- The paper introduces a novel Generative Engine Optimization framework that rigorously compares AI-powered search engines with Google using controlled experimental metrics.
- It demonstrates a dominant bias toward earned media in AI search results and a low overlap with traditional Google outputs, impacting digital content strategies.
- The study highlights the effects of engine-specific localization and language sensitivity, urging practitioners to develop tailored strategies to overcome big brand bias.
Generative Engine Optimization: Empirical Foundations and Strategic Implications for AI Search
Introduction: From SEO to GEO in the Age of Generative Search
The proliferation of generative AI-powered search engines—such as ChatGPT, Perplexity, Gemini, and Claude—has fundamentally altered the information retrieval landscape. Unlike traditional search engines that return ranked lists of hyperlinks, these systems synthesize narrative answers, often with explicit citations. This paradigm shift disrupts established Search Engine Optimization (SEO) practices and necessitates a new discipline: Generative Engine Optimization (GEO). The paper presents a comprehensive, empirical analysis of how AI search engines differ from Google in their sourcing, ranking, and citation behaviors, and formulates a strategic GEO agenda grounded in these findings.
Methodology: Large-Scale, Multi-Dimensional Comparative Analysis
The study employs a rigorous, controlled experimental pipeline to compare Google and leading AI search engines across multiple axes:
- Query Generation: Standardized ranking-style prompts, paraphrased and translated into multiple languages, spanning diverse verticals (consumer electronics, automotive, software, local services).
- Engine Execution: Parallel querying of Google (via Programmable Search API) and web-enabled AI engines (GPT-4o, Perplexity, Claude, Gemini), with extraction of both answer text and cited URLs.
- Domain Classification: All cited domains are normalized and classified as Brand (official), Earned (third-party editorial/review), or Social (community/user-generated).
- Overlap and Diversity Metrics: Top-k overlap, Jaccard similarity, and exclusivity measures quantify the alignment and divergence between engines.
- Freshness and Language Sensitivity: Publication dates and website language are extracted to assess recency and localization.
A central empirical finding is the systematic and overwhelming bias of AI search engines toward Earned media—third-party, authoritative sources—at the expense of Brand-owned and Social content. This is in stark contrast to Google, which maintains a more balanced mix.
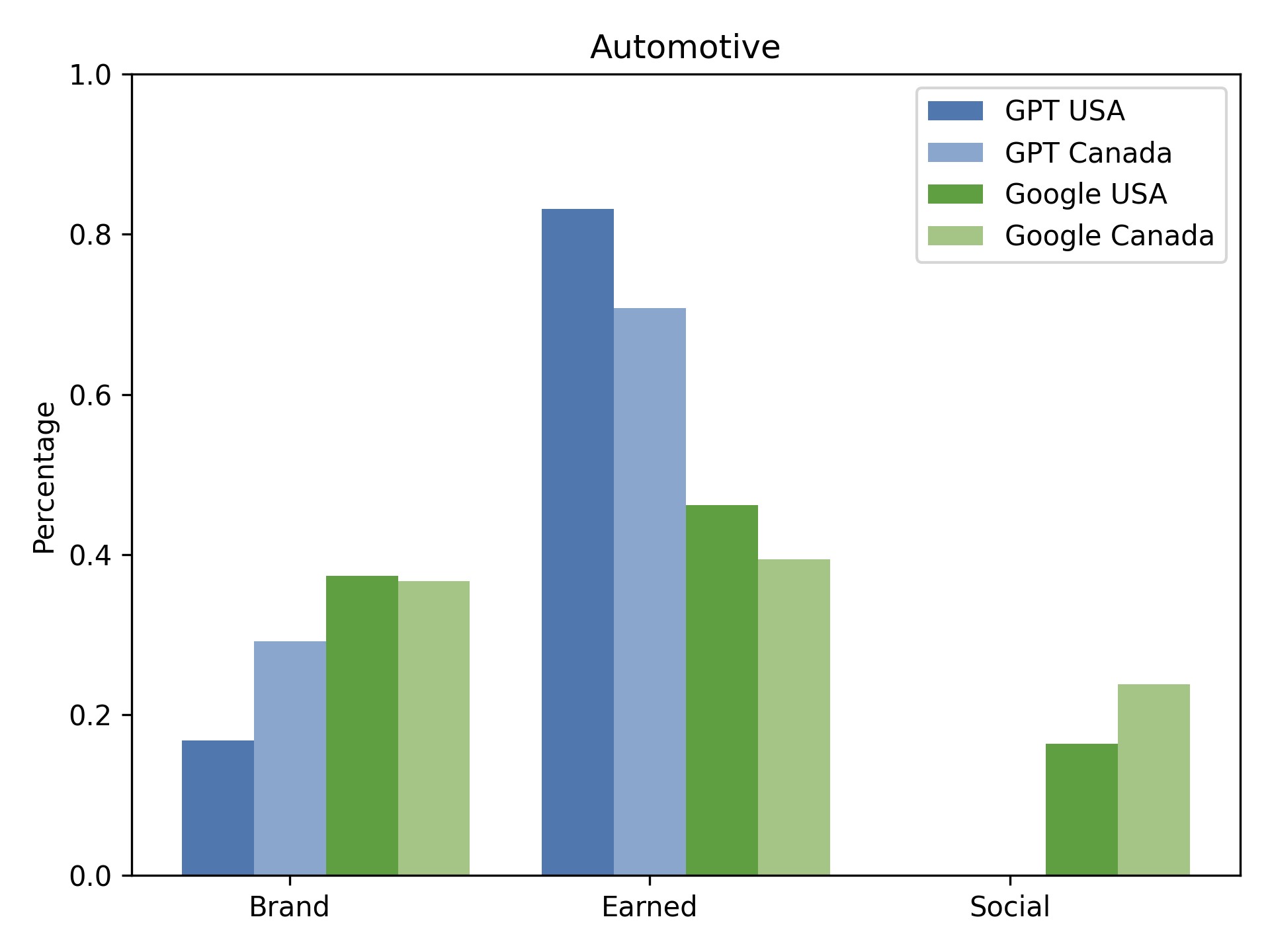
Figure 1: Automotive: Distribution of source types (Brand, Earned, Social) across Google and GPT in Canada and USA.
In the automotive vertical, for example, AI search results in the US are 81.9% Earned, 18.1% Brand, and 0% Social, whereas Google returns 45.1% Earned, 39.5% Brand, and 15.4% Social. This pattern is consistent across consumer electronics and software products, with AI engines nearly eliminating Social sources (e.g., Reddit, Quora) from their outputs.
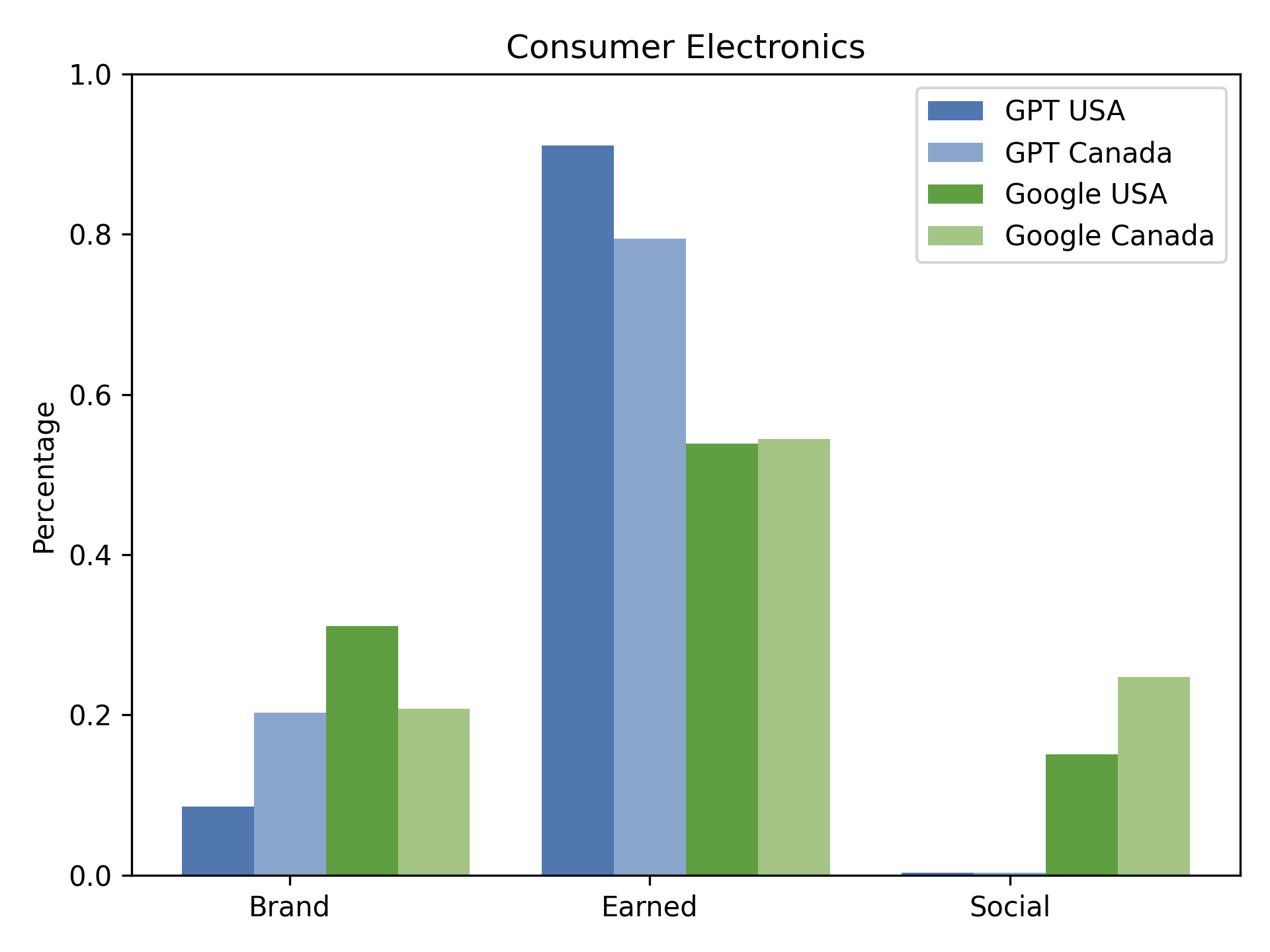
Figure 2: Consumer Electronics: Distribution of source types (Brand, Earned, Social) across Google and GPT in Canada and USA.
