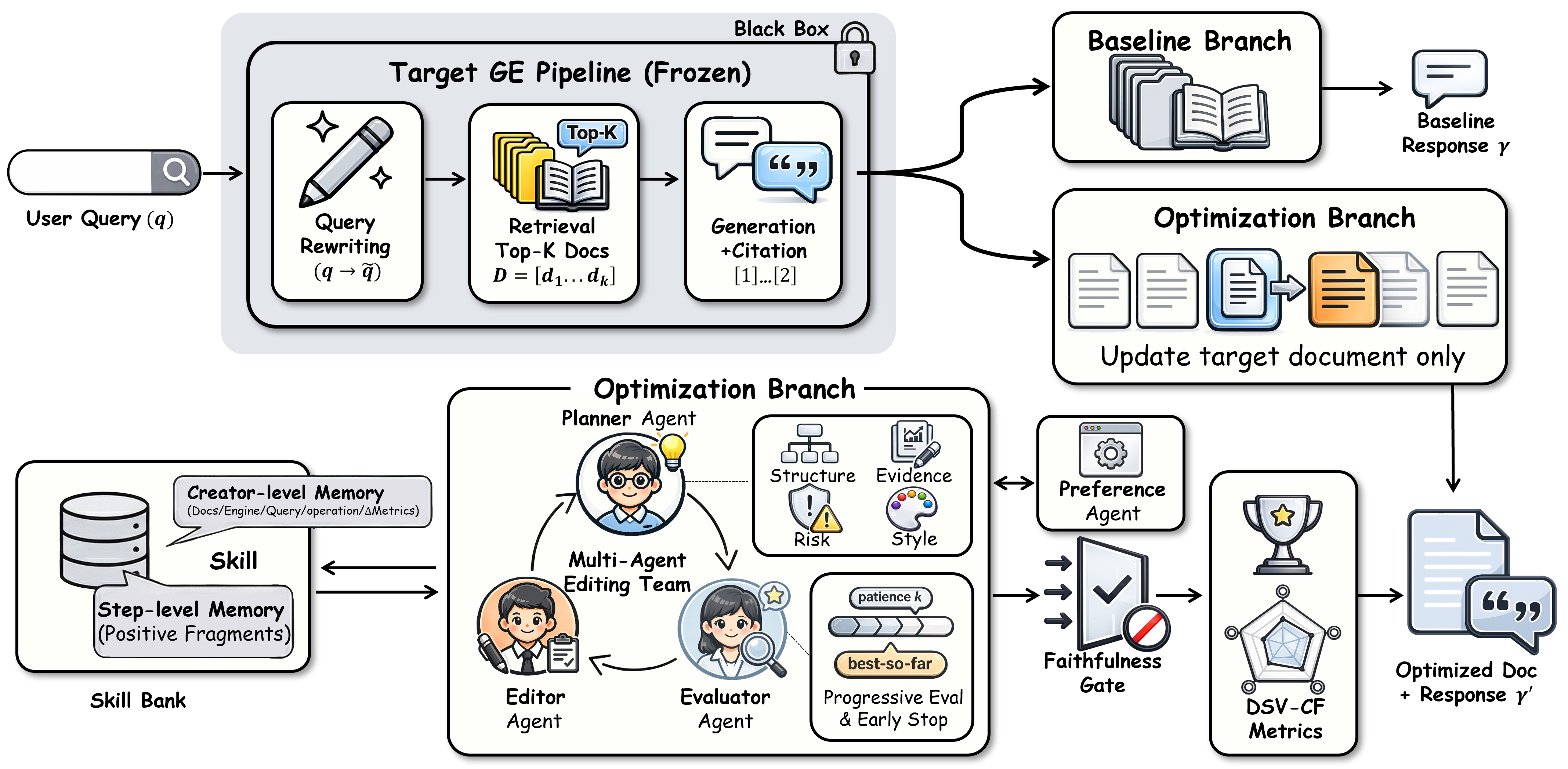
Figure 2: Overview of MAGEO under Twin-Branch protocol, detailing baseline and optimization branches, agent interplay, and Skill Bank integration.
MSME-GEO-Bench: Benchmark Construction
Grounded in Everyday Life Information Seeking (ELIS) theory, MSME-GEO-Bench encompasses five primary domains and fifteen sub-categories of real-world user queries. Its construction pipeline utilizes content-aware reverse query generation, closed-loop retrieval validation, fine-grained annotation, and model/human bias control. This ensures strong query-document alignment and observable optimization impact under authentic generative conditions.