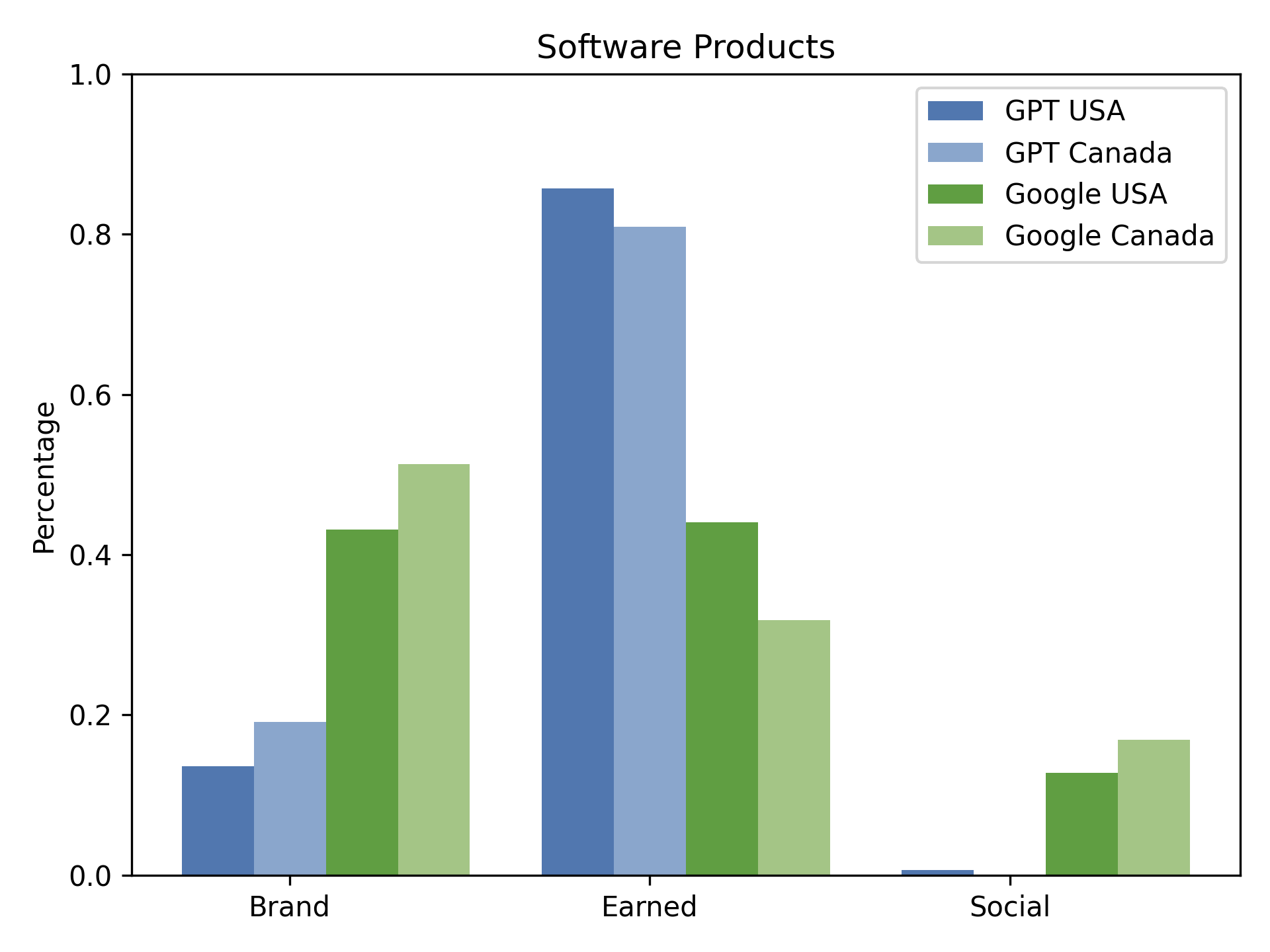
Figure 3: Software Products: Distribution of source types (Brand, Earned, Social) across Google and GPT in Canada and USA.
Low Overlap and High Fragmentation: Divergence in Evidence Ecosystems
The overlap between Google and AI engines in cited domains is consistently low, especially in product and local service queries.
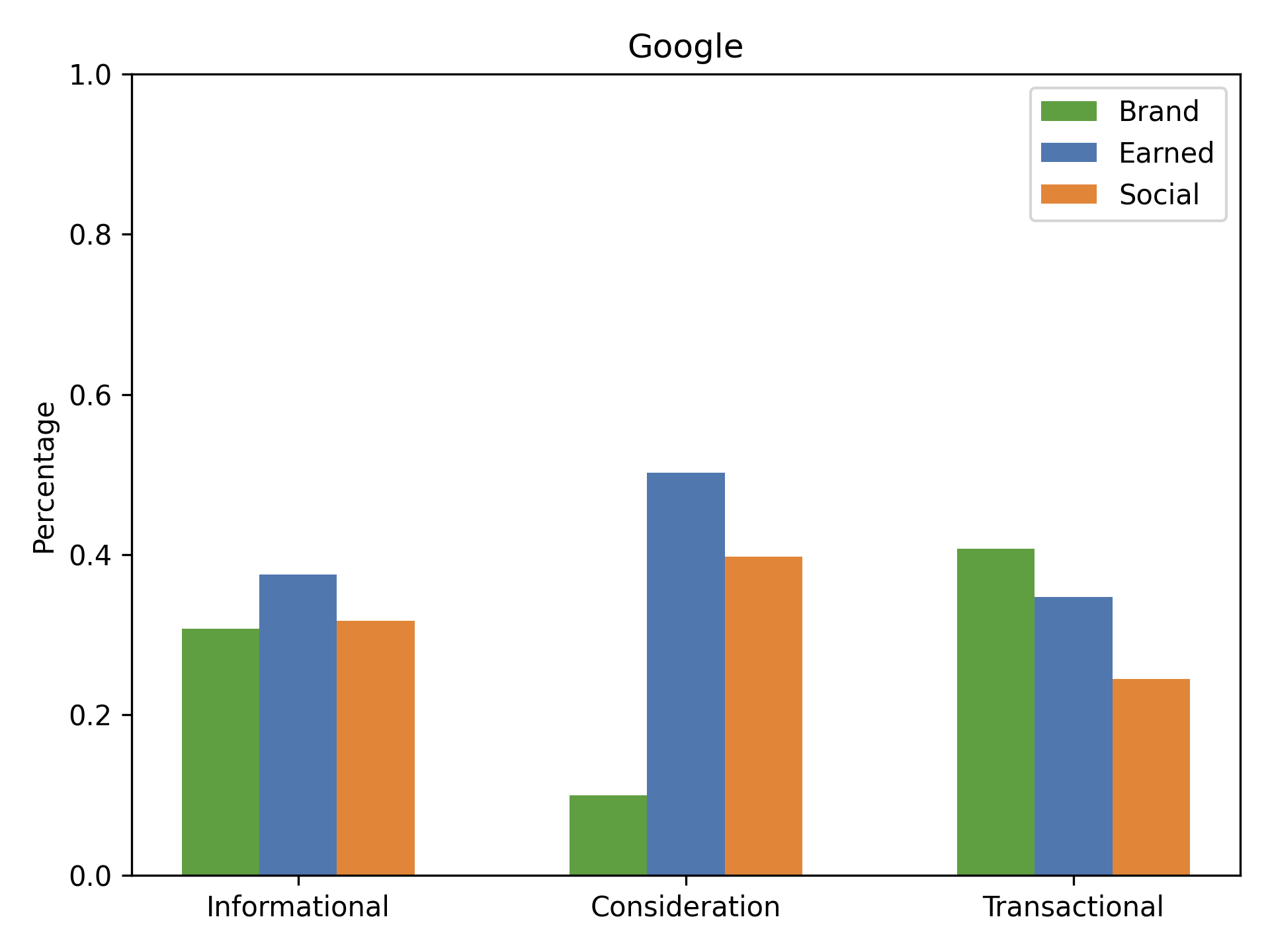
Figure 4: Referenced Links Overlap Comparison (Google/GPT) for k=5 and k=10.
For local business queries, overlap is even lower, with categories such as Auto Repair and IT Support showing near-zero intersection. This fragmentation is further exacerbated by high domain diversity and exclusivity across AI engines themselves.
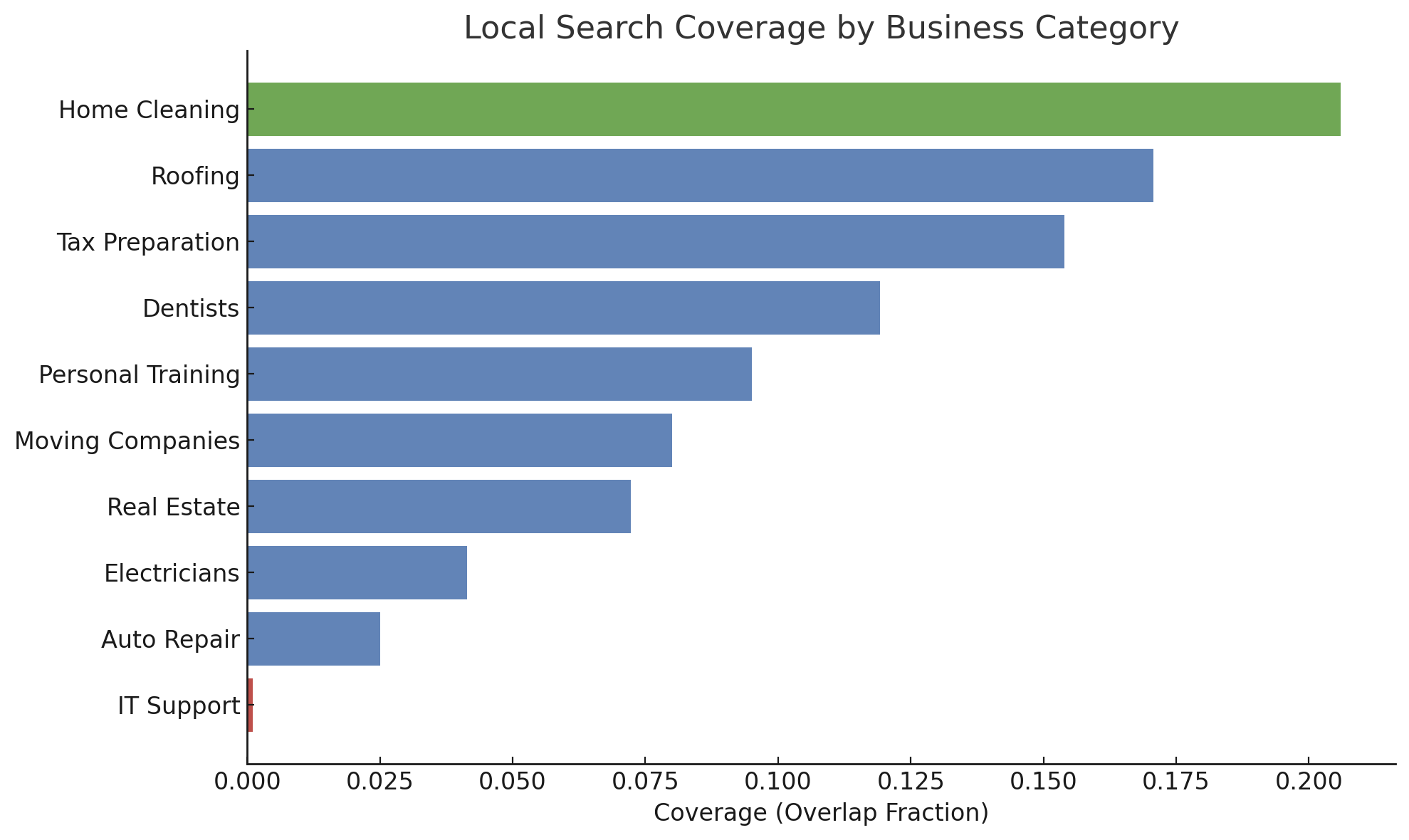
Figure 5: Local Search Coverage by Business Category. Coverage reflects the fraction of overlapping domains between AI search and Google for local business queries.
Language and Paraphrase Sensitivity: Engine-Dependent Localization and Robustness
The study demonstrates that language localization is highly engine-dependent. Claude exhibits high cross-language stability, often reusing English-language authority domains across translations, while GPT and Perplexity localize aggressively, sourcing almost entirely from the target language's ecosystem.