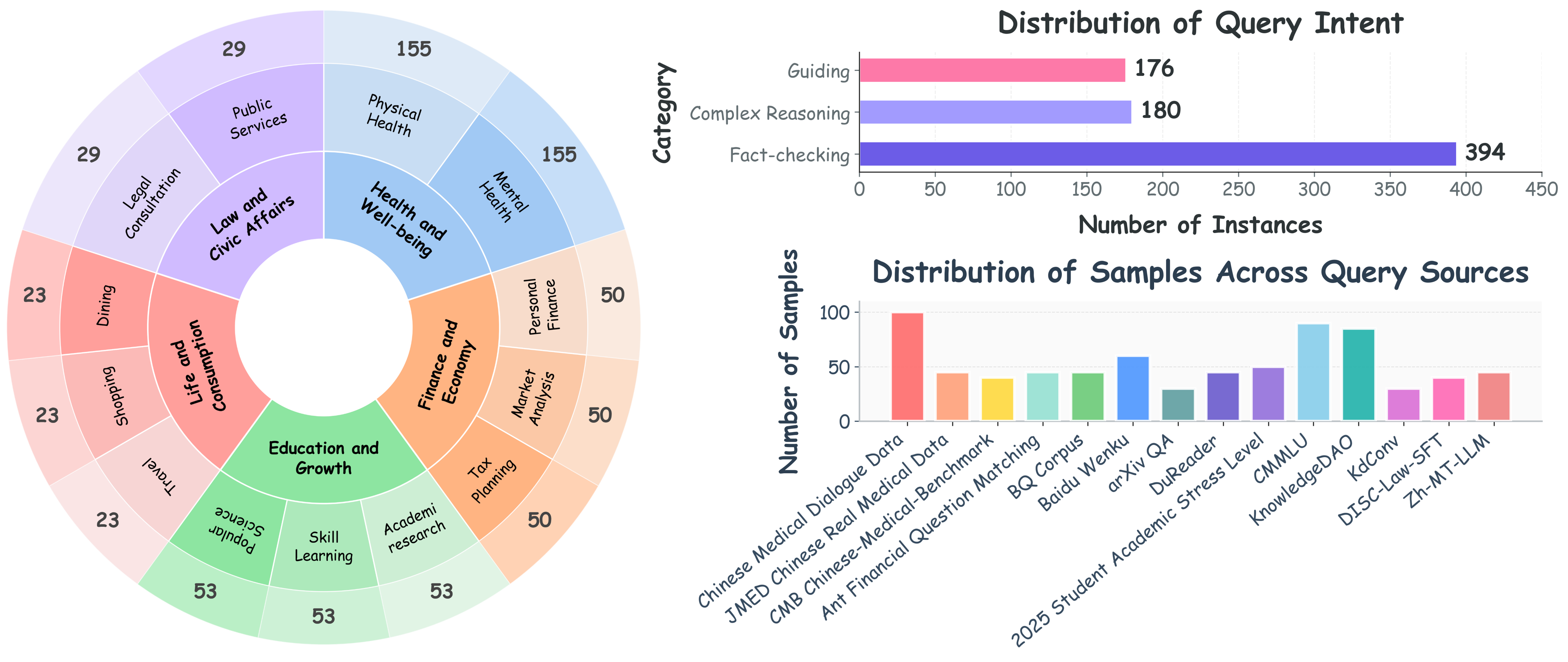
Figure 3: MSME-GEO-Bench coverage analysis—query scenario distribution and intent/sample source diversity.
Experimental Results
Quantitative Gains and Fidelity Control
MAGEO sets a new performance standard across MSME-GEO-Bench with GPT-5.2 and Gemini-3 Pro, as well as open-weight engines like Qwen-3 Max. MAGEO achieves a Word-Level Visibility (WLV) score of 4.52 with GPT-5.2 (compared to the strongest heuristic baseline at 1.33), with parallel gains across Citation Prominence, Subjective Impression, and Attribution Accuracy. These improvements are not simply superficial, as increased visibility coincides with improved or preserved faithfulness and reduced hallucination. Ablation studies demonstrate that engine-specific preference modeling and Skill Bank reuse are indispensable for optimal gains, inducing 19% and 13% performance drops upon removal, respectively.
Evolutionary Optimization Trajectory and Cost-Effectiveness
Through iterative rounds, MAGEO’s visibility and fidelity scores peak early (approximately Version 5), after which further edits diminish returns and may threaten faithfulness. This motivates dynamic early stopping. Cost-effectiveness analysis demonstrates that MAGEO Lite captures most visibility gains at only 2.9× the token cost of the quote-based baseline, with marginal improvements for MAGEO Full at higher token budgets.
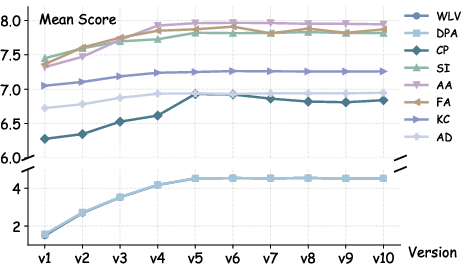
Figure 4: Evolutionary optimization trajectory showing rapid gains before performance plateaus.