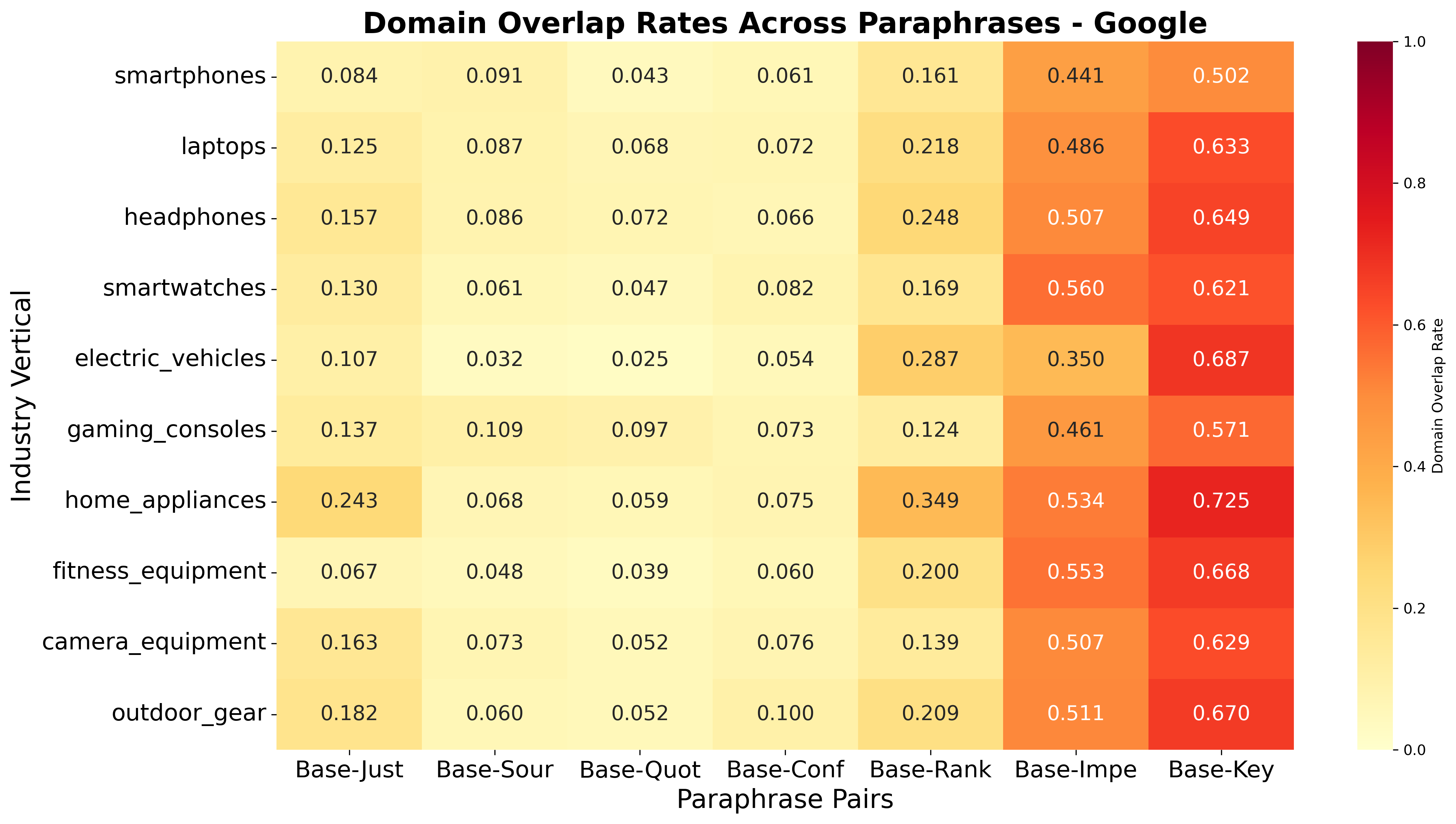
Figure 6: Language Sensitivity: Domain overlap heatmap, Google
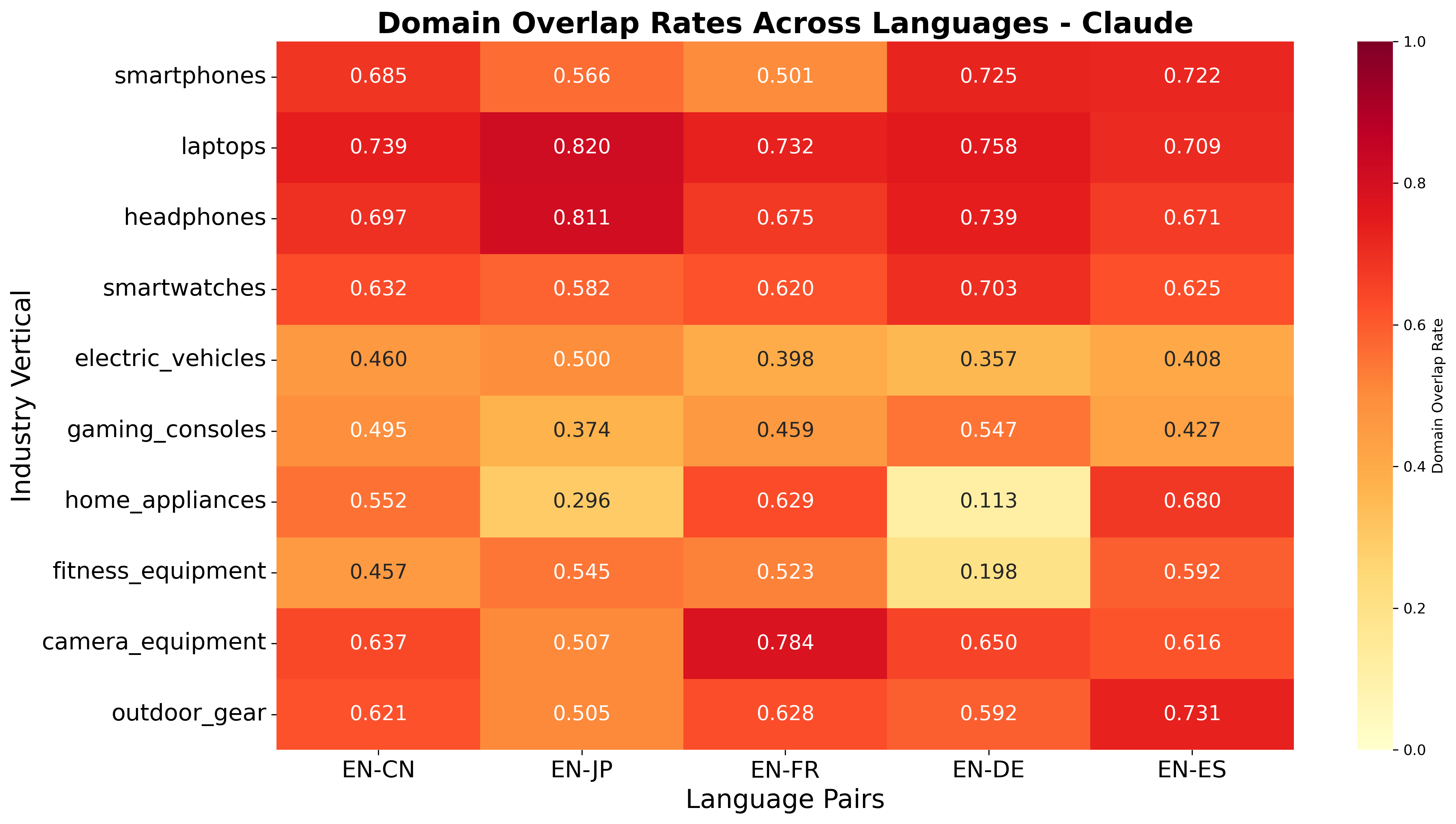
Figure 7: Language Sensitivity: Domain overlap heatmap, Claude
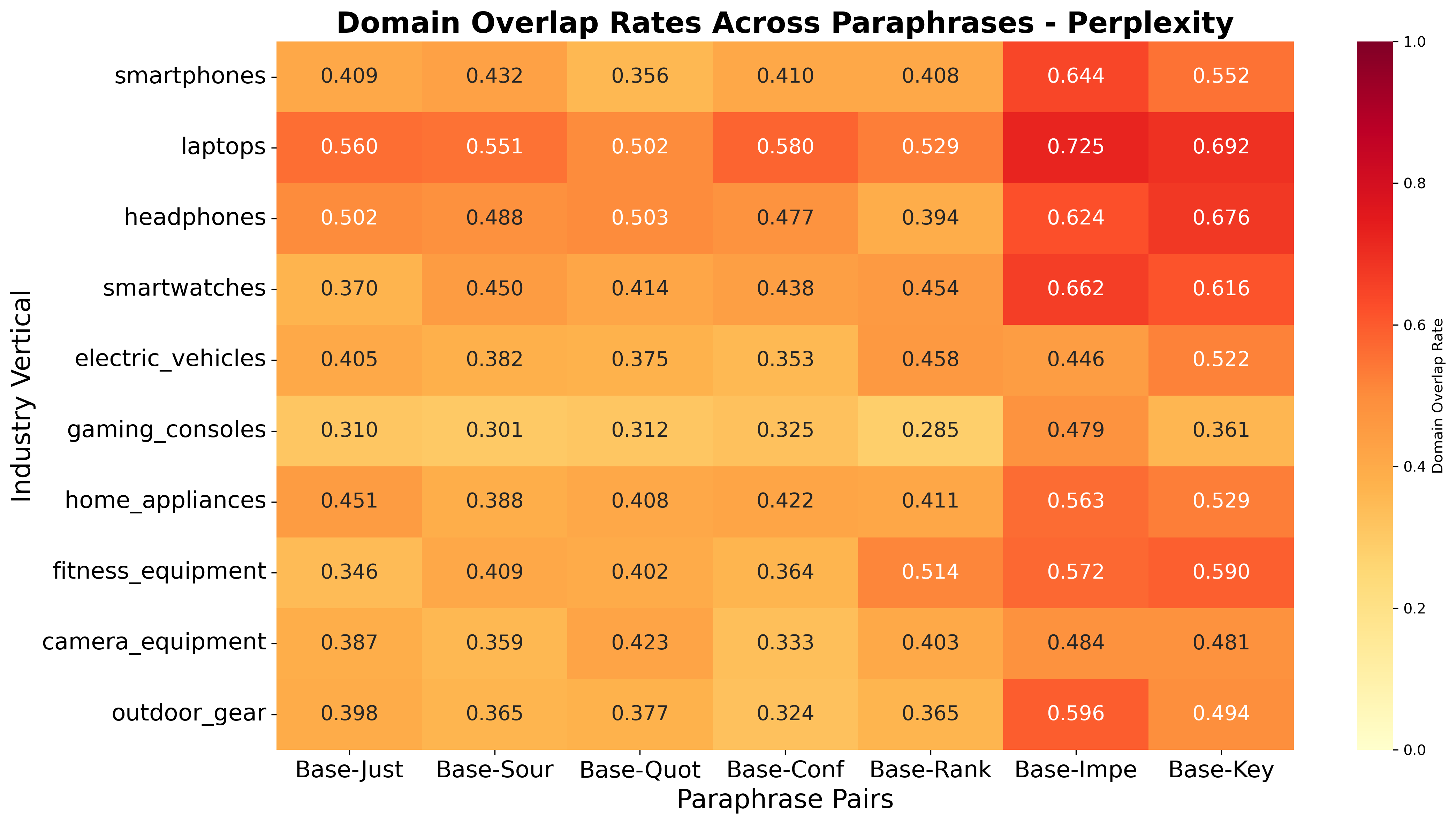
Figure 8: Language Sensitivity: Domain overlap heatmap, Perplexity
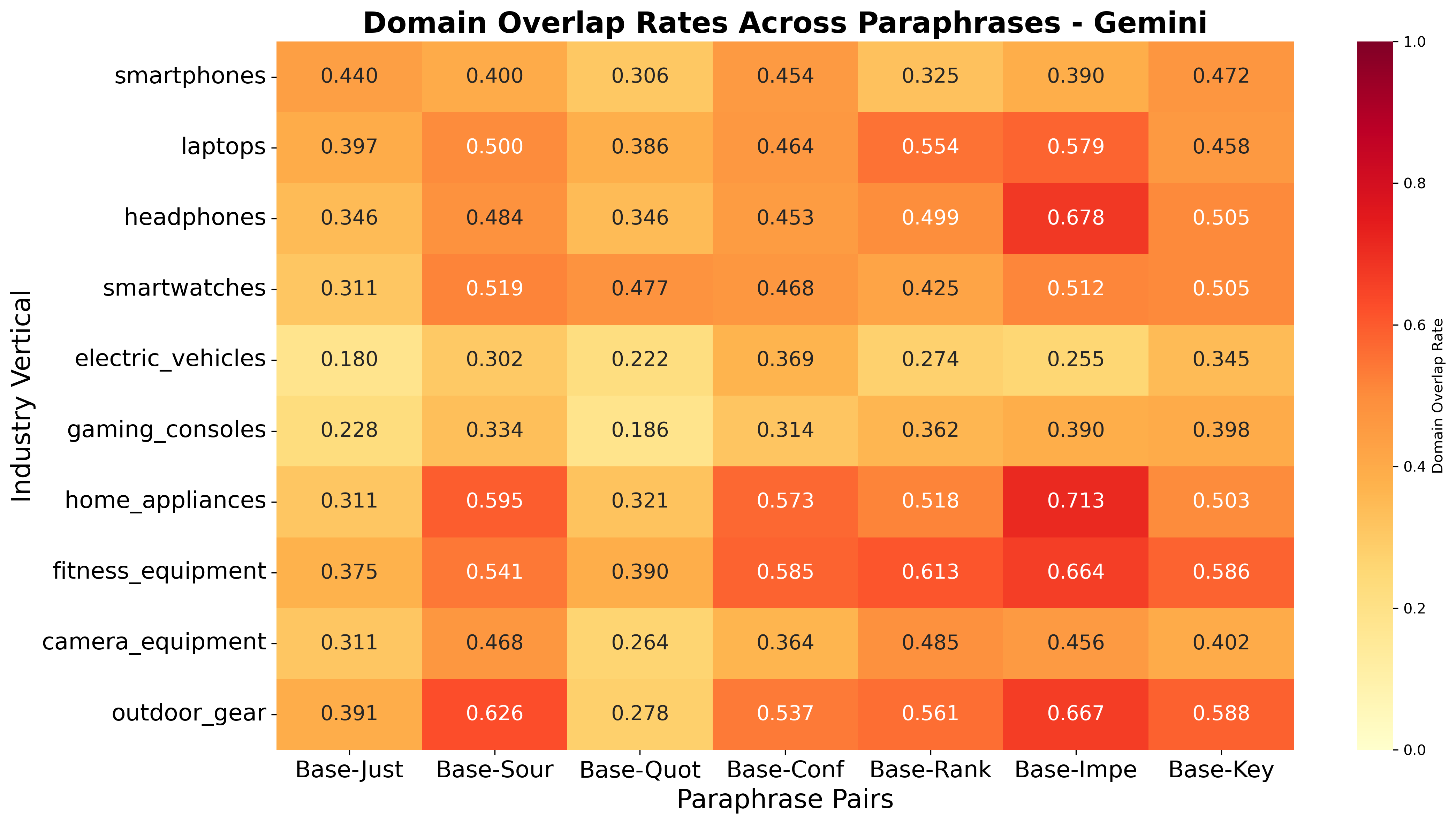
Figure 9: Language Sensitivity: Domain overlap heatmap, Gemini
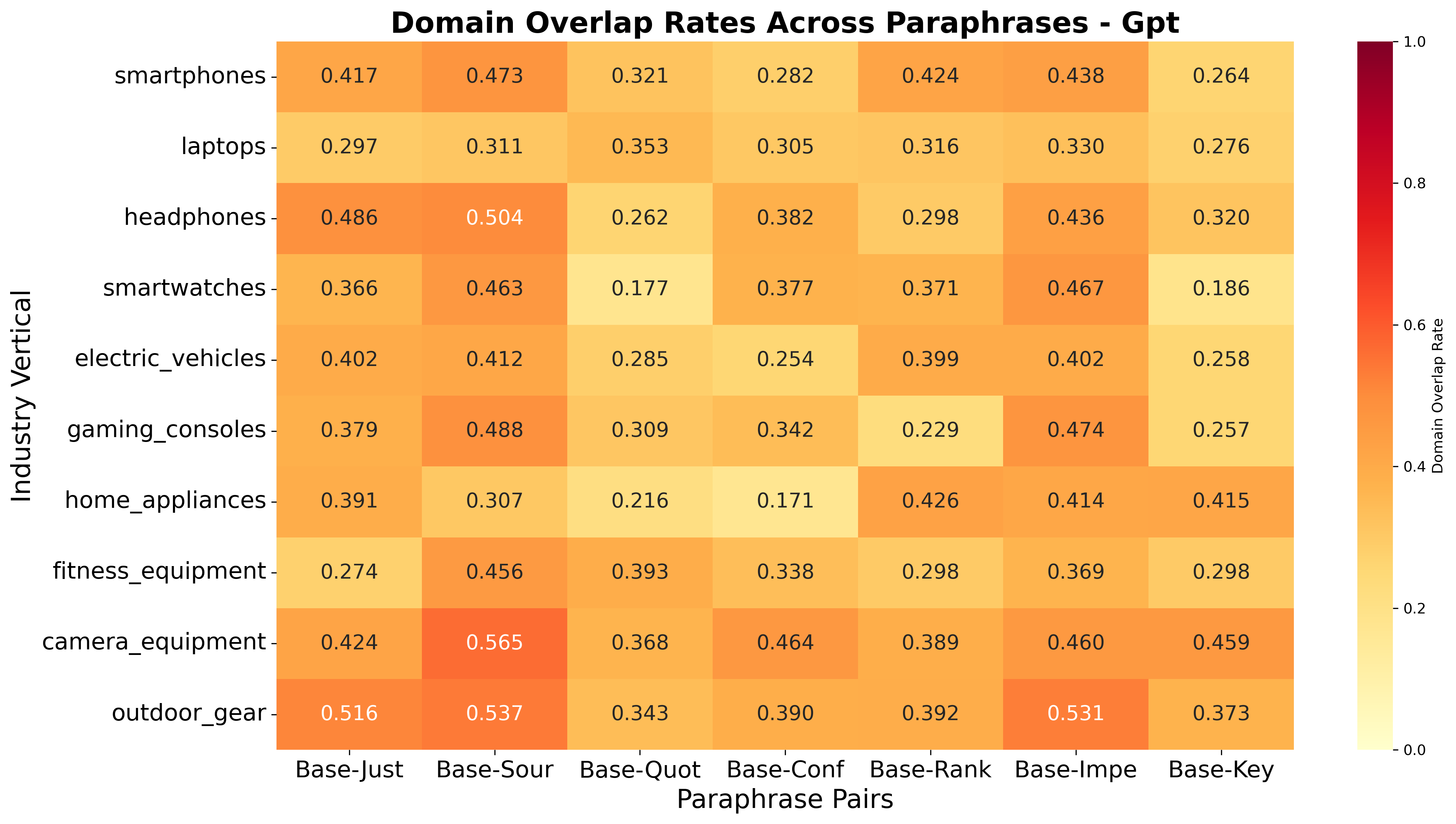
Figure 10: Language Sensitivity: Domain overlap heatmap, GPT
Despite these differences, all AI engines maintain an earned-heavy distribution across languages.
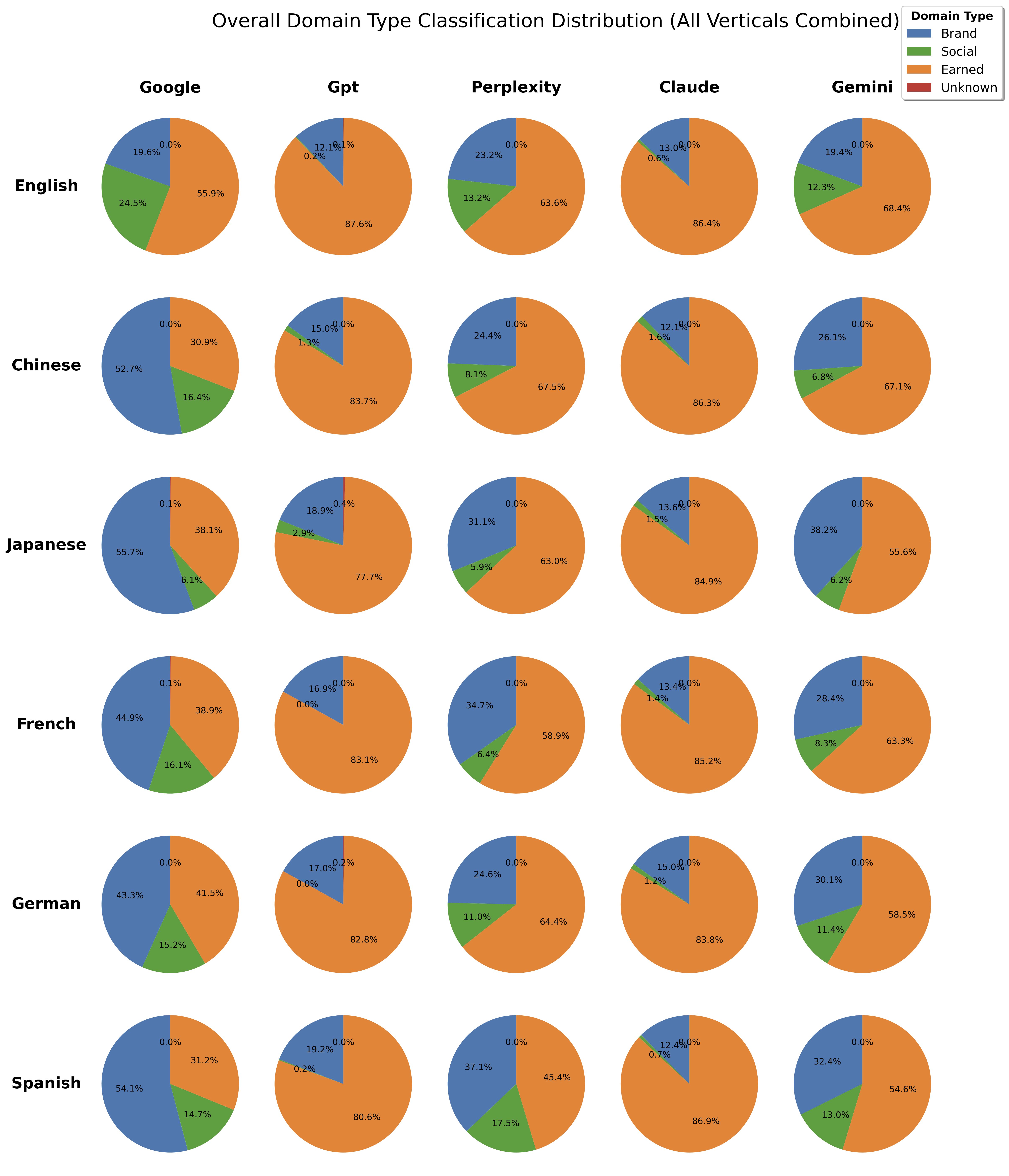
Figure 11: Language Sensitivity: Overall domain-type distribution, all languages pooled
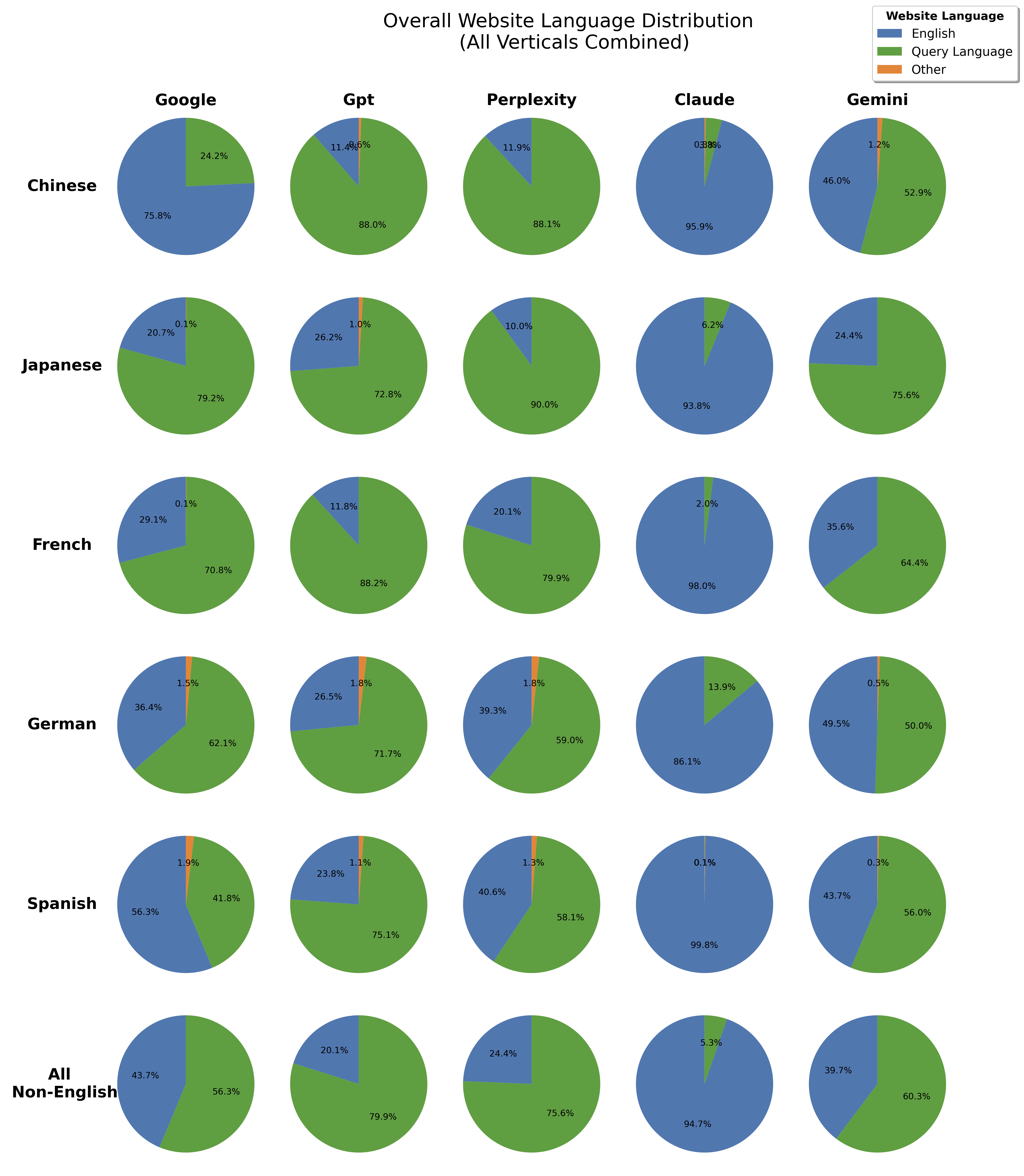
Figure 12: Language Sensitivity: Overall website-language distribution, all verticals pooled
In contrast, paraphrasing within a language has a much smaller effect on both brand and domain overlap, indicating that AI engines are robust to minor rewordings but sensitive to language shifts.