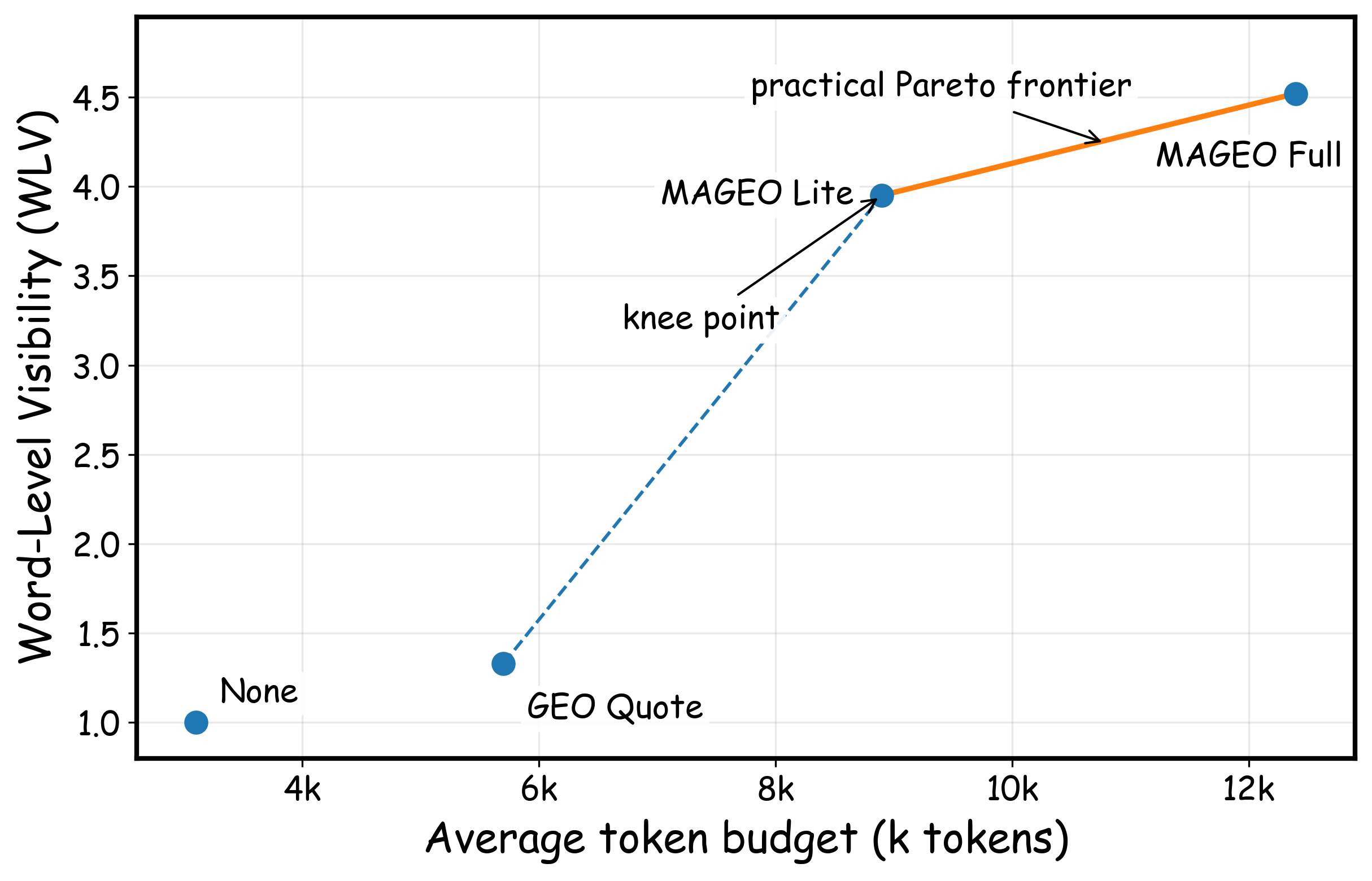
Figure 5: Pareto frontier analysis on cost-effectiveness, identifying MAGEO Lite as the knee point.
Combo Baseline Comparison and Reliability
MAGEO outperforms combinatorial baselines stacking multiple heuristic strategies, underscoring that its gains are not simply additive but arise from coordinated agentic optimization and transferable strategy learning. The LLM-based DSV-CF metric aligns strongly with human expert assessment (ρ=0.81 Spearman correlation), validating its reliability for scalable evaluation.
Practical and Theoretical Implications
MAGEO transforms GEO from ad hoc, rule-based heuristics into a structured, cumulative learning process, enabling trustable optimization scalable across engines and scenarios. By operationalizing memory-driven skill distillation and preference adaptation, it offers a foundation for robust content visibility and attribution fidelity in GE-dominated information ecosystems. Practically, MAGEO’s protocol and benchmark facilitate reproducible evaluation and skill generalization studies, while its methodological design anticipates integration with multimodal and adaptive optimization frameworks.
Future Directions
The study highlights several avenues: expanding MSME-GEO-Bench for subgroup granularity, formal skill generalization analysis, multimodal GEO adaptation, and dynamic skill maintenance against engine distribution drift. As generative engines evolve, continual learning-based frameworks will be necessary for sustained optimization.
Conclusion
MAGEO reframes GEO as a strategy learning task, coupling multi-agent iterative optimization with reusable skills under controlled causal evaluation. Empirical results confirm substantial visibility and fidelity improvements on diverse, realistic benchmarks, validating the critical roles of engine-specific preference modeling and memory-driven skill transfer. The framework suggests that GEO is most effectively approached as a structured, adaptive learning process, paving the way for scalable, trustworthy content optimization in generative search environments.