Figure 13: Paraphrase Sensitivity: Domain overlap heatmap, Google
Figure 14: Paraphrase Sensitivity: Domain overlap heatmap, GPT
Figure 15: Paraphrase Sensitivity: Domain overlap heatmap, Perplexity
Figure 16: Paraphrase Sensitivity: Domain overlap heatmap, Gemini
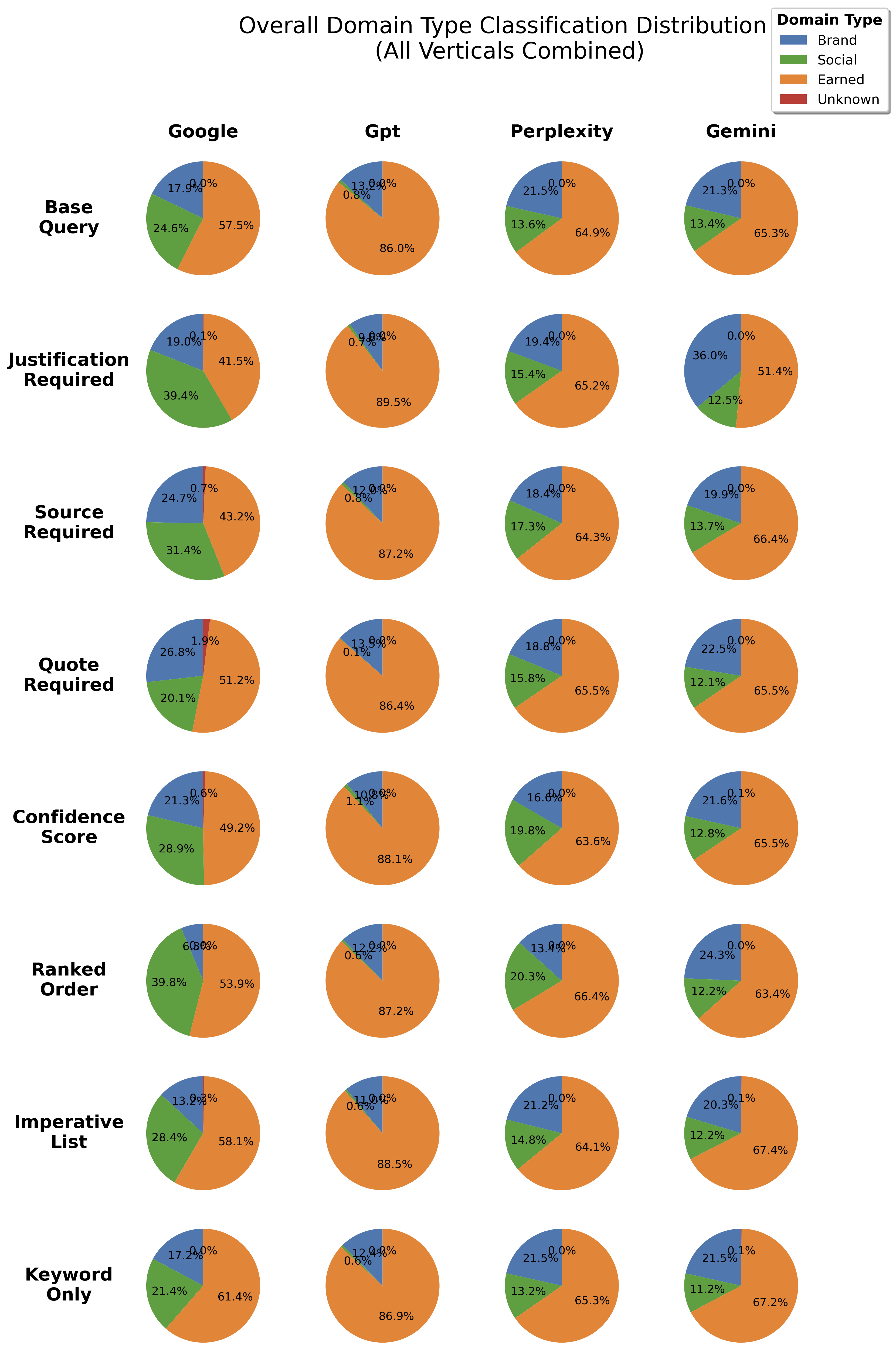
Figure 17: Paraphrase Sensitivity: Overall domain-type distribution across paraphrase styles
The media-type distribution varies with query intent (informational, consideration, transactional), but the earned-heavy bias of AI engines persists.
Figure 18: Media-type distribution (Brand, Earned, Social) across query intents for Google.
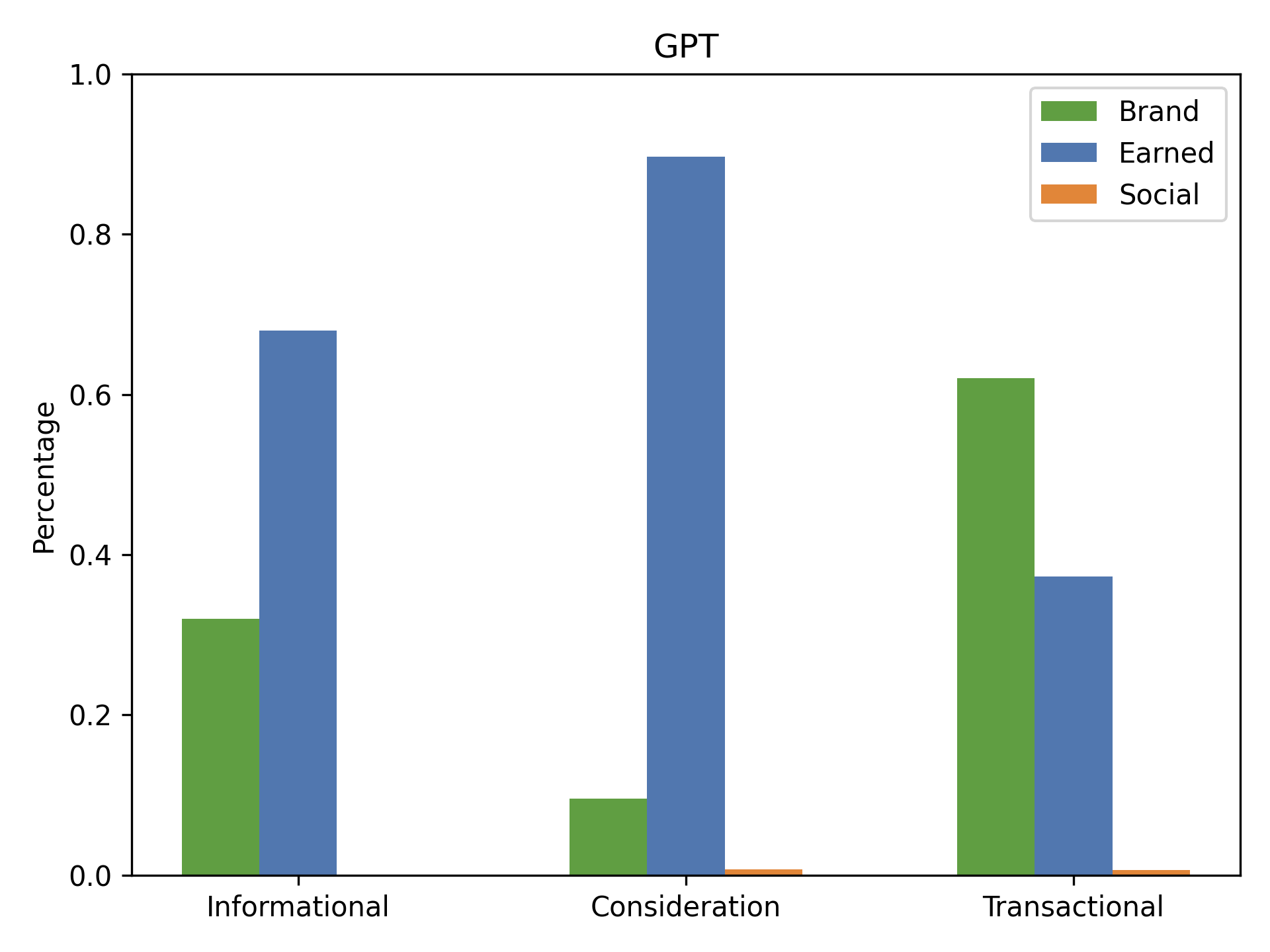
Figure 19: Media-type distribution (Brand, Earned, Social) across query intents for GPT.
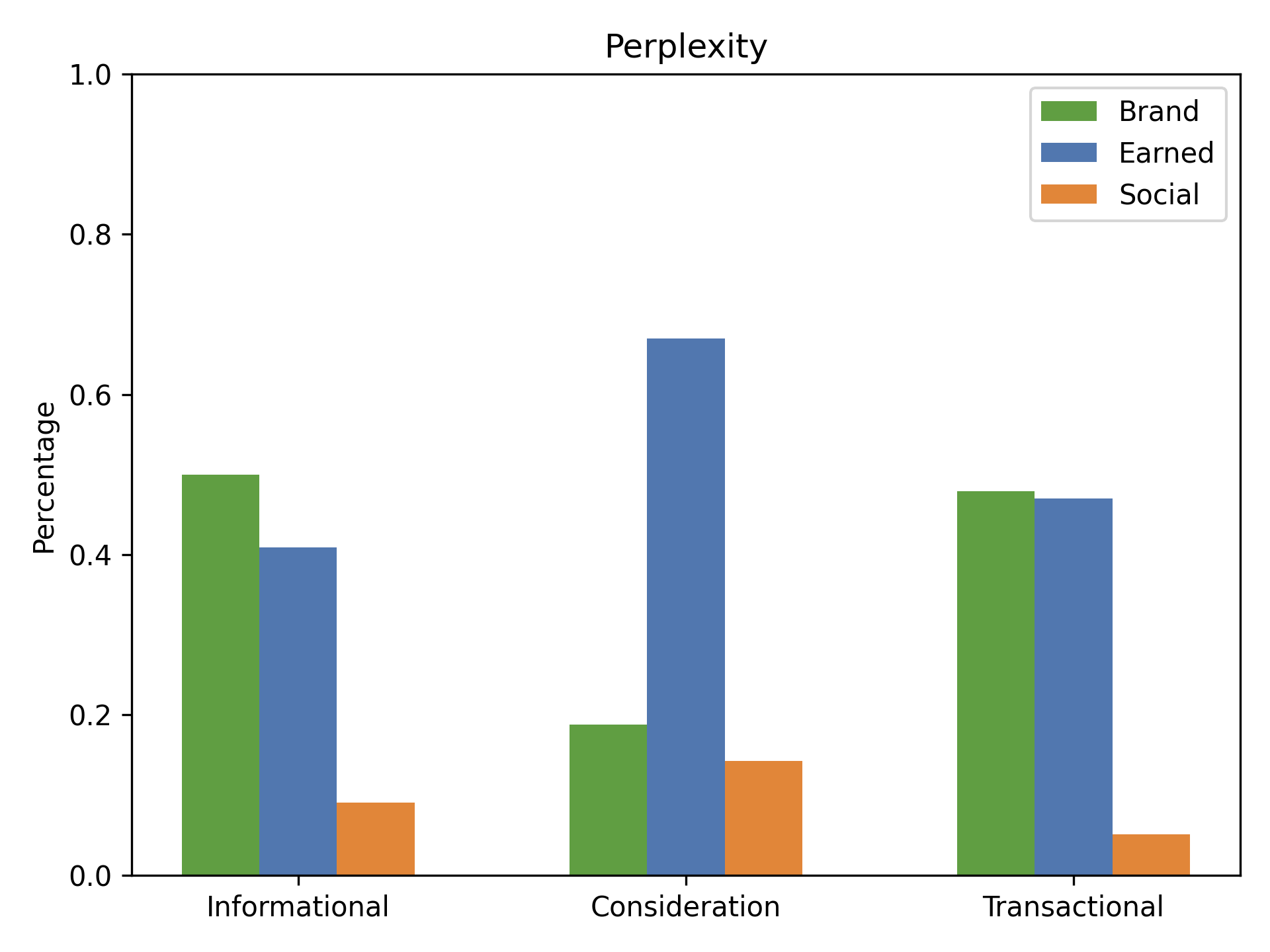
Figure 20: Media-type distribution (Brand, Earned, Social) across query intents for Perplexity.
Google balances Brand, Earned, and Social sources across intents, while GPT and Claude suppress Social and amplify Earned, especially for consideration queries.
Cross-Engine Comparison: Domain Diversity, Freshness, and Brand Bias
AI engines differ significantly in their domain diversity, recency, and treatment of well-known vs. niche brands.
- Claude and GPT: Maximize Earned exposure, low Brand/Social, high cross-language stability, but risk staleness in some verticals.
- Perplexity: More inclusive, higher Brand and Social shares, greater domain diversity, and fresher content.
- Gemini: Intermediate, with a higher Brand share than Claude/GPT and moderate Social inclusion.
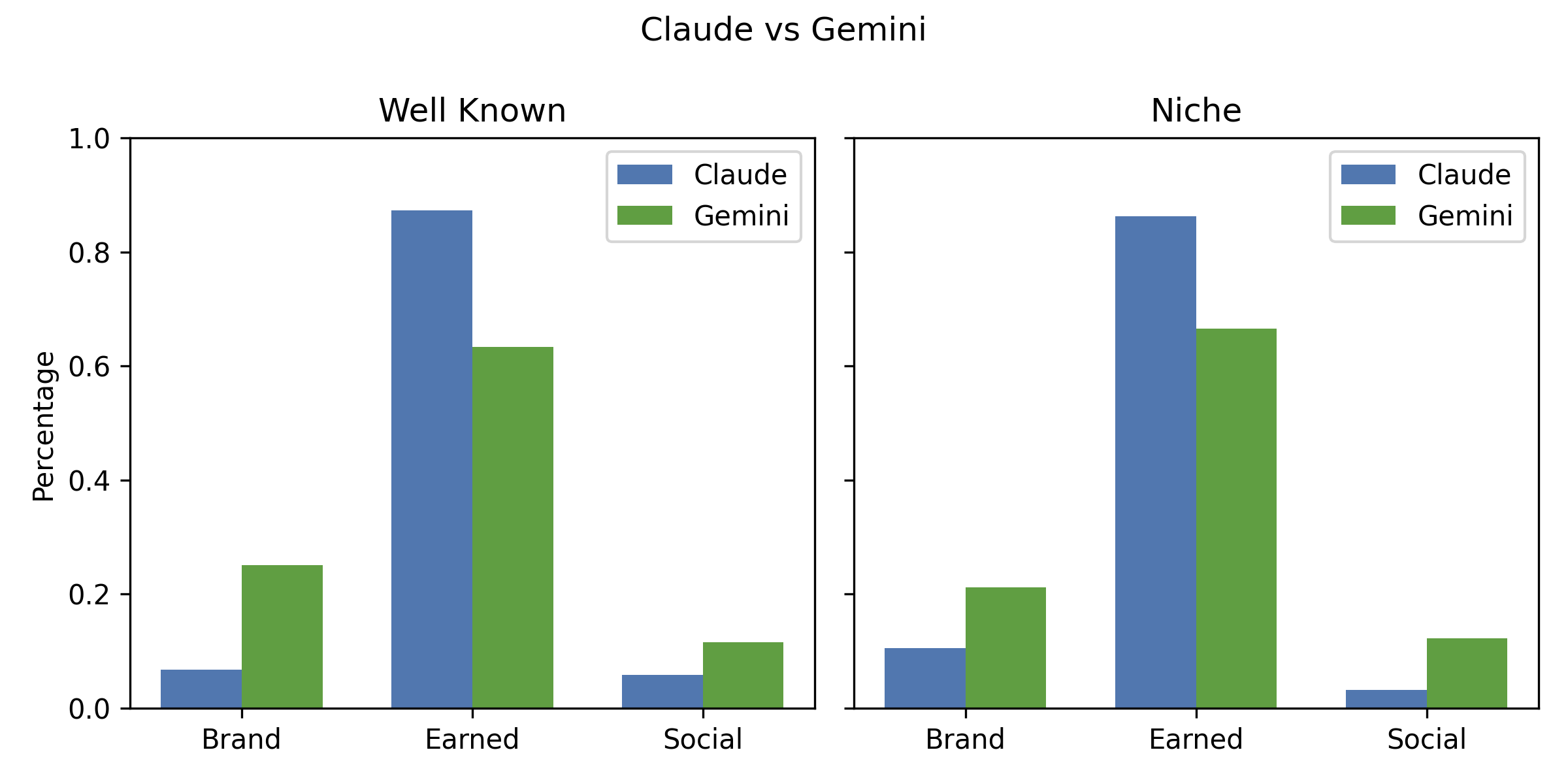
Figure 21: Comparison of Claude vs.~Gemini for well-known and niche brands.
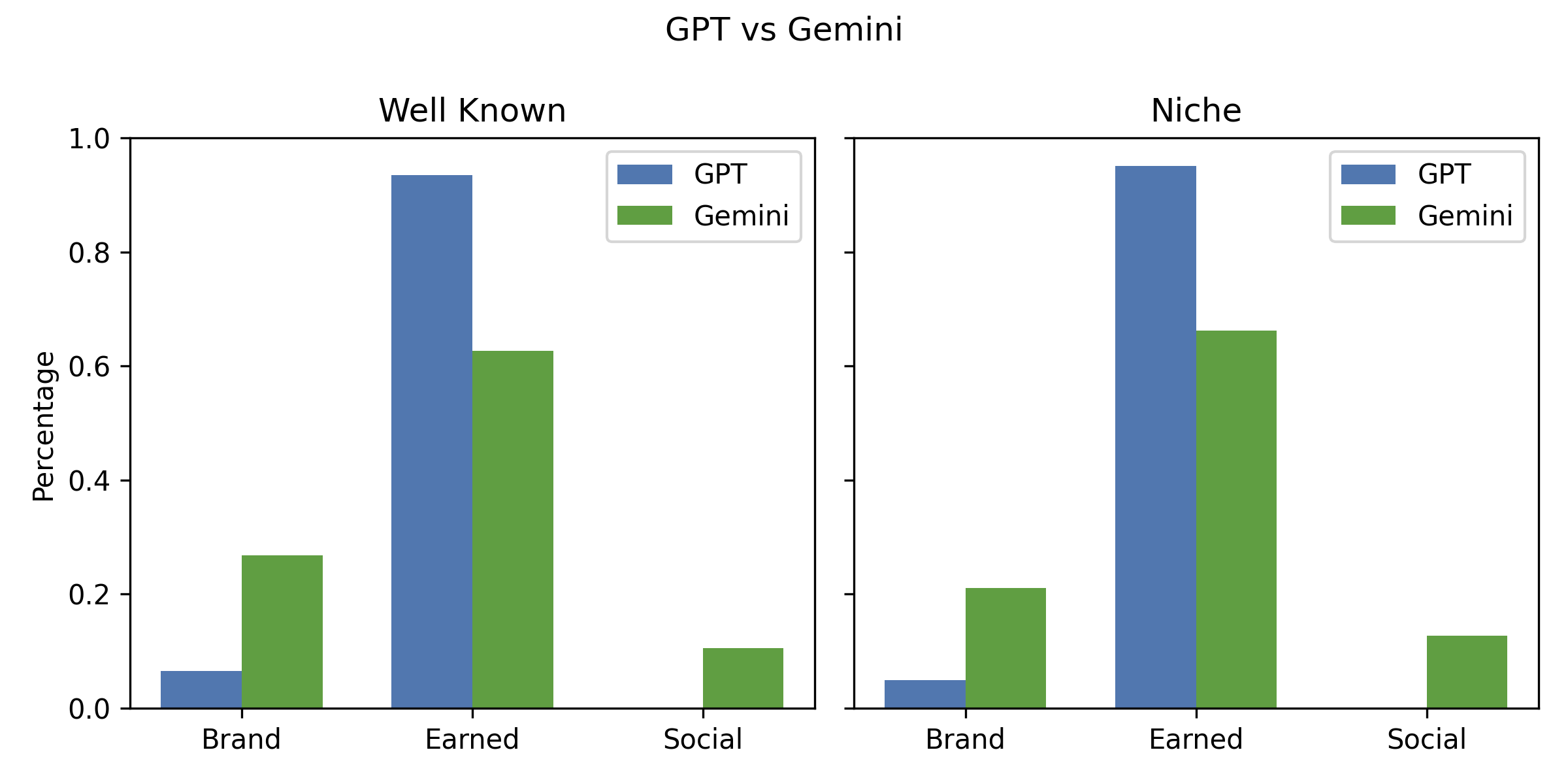
Figure 22: Comparison of GPT vs.~Gemini for well-known and niche brands.
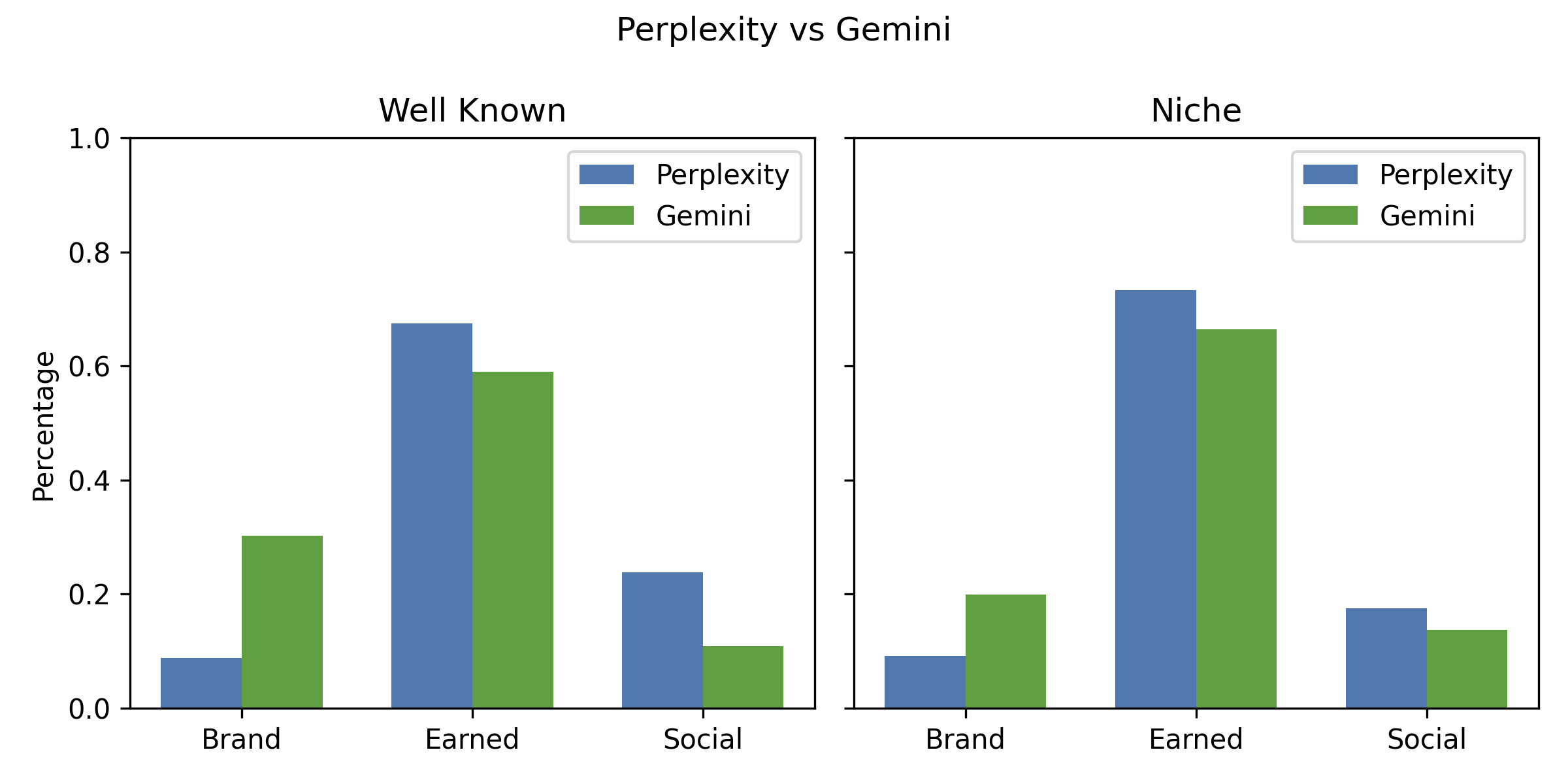
Figure 23: Comparison of Perplexity vs.~Gemini for well-known and niche brands.
Big brand bias is pronounced: unbranded queries overwhelmingly surface major brands, with niche/indie brands rarely appearing unless explicitly prompted.
Strategic GEO Agenda: Actionable Guidance for Practitioners
The empirical findings motivate a set of strategic imperatives for Generative Engine Optimization:
- Engineer for Machine Scannability and Justification: Structure content with explicit, machine-readable justifications (comparison tables, pros/cons, schema markup) to facilitate extraction and synthesis by AI agents.
- Dominate Earned Media: Invest in public relations, expert collaborations, and link-building to secure coverage in authoritative third-party domains, as these are the primary evidence sources for AI engines.
- Adopt Engine- and Language-Specific Strategies: Tailor GEO tactics to the sourcing and localization behaviors of each engine; for GPT/Perplexity, prioritize local-language earned media, while for Claude, focus on global English-language authority.
- Overcome Big Brand Bias for Niche Players: Niche brands must over-invest in deep expert content and targeted earned media campaigns in specialty publications to break through the default preference for market leaders.
- Comprehensive Lifecycle Content: Address the entire customer journey, including post-purchase and support content, to maintain persistent AI visibility.
Implications and Future Directions
The transition from SEO to GEO is not a matter of incremental adjustment but a fundamental reorientation. The low overlap and high fragmentation across engines, the dominance of earned media, and the engine-dependent localization all point to a highly dynamic and competitive evidence ecosystem. Practically, this necessitates continuous, engine-specific competitive intelligence, a structured content and authority-building framework, and a metrics-driven execution platform.
Theoretically, these findings raise important questions about the epistemology of AI search: the mechanisms by which LLMs and retrieval-augmented systems construct authority, the potential for systemic bias, and the implications for information diversity and market competition. The observed misalignment between human and model judgments of credibility, as well as the vulnerability to strategic manipulation, underscore the need for ongoing research into alignment, interpretability, and robustness in generative search.
Conclusion
This paper provides the first large-scale, empirical foundation for Generative Engine Optimization, demonstrating that traditional SEO is insufficient for AI search dominance. The systematic bias toward earned media, low overlap with Google, and high engine-dependent fragmentation necessitate a new, principled, and continuous GEO methodology. Success in the generative search landscape will require brands and practitioners to engineer for machine agency, dominate third-party authority, and adopt nuanced, engine- and language-specific strategies. As AI search continues to evolve, ongoing empirical monitoring and methodological innovation will be essential for maintaining and defending digital visibility.